深度学习中需要大量的数据和计算资源(乞丐版都需要12G显存的GPU - -)且需花费大量时间来训练模型,但在实际中难以满足这些需求,而使用迁移学习则能有效
降低数据量、计算量和计算时间,并能定制在新场景的业务需求,可谓一大利器。
迁移学习不是一种算法而是一种机器学习思想,应用到深度学习就是微调(Fine-tune)。通过修改预训练网络模型结构(如修改样本类别输出个数),选择性载入预训练网络模型权重(通常是载入除最后的全连接层的之前所有层 ,也叫瓶颈层)
再用自己的数据集重新训练模型就是微调的基本步骤。 微调能够快速训练好一个模型,用相对较小的数据量,还能达到不错的结果。
微调的具体方法和技巧有很多种,这里总结了在不同场景下的微调技巧:
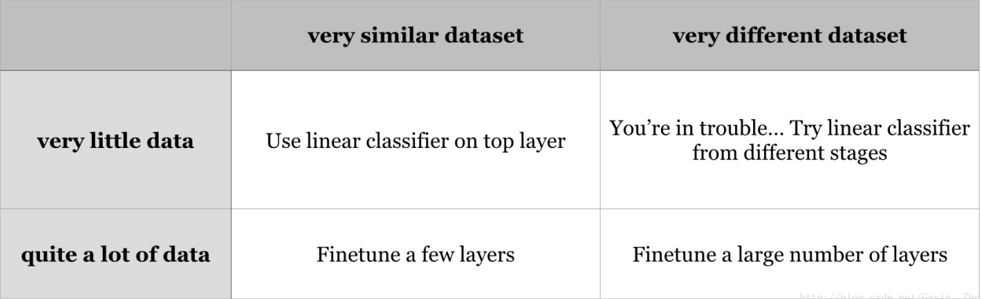
1)新数据集比较小且和原数据集相似。因为新数据集比较小(比如<5000),如果fine-tune可能会过拟合;又因为新旧数据集类似,我们期望他们高层特征类似,可以使用预训练网络当做特征提取器,用提取的特征训练线性分类器。
2)新数据集大且和原数据集相似。因为新数据集足够大(比如>10000),可以fine-tune整个网络。
3)新数据集小且和原数据集不相似。新数据集小,最好不要fine-tune,和原数据集不类似,最好也不使用高层特征。这时可是使用前面层的特征来训练SVM分类器。
4)新数据集大且和原数据集不相似。因为新数据集足够大,可以重新训练。但是实践中fine-tune预训练模型还是有益的。新数据集足够大,可以fine-tine整个网络。
fine-tune实践建议:
1)预训练模型的限制。使用预训练模型,受限于其网络架构。例如,不能随意从预训练模型取出卷积层。但是因为参数共享,可以输入任意大小的图像;卷积层和池化层对输入数据大小没有要求;全连接层对输入大小没有要求,输出大小固定。
2)学习率。与重新训练相比,fine-tune要使用更小的学习率。因为训练好的网络模型权重已经平滑,我们不希望太快扭曲(distort)它们(尤其是当随机初始化线性分类器来分类预训练模型提取的特征时)。