一、有了B树,为啥还有B+、B*树?
B+树
B+树是B-树的变体,也是一种多路搜索树:
- 其定义基本与B-树同,除了:
- 非叶子结点的子树指针与关键字个数相同;
- 非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树(B-树是开区间);
- 为所有叶子结点增加一个链指针;
- 所有关键字都在叶子结点出现;
如:(M=3)
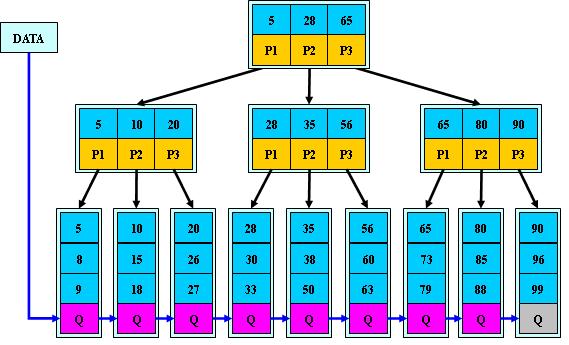
B+的搜索与B-树也基本相同,区别是B+树只有达到叶子结点才命中(B-树可以在非叶子结点命中),其性能也等价于在关键字全集做一次二分查找。
B*树
B*-tree是B+-tree的变体,在B+树的基础上(所有的叶子结点中包含了全部关键字的信息,及指向含有这些关键字记录的指针),B*树中非根和非叶子结点再增加指向兄弟的指针。

B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
二、特性
B+树的特性:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
B*树的特性:
- B*树分配新结点的概率比B+树要低,空间使用率更高;
三、用途
B/B+树通过对每个节点存储个数的扩展,使得对连续的数据能够进行较快的定位和访问,能够有效减少查找时间,提高存储的空间局部性从而减少IO操作。他广泛用于文件系统及数据库中,如:
- Windows:HPFS文件系统
- Mac:HFS,HFS+文件系统
- Linux:ResiserFS,XFS,Ext3FS,JFS文件系统
- 数据库:ORACLE,MYSQL,SQLSERVER等中
根据B+树的结构,我们可以发现B+树相比于B树,在文件系统,数据库系统当中,更有优势,原因如下:
1、B+树的磁盘读写代价更低
B+树的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说I/O读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
2、B+树的查询效率更加稳定
由于内部结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
2、B+树更有利于对数据库的扫描
B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题,而B+树只需要遍历叶子节点就可以解决对全部关键字信息的扫描,所以对于数据库中频繁使用的range query,B+树有着更高的性能。
四、MySQL的B-Tree索引(技术上说B+Tree)
在 MySQL 中,主要有四种类型的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。我们主要分析B-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
五、总结
- 二叉搜索树:二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
- B-树:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;
- 所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;
- B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
- B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
参考资料:
- https://blog.csdn.net/v_JULY_v/article/details/6530142
- https://www.cnblogs.com/xiohao/p/9103271.html
- https://blog.csdn.net/qq_22613757/article/details/81218741
- https://blog.csdn.net/yishizuofei/article/details/81660841
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!
