How much position information do convolutional neural network encode?
Intro
文章是ICML2020的一个工作,探究了CNN到底有没有编码位置信息,这些位置信息在哪些神经元中被编码、这些位置信息又是如何被暴露给神经网络学习的。文章通过大量实验表明,CNN不仅可以编码位置信息,而且越深的层所包含的位置信息越多(而往往越深的层解释性越差,浅层学习到的形状、边缘等比较容易解释),而位置信息是通过zero-padding透露的,显然,图像边缘的zero-padding暗示了图像的边界,这就让具有平移不变性的神经网络不仅能利用不变性对一张图中不同位置的物体进行分类,还能利用zero-padding带来的位置信息,编码物体所在图像中的位置,而这一点在显著性目标检测和语义分割等任务中是非常有用的。
Position information in CNNs
首先通过下面一张图说明问题是怎么来的:

上图是三组显显著性区域的heatmap可视化结果,在每一组实验中,如果给定左边的图,显著性区域是偏中间的,而把图片右边crop掉(每组的右边的图),发现显著性区域有了变换,shift到了对应crop图的中心。
显著性区域一般都是在图像中间的,所以可以简单得出一个结论,CNN学习到了哪里是输入图像的中间,所以将显著性区域的预测结果向中间shift。
那么问题来了,CNN是如何学习到位置信息的呢?
Position Encoding Module
为了探究CNN对位置信息的编码,文章将backbone提取的特征输入到一个结构中,利用这个结构来预测位置信息。
以VGG为例,作者分别提取VGG的五层特征,插值到同一size后concat起来,然后接几层卷积结构,映射到一张能表示位置信息的gt,gt一会说。整个网络结构称为PosENet,其中backbone可以为任意特征提取的网络,甚至可以没有。大致的结构如图所示:
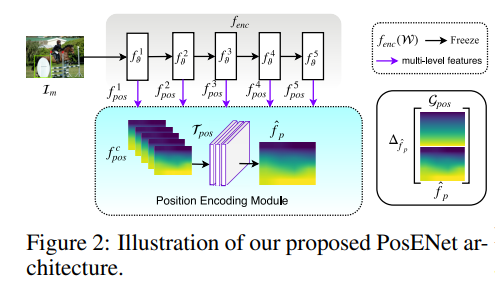
对于gt,是作者生成的gradient-like mask。注意这个like,就是梯度形状的图片,这里不是指back propagation回传的梯度,就理解为图像梯度就行。
具体定义了水平方向梯度形状、竖直方向梯度形状、高斯形状、水平方向两条杠形状的和竖直方向两条杠形状的。
具体的直接看下图:

这些图像作为gt是因为他们是和输入图像同size的,所以每个map值都对应了一个位置,为了方便可视化才这样的。因此,这些图可以作为随机label,如果CNN并没有编码位置信息,那么想要映射到这样的图是不可能的,因为输入的图片和label是完全不相关的(除非输入的图像包含了位置信息)。这里虽然和后面padding的实验无关,但是可以想象,如果没有zero-padding,就没有边界暗示,相当于不知道坐标原点,因此想要映射到这样图是不可能的。
此外,作为输入的图像不仅有一般数据集中的自然图像,还有纯黑图像、纯白图像、噪声图像等等。
对此,作者做了如图所示的实验:

其中最左边一列是输入,第二列是GT,第三列是直接没有backbone接position encoding module,第四列用VGG backbone,第五列resnet backbone。其中backbone的参数都冻结,position encoding module都不padding。
第三列表明没有backbone的pretrain权重,网络无法通过输入直接映射到gt(这是显然,之后作者还做了给padding的,给了padding就可以接近gt了),第四、五列说明了pretrain的网络输出的特征中编码了位置信息,这帮助了后面接的position encoding module预测到gt。
随后作者探究了position encoding module层数对结果影响的实验,结论是:层数越多结果越好,因为感受野更大了,利用到了更多位置信息编码后的神经元。
接着探究了position encoding module的kernel size对结果影响,结论是:kernel size越大结果越好,原因同上,感受野更大了。
Where is the position information stored?
还有一个问题当看到那个网络结构的时候我就在想,作者有没有探究到底是哪些层的feature包含位置信息,如果都包含,哪些包含的更多呢?看到后面看到作者也对此做了实验。
实验过程就是对VGG网络,如果只拿第一层特征映射到gt会怎样,只拿第二层会怎样,以此类推,然后评估mae和斯皮尔曼相关系数即可。
结论是,越深层的特征,其包含的位置信息更多,为了防止是神经元数量对结果造成的影响,作者把f4和f5的神经元数量设置成一样的,然后实验结果仍然是越深的位置信息越多。(由于网路越深,感受野越大,再次印证上面两个实验的结论)。
Where does position information come from
最后一个问题就是这些位置信息是从哪里学习到的呢?很容易就能想到是zero-padding为图像提供了一层暗示,暗示了图像的边界。
于是可以做个简单的实验验证。

每张图对应描述如图所示,可以看出来随着pad数增加,可视化结果越接近gt。
在更多的实验中,作者验证了显著性检测和语义分割使用zero-padding和不适用zero-padding,结果表明用了zero-padding的在结果上更加优秀。
在不需要图像位置的任务中作者并没有做相关实验,位置信息对于一个输入只喊目标的分类问题也许没有太大的帮助,知识添加了额外的无关信息,相当于添加噪声,因此我感觉,如果是需要用到位置信息的任务,最好使用zero-padding,这显然会使结果更好。