1 描述性统计是什么?
描述性统计是借助图表或者总结性的数值来描述数据的统计手段。数据挖掘工作的数据分析阶段,我们可借助描述性统计来描绘或总结数据的基本情况,一来可以梳理自己的思维,二来可以更好地向他人展示数据分析结果。数值分析的过程中,我们往往要计算出数据的统计特征,用来做科学计算的NumPy和SciPy工具可以满足我们的需求。Matpotlob工具可用来绘制图,满足图分析的需求。
2 使用NumPy和SciPy进行数值分析
2.1 基本概念
与Python中原生的List类型不同,Numpy中用ndarray类型来描述一组数据:
from numpy import array from numpy.random import normal, randint #使用List来创造一组数据 data = [1, 2, 3] #使用ndarray来创造一组数据 data = array([1, 2, 3]) #创造一组服从正态分布的定量数据 data = normal(0, 10, size=10) #创造一组服从均匀分布的定性数据 data = randint(0, 10, size=10)
2.2 中心位置(均值、中位数、众数)
数据的中心位置是我们最容易想到的数据特征。借由中心位置,我们可以知道数据的一个平均情况,如果要对新数据进行预测,那么平均情况是非常直观地选择。数据的中心位置可分为均值(Mean),中位数(Median),众数(Mode)。其中均值和中位数用于定量的数据,众数用于定性的数据。
对于定量数据(Data)来说,均值是总和除以总量(N),中位数是数值大小位于中间(奇偶总量处理不同)的值:

均值相对中位数来说,包含的信息量更大,但是容易受异常的影响。使用NumPy计算均值与中位数:
from numpy import mean, median
#计算均值
mean(data)
#计算中位数
median(data)
对于定性数据来说,众数是出现次数最多的值,使用SciPy计算众数:
from scipy.stats import mode
#计算众数
mode(data)
2.3 发散程度(极差、方差、标准差、变异系数)
对数据的中心位置有所了解以后,一般我们会想要知道数据以中心位置为标准有多发散。如果以中心位置来预测新数据,
那么发散程度决定了预测的准确性。数据的发散程度可用极差(PTP)、方差(Variance)、标准差(STD)、变异系数(CV)来衡量,它们的计算方法如下:
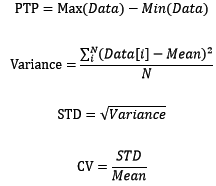
1 from numpy import mean, ptp, var, std 2 3 #极差 4 ptp(data) 5 #方差 6 var(data) 7 #标准差 8 std(data) 9 #变异系数 10 mean(data) / std(data)
2.4 偏差程度(z-分数)
之前提到均值容易受异常值影响,那么如何衡量偏差,偏差到多少算异常是两个必须要解决的问题。定义z-分数(Z-Score)为测量值距均值相差的标准差数目:
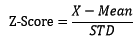
当标准差不为0且不为较接近于0的数时,z-分数是有意义的,使用NumPy计算z-分数:
1 from numpy import mean, std
2
3 #计算第一个值的z-分数
4 (data[0]-mean(data)) / std(data)
通常来说,z-分数的绝对值大于3将视为异常。
2.5 相关程度
有两组数据时,我们关心这两组数据是否相关,相关程度有多少。用协方差(COV)和相关系数(CORRCOEF)来衡量相关程度:
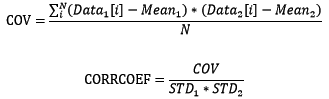
协方差的绝对值越大表示相关程度越大,协方差为正值表示正相关,负值为负相关,0为不相关。相关系数是基于协方差但进行了无量纲处理。使用NumPy计算协方差和相关系数:
from numpy import array, cov, corrcoef
data = array([data1, data2])
#计算两组数的协方差
#参数bias=1表示结果需要除以N,否则只计算了分子部分
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的协方差。对角线为方差
cov(data, bias=1)
#计算两组数的相关系数
#返回结果为矩阵,第i行第j列的数据表示第i组数与第j组数的相关系数。对角线为1
corrcoef(data)
2.6 回顾
| 包 | 方法 | 说明 |
| numpy | array | 创造一组数 |
| numpy.random | normal | 创造一组服从正态分布的定量数 |
| numpy.random | randint | 创造一组服从均匀分布的定性数 |
| numpy | mean | 计算均值 |
| numpy | median | 计算中位数 |
| scipy.stats | mode | 计算众数 |
| numpy | ptp | 计算极差 |
| numpy | var | 计算方差 |
| numpy | std | 计算标准差 |
| numpy | cov | 计算协方差 |
| numpy | corrcoef | 计算相关系数 |