Noise2Noise: Learning Image Restoration without Clean Data
Intro
本文亮点是输入图像和target图像都是有噪声的图像,而不是clean的图像,网络可以利用有噪声的图像学习到将有噪声的图像转化为无噪声的clean图像。文章解释了在使用l2 loss时,网络对于一对多的映射关系学习到的是映射值的均值,基于此idea,将clean的图像加上0均值的噪声作为target,数据量足够多时,网络就能学习到预测clean图;作者也探究了使用l1 loss的影响,即利用l1 loss的稀疏性,事先如果知道噪声的分布,且该分布下图片中的像素为噪声的概率较低时,使用l1 loss要优于l2 loss,其他情况根据噪声分布的实际情况设计相应的loss。

Theoretical Background
在高分辨率算法中,由低分辨率到高分辨率图的对应是一对多的,也就是说,一张低分辨率图是可以对应多张高分辨率图的,网络直接使用l2 loss去回归高分辨率的结果,实际上会倾向于回归可能对应的高分辨率图像的均值,因此预测的高分辨率图会倾向于模糊。
也就是说,对于任务$$mathop{argmin}_z mathbb{E}_y{L(z,y)}$$,其最小值在(z = mathbb{E}{y})取得。
同样地,L1 loss取得最小值时在target的中位数处取得。
这样的一对多的回归任务用神经网络拟合可以写成:
由于一张图对应对个target,所以上式优化时同时对x、y两个变量优化。
如果输入变量x之间相互独立,那么上式又可写成:
可见优化过程可以分成两步优化。这有什么好处呢?如果一张图对应的target足够多,并且target的噪声满足0均值分布,那么(y|x)的优化结果理应就是clean的target,然后再对每张输入图片进行第二步优化。
用公式表达就是:
上式(y_i)表示clean data,只要近似满足噪声是0均值分布的,优化的结果就可以将噪声均值化从而达到去噪的目的。
Practical Examples
本文还列举了很多去噪的例子,我仅看了几个感兴趣的。
- Additive Gaussian Noise: 满足0均值特性,按照上文说的方式进行优化,发现也可以SOTA。
- 去除弹幕(暂且这么叫),主要看了一下这个。
- MRI图像恢复。
对于1,不再阐述。
对于2,文章随机对图片添加文字,保证图片每个像素被污染的概率为[0,0.5]区间范围内,而在测试时,污染概率采用的是约为0.25来进行测试。结果如图所示:

可以看到,L2 loss要差于L1 loss,这是因为事先已知噪声的分布特性,即每个点是噪声的概率在[0,0.5]之间,因此网路理应更倾向于认为预测的像素点不是噪声,这刚好与L1 loss的稀疏特性是对应的,由于L1 loss具有稀疏性,所以其预测的结果中0会偏多,也就是网络会更相信要拟合的target就是clean target,这刚好是符合噪点概率分布特点的,因此L1 loss是优于L2 loss的。还有一点,由于噪声不一定是0均值的,使用L2 loss的话,网络的预测结果就是clean data和噪声均值的线性和,这会导致输出图片的颜色整体看起来怪怪的,而使用L1 loss就更相信原图,相当于减弱了噪声对loss的影响。
对于3,文章中还说到了可以本文的方法可以帮助MRI图像的重建。
MRI图像重建常规的方法是在k空间中周期性采样然后重建原图(因为频域空间是连续的而图像空间是离散的),但是需要满足奈奎斯特采样定律,因此采样频率必须比较高;然后就是利用压缩感知(cs)重建图像,压缩感知技术是在k空间中随机采样,而不是周期采样,因而可以不必满足奈奎斯特采样定律,甚至可以以更少的采样点恢复原图。本文将在k空间的采样过程看成是概率分布一定的伯努利过程的随机采样,然后将采样后的信号通过傅里叶反变换恢复原图、其中,k空间内每个点保留的概率为(p(k) = e^{-|k|}),如图,a是d经过采样后重建的图像,其只保留了10%的信号频率。那么我们训练的时候,就有两种选择,一种是拿采样合适的clean图作为target取学习,还有一种就是拿同样只保留10%信号频率后重建的图作为target,而前者就对应了一般的高分辨率算法,后者对应本文的方法。
因此,loss定义为:
其中F是傅里叶变换,R是对频谱图加上一常数,防止有0值出现,因为在傅里叶反变换的时候可能会除以0值导致溢出。
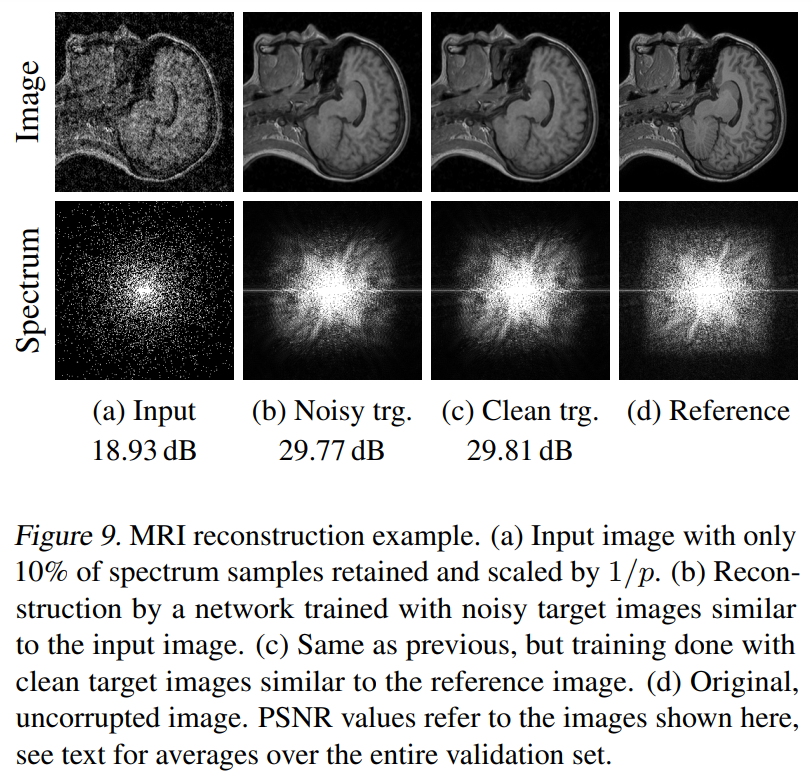
由图可见,使用伯努利采样训练的denoise结果和使用原本clean的样本训练的结果是差不多的。