DML语句
DML操作是指对数据库中表记录的操作,主要包括表记录的插入(insert),更新(update),删除(delete)和查询(select),是开发人员日常使用最频繁的操作。
插入记录
表创建好后,就可以往里插入记录了,插入记录的基本语法如下
INSERT INTO tablename (field1,field2,.....,fieldn) VALUES (value1,value2,.....valuen);向表emp中插入记录,ename为zhangsan,hiredate为now(),sal为2000,deptno为1
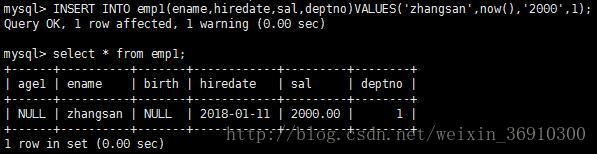
也可以不用指定字段名称,但是values后面的顺序应该和字段的排列顺序一致。如果想把其中的某个字段不设置值,需要把那个字段的名称重新填上去,那么这个字段会自动设置为NULL或者默认值或者自增的下一个数字
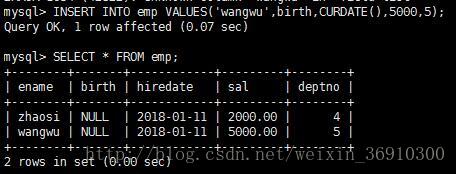
INSERT 语句还有一个很好的特性,可以一次性插入多条记录
INSERT INTO tablename (field1,field2,......,fieldn)
VALUES
(record1_value1,record1_value2,....,record1_valuesn),
(record2_value1,record2_value2,....,record2_valuesn),
(record3_value1,record3_value2,....,record3_valuesn),
......
(recordn_value1,recordn_value2,....,recordn_valuesn)
;这个特性可以使得MySQL在插入大量记录时,节省很多的网络开销,大大提高插入效率
更新记录
表里的记录值可以通过update命令进行更改,语法如下:
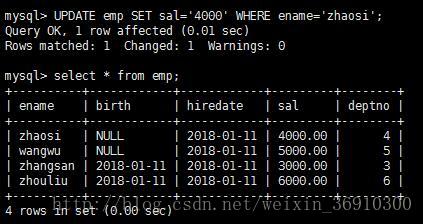
UPDATE tablename SET FIELD1=value1,field2=value2,...fieldn=valuen [WHERE CONDITION]将表emp中ename为“zhaosi”的薪水从2000改为4000
在MySQL中,update命令可以同时更新多个表中数据,语法如下:
UPDATE tablename1,tablename2,....tablenamen SET tablename1.field1=expr1,tablenamen.exprn [WHERE CONDTION];注意:多表更新的语法更多地用在根据一个表的字段来动态地更新另外一个表的字段。
删除记录
如果记录不在需要,可以用delete命令删除,语法如下
DELETE FROM tablename [WHERE CONDITION]在emp中将ename为”zhaosi”的记录删除
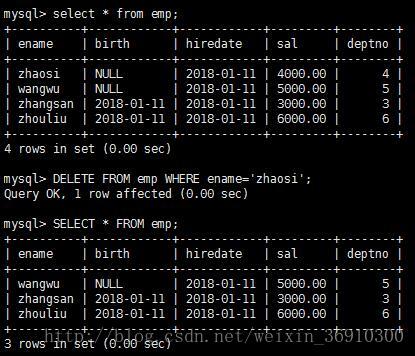
在MySQL中可以一次删除多个表的数据,语法如下
DELETE tablename1,tablename2,……,tablenamen FROM tablename1,tablename2,….,tablenamen[WHERE CONDTION]
注意:如果from后面的表名用别名,则delete后面也要用相应的别名,否则会提示语法错误。
查询记录
数据插入到数据库中后,就可以用SELECT命令进行各种各样的查询,使得输出的结果符合用户的要求。SELECT的语法很复杂,
SELECT * FROM tablename [WHERE CONDITION]其中“*”表示将所有的记录都选出来,也可以用逗号分隔的所有字段来代替,以下两个查询都是等价的
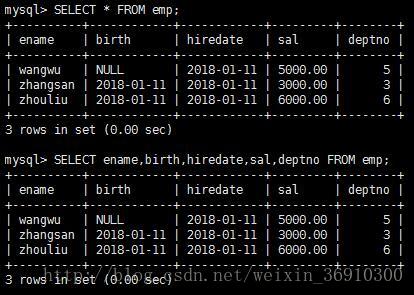
查询不重复的记录
有时需要将表中的记录去掉重复后显示出来,可以用distinct关键字来实现
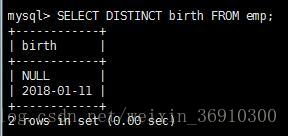
条件查询
WHERE 后面的条件可以使用 >,<,>=,<=,!=,=等比较运算符,多个条件之间还可以使用 or,and等逻辑运算符进行多条件联合查询。
下面的例子是多字段条件查询
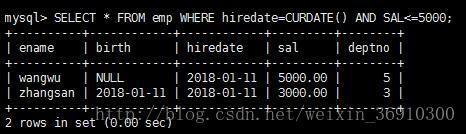
排序和限制
取出按照某个字段进行排序后的记录结果集,这就用到了数据库的排序操作,用关键字ORDER BY 来实现
SELECT * FROM tablename [WHERE CONDITION] [ORDER BY field1 [DESCASC],field2 [DESCASC],...,fieldn[DESCASC]]DESC和ASC是排序顺序关键字,DESC表示按照字段进行降序排序,ASC则表示升序排列,如果不写此关键字默认是升序排序。RODER BY后面可以跟多个不同的排序字段,并且每个排序字段可以用不用的排序顺序。
如果排序字段的值一样,则值相同的字段按照第二个排序字段进行排序,依次类推。如果只有一个排序字段,则这些字段相同的记录将会无序排序。
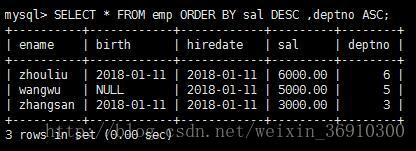
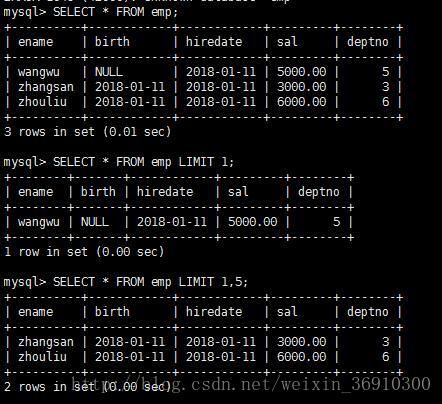
如果希望显示一部分数据,而不是全部,可以使用LIMIT关键字来实现,LIMIT语法如下
SELECT...[LIMIT offset_start,row_count]其实offset代表的意思是记录的其实偏移量(self:从第一行开始),row_count代表显示的行数(self:一共显示几条记录)
未填写offset_start默认为0,只需要填写显示的行数即可,实际显示的就是前n条记录
聚合
很多情况下,用户都需要进行一些汇总操作,比如统计整个公司的人数或者统计每个部门的人数,这时就要用到SQL的聚合操作。
聚合操作的语法如下:
SELECT [field,field2,....,fieldn] fun_name
FROM tablename
[WHERE where_contition]
[GROUP BY field1,field2,...,fieldn
[WITH ROLLUP]]
[HAVING where_contition]
]参数说明
1.
- fun_name 表示要做的聚合操作,也就是聚合函数,常用的有sum(求和),count(*)记录数,max(最大值),min(最小值)。
- GROUP BY关键字表示要进行分类聚合的字段,比如要按照部门分类统计员工数量,部门就应该写在group by后面
- WITH ROLLUP是可选语法,表明 是否对分类聚合后的结果进行再汇总
- HAVING关键字表示对分类后的结果再进行条件的过滤
注意:having和where的区别在于,having是对聚合后的结果进行条件的过滤,而where是在聚合前就对记录进行了过滤,如果逻辑允许,我们尽可能用where先过滤记录,这样因为结果集减小,将对聚合的效率大大提高,最后再根据逻辑看是否用having进行过滤。
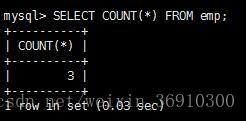
例子:统计emp表中的总人数
统计各个部门的人数
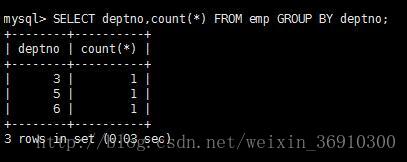
统计各个部门的人数,又要统计总人数
![这里写图片描述]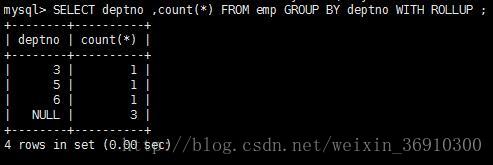
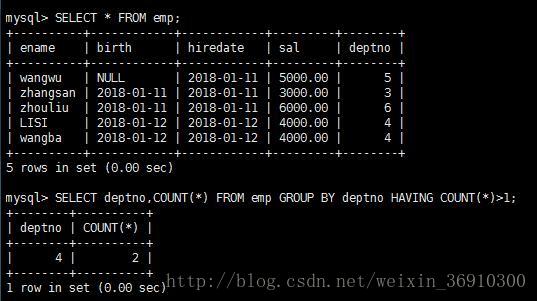
统计人数大于1人的部门
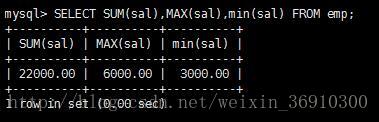
统计所有员工的薪水总额,最高和最低薪水