上一节讨论的是字符编码的一些基本概念,本节我们继续这个话题。在开发程序时,可以说每时每刻都在跟字符串打交道,因此难免会遇到字符编码的问题。而问题往往发生在程序需要发送或接收字符串时。因为在程序内部进行字符串处理时通常使用的是统一的编码方式,不经常涉及编码转换。这就像两个本地人使用同一种语言聊天,互相肯定都能听懂;但如果程序需要与外部进行字符串的通信时,例如向磁盘文件读取或写入文本,或将程序从网络中接收到的数据流(字节流)解析为字符串,此时必须正确地设置编码方式,否则就会产生乱码——这就像正在谈话的两个人一个说中文而另一个说日语一样,很可能会造成无法沟通和误解。
现实中的情况
我们以现实中的两个人正在通过语言进行交流,来说明编码转换的基本概念:
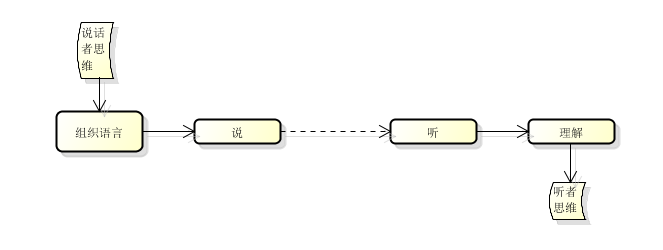
假设两个人A和B正在进行对话,他们是初次见面,两人先用蹩脚的英语进行了简单交流。考虑下面的情况:
1. A(用英语)对B说他讲韩语,B是日本人,听不懂韩语
2. A对B说他讲韩语,B能听懂韩语
3. A对B说他讲日语,但一开口说的却是韩语
4. A上来就对着B滔滔不绝地说,B需要根据听到的来猜测A说的是什么语言
5. A上来就对着B滔滔不绝地说,B直接将A说的当日语来理解
可以预见,对于情况2,A和B能够正常交流;1和3无法正常交流;最后两种则不一定,需要碰运气。
程序中的情况
当字符编码或字符流由一个对象传输/复制到另一个对象时,就会涉及到编码的发送、接收与转换。例如:
- 两个应用程序通过网络发送和接收字符串
- 两个应用程序通过内存进行字符串的通信
- 应用程序读取文件或流中的内容
- 应用程序向文件或流中写入内容
此过程中任何一处发生错误,都可能导致乱码。如下图所示:
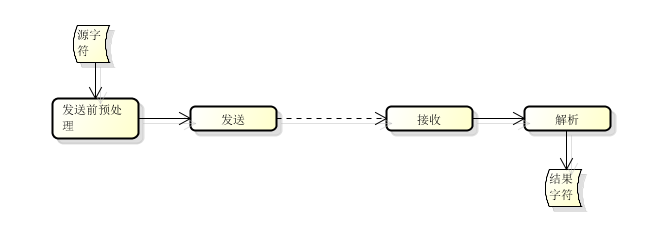
对比前面的图,是不是非常相似?
一、 网页中的编码
我们知道,在网页中可以通过下面的元标签来告知浏览器,本页面所采用的编码是什么,例如页面采用UTF-8编码时可以这样写:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
这里声明的编码必须与页面实际编码一致,否则就会导致乱码。你可以打开任何一个网页,通过查看源文件来看看它采用的是什么编码,然后通过浏览器上的查看菜单给它指定一个不同的编码,乱码就出现了。
但是这里还有一些细节不得不考虑。
Q:如何确定页面的实际编码?
A:对于静态页面,即在Web服务器上以一个普通文件存在的页面(通常具有.htm或.html的后缀名),它的实际编码就是保存文件时所选择的编码;对于动态页面,例如通过Java Servlet所生成的页面,实际上是Servlet生成的字符流,其编码由Web容器或在Servlet中指定。
Q:当页面的实际编码与<meta>中声称的编码不一致时,一定会导致乱码吗?
A:不一定。如果声称的编码是实际编码的一个超集,那么就不会发生乱码。例如GBK就是GB2312的超集(GB的意思是“国标”,GBK的意思是“国标扩展”)。而几乎所有编码都是ASCII的超集,所以如果你的页面是纯英文的,那么不管采用哪种编码来显示,大多情况下都不会乱码。
Q:当页面的实际编码与<meta>中声称的编码一致时,一定不会导致乱码吗?
A:答案还是“不一定”。如果用户的系统无法识别页面所使用的编码,还是会导致乱码。早期老系统中(如早期的DOS)只能识别包括ASCII在内的少数几种编码,当显示汉字时就会产生乱码,所以那时候国人开发了很多外挂汉字字库,用来在DOS中显示汉字。
另外,如果网页中指定的字体在用户系统中没有,也可能会导致页面乱码或字符无法显示的问题。这和页面使用的编码无关,但同样会导致用户无法浏览。
二、 XML文件中的编码
可以在XML文件的第一行使用
<?xml version="1.0" encoding="utf-8"?>
来声明文件使用的编码。它与网页中的编码声明类似,因此不再赘述。
三、 Java中的字符编码
众所周知,Java支持Unicode,Java字符串都是用Unicode进行编码的(准确地说是UTF-16格式)。是不是Java程序中就不存在编码和乱码问题了呢?很遗憾,答案是否定的。
从我们编写Java源程序,然后编译,最后到将程序放到Java虚拟机中去执行,每一步都会涉及到与编码相关的问题。
1. 源程序
和其他程序一样,Java源程序也是一个文本文件,所以它本身也需要使用某种编码来存储。因此Java编译器javac提供了一个参数“-encoding”来指定源文件使用的编码。例如要指定UTF-8:
javac -encoding utf8 xxx.java
我们在编译Java程序时,通常不会考虑甚至不会注意到源文件编码的问题,这是因为我们通常都是在默认的编码下工作,并且Java编译器会自动对常用的编码进行检测。
2. class文件中的编码
Java编译生成的目标文件称为Java字节码文件,扩展名为.class。Java字节码文件是跨平台的,因此其中的字符串需要采用一种统一的编码方式,这种方式即UTF-8编码。
也就是说,无论源文件使用何种编码,编译时都会将其中的字符串转换为UTF-8进行存储。
3. 虚拟机中的字符编码
虽然Java中的字符串统一采用Unicode编码,但Java虚拟机本身是一个软件,运行时需要依赖底层的操作系统。因此JVM需要与操作系统交互,这一点和其他应用程序没有任何区别。
Java虚拟机在启动时,会首先获取操作系统的默认编码(在Windows中就是当前代码页)。当需要与操作系统进行字符相关的交互时,JVM所依据的就是这个默认编码。
例如当Java程序需要读取本地磁盘上的某个文本文件时,JVM需要调用操作系统的函数来获得文件的内容。因此JVM需要知道或能够根据其内容推测出文件所使用的编码,并将其转换为JVM的内部编码即Unicode。
当Java程序需要将字符写入文件时也是一样:JVM按照Java程序所指定的编码或操作系统默认的编码将字符从内部编码转换为目标编码,然后调用操作系统函数将转换后的字符写入文件。
4. java程序执行时
Java中的字符串统一采用Unicode编码,但在通过字节数组创建字符串时,或将字符串转换为字节数组时,仍然要指定所使用的字符编码。
下面是String类的几个构造方法和方法:
String(byte[] bytes)
使用平台的默认字符集解码指定的字节数组构造一个字符串
String(byte[] bytes, String charsetName)
使用指定的字符集解码指定的字节数组构造一个字符串
byte[] getBytes()
使用平台的默认字符集将此字符串编码为字节数组
byte[] getBytes(String charsetName)
使用指定的字符集将此字符串编码为字节数组
前两个是构造方法,通过字节数组和某种字符编码来构造Java字符串;后面两个恰好相反,将Java字符串转换为某种字符编码的字节序列。
另外,在与字符流相关的类或接口中,也必然能见到字符编码的踪影。例如InputStreamReader和OutputStreamWriter,这两个类是很多其他类能够得以工作的基础*注,要创建它们的实例,必须指定一种字符编码(与String一样,它们也提供了默认的构造方法以使用系统的默认编码)。例如:
InputStreamReader(InputStream in, String charsetName)
和
OutputStreamWriter(OutputStream out, String charsetName)
*注:Java的IO相关的类通过一种“包装”而不是继承的方式来组织,一个类通过包装其他类来扩展被包装的类。例如InputStreamReader中没有对接收到的字节进行缓冲,因此将其包装到BufferedReader中就可以获得缓冲所带来的益处。
综上所述,Java虽然是跨平台的,并且原生支持Unicode,但仍然有很多地方需要涉及到字符编码与编码转换。如下图所示。

四、 Windows、Linux中字符编码相关概念和函数
TODO
五、总结
在任何涉及到字符的传输的情况下,都要注意字符的编码问题,因为字符由此处发送到彼处时,总是会发生显式或隐式的转换,因此稍不小心就会出错而出现乱码的情况。