5.1简介
在本章中我们研究的几个可以归为一类的问题--选择,找出一个集合的中间元素是其最经典的例子,除了找到一个高效的算法来解决这个问题,我们还需要找出这个问题的下界。在这里我们介绍一个广泛应用的技术----对策论来建立下界。
5.1.1选择问题
假设有n个元素的数组E,其关键字线性排列,而且,设整型k,1≤k≤n,选择问题就是找出数组E中最小的k个元素,这些元素被排序了k个.就像大多数我们研究过的排序算法一样。我们假设在这些关键字上进行的唯一操作就是一对一对的比较(并复制或者移动)。本章关键字和元素将被认为是唯一的,因为我们的关注点在元素的比较,而且我们也不关注元素的移动,还有,当元素存储在数组时,我们将从1,……n使用位置,来协同惯用的排序术语,而不是从0,……n-1,0这个位置一般不用。
在第一章我们解决了当k=n时的选择问题,那个问题就仅仅是找出最大值,我们想到一种做n-1次比较的简单算法,而且我们也已经证明了没有比这个算法比较次数更少的了,当k=1是,即找到最小元素也可以相似的方法解决。
另一个非常普通的选择问题的例子就是当k=n/2的上界,我们想找到中间的值或者中值。中值对说明一个非常大的数据集合很有用,例如一个特定国家所有人的收入,或者一个特定的职业,房价,或者大学入学测试的成绩。来代替包含所有数据的集合,新闻报道,例如:通过给定的平均值或者中值来总结概括,时间复杂度为O(n)计算n个数据的平均值很简单,那我们怎么能高效的计算中间值?
当然,所有选择问题的例子都可以通过对E排序解决;那么我们感兴趣的是那有序的k个元素,E[k]就是我们想要的答案,需要O(nlogn)次比较,而且我们已经观察的仅仅是k个值,选择问题可以在线性时间里解决,直观地,找出中间值似乎是选择问题最难的例子。我们能不能再线性时间内找到中间值?或者我们为中间值找到一个比线性时间大的下界,也许是O(nlogn)?我们将在本章中回答这些问题,并且我们将为一般的选择问题勾画出一个算法。
5.1.2下界
至此我们已经使用了决策树作为我们主要的技术来建立我们的下界,决策树的内部节点为一个算法执行时的比较次数,叶子节点代表输出(第1.6节查找树,内部节点也代表输出),比较次数的最坏情况是树的高度;高度最小是lgL,在这里L是叶子的数目。
在1.6节我们用决策树为查找问题求得最坏情况下界lg(n+1),通过二叉树只是比较的很准确的次数,所以决策树论证给了我们最大可能的下界,在第四章,我们用决策树得到下界lgn!,或者粗略(nlgn-1.5n)
,对于排序有些算法的执行非常接近下界,所以决策树再次给出了一个有力的结果,然而决策树对选择问题却没那么好用。
选择问题的决策树必须至少有n个叶子,因为在n个元素的集合里的任何一个元素都可能是输出,也就是k个最小的,因此我们可以得到结论树的高度最小为lgn,但是这不是一个好的下界,我们已经知道了即使找到最大元素的最好情况就是比较n-1次,那决策树论证怎么了???在一棵找到最大值的决策树,一些输出出现的不止一个叶子节点,而且事实上将多于n个节点,看这里,练习5.1,当n=4时为找到最大值画一棵决策树,决策树论证没有给出一个好的下界,因为我们没有一个简单的方法来决定一个特定的输出将包含多少个叶子副本。
取代决策树,我们用的技术成为对策论来为选择问题建立一个更好的下界,下面将描述该技术。
5.1.3对策论
假设你和朋友在玩一个猜谜游戏,已选择一个日期(月日),这个朋友将通过问你是/否问题来猜,你希望你的朋友问得问题越多越好,如果第一个问题是“是不是在冬天?”而且,你是一个好的对手,你将回答“不是”,因为在其他三个季节会有更多的日期,对这个问题,“这个月的第一个字母是否在字母表的前半部”你应该回答是,但这是不是作弊呢?你根本就没有选择一个日期!事实上,你不用选择一个特定的日期直到为了和你的回答一直才敲定这个日期。这也许不是一个友好的玩游戏的方法,但是它却恰恰是能找到一个算法执行的的下界。
假设我们有一个我们认为高效的算法,想象一个要证明恰恰相反的对手,在算法每一个做决定的点,对手都告诉我们决定的结果,这个对手选择它的答案使我们的算法执行效率不高,,也就是做大量的决定。你也可以认为对手当它回答问题时在逐渐为算法构造“最坏”的输入,对对手的答案的唯一限制是必须内部一致,必须是有正确回答的问题的一些输入,如果对手可以使算法执行f(n)步,那么f(n)就是最坏情况下执行步数的下界,通过练习5.2归并排序得到该方法。
事实上,“设计对手”经常是有效解决基于排序问题的很好的技术,在一个给定的条件下考虑比较什么,假想对手将给出最不好的答案---那么选择一个比较使两个输出都大致一样好,该技术将在5.6节给出更详细的讨论,然而,我们主要感兴趣的是在下界讨论中对策论这一角色。
我们将找出一个复杂问题的下界,不仅仅是一个特定的算法,当我们使用对策论的时候,我们将假设该算法是任意一个算法,无论任何我们研究过的算法,我们仅仅是对决策树的论证,为了得到一个很好的下界,我们需要构造一个聪明的对手,以便可以挫败任何算法。
5.1.4 锦标赛
在本章的余下部分,我们将展示在集中情况下为选择问题和对策论找下界的算法,包括中间值,在大多数的算法和论证中,我们将使用竞赛或者锦标赛,来描述每一次比较的比较数结果,比较数较大的我们将称之为“胜方”,另一方将成为“败者”。
5.2 找最大和最小值
在本节中我们用max和min来表示该集合的最大值和最小值,然后算法1.3在余下的n-1个元素中用一个适当的变量来找最小值,因此最大和最小需要(n-1)+(n-2)或者2n-3比较,这是没有优化的,尽管我们从第一章中知道最大值和最小值分开找都需要n-1次比较,,当要一起找它们两个时,一些操作是可以“共用”的练习1.25一个算法在找最大和最小值时只需比较大约3n/2次,一个解决方案是成对的元素做n/2次比较,然后找到胜者的最大值,和分开的“败者”的最小值,如果n是奇数,最后的元素将不得不在“胜者”和“败者”之间考虑,不管在那种情况,比较的总次数是(3n/2)-2.在本节中,我们给出一个对策论来展示该解决方案是优化的,具体地,本节剩余部分我们将给予证明:
定理5.1 任何一个通过元素比较寻找最大和最小值的算法在最坏情况下至少要做(3n/2)-2次比较
证明:为了求下界,我们假设关键字均唯一,设x是最大值,y是最小值,一个算法一定知道其他每个元素与x相比较的元素都会失败,而且其他每个元素与y相比较都会成功,如果我们把每一对赢和输作为一个信息元,那么每个算法一定至少有2n-2个信息元来保证得到正确的答案,我们将给出一个策略来应对对手的回应,因此每次比较要给出尽可能少的信息元,假设对手构造了一个特定的输入集合,来回应该算法的比较。
------------------------------------------------------------------------------------------------
一个算法参加比较的x和y的状态 对手的回应 新的状态 信息元
------------------------------------------------------------------------------------------------
N , N x>y W L 2
W,N或者WL ,N x>y W,L或者WL,L 1
L,N x<y L,W 1
W,W x>y W,WL 1
L,L x>y L,WL 1
W,L或者WL,L或者W,WL 没有变化 0
WL,WL 没有变化 0
----------------------------------------------------------------------------------------------
我们称每个关键字在算法进行的任何时候的状态如下:
关键字的状态 含义
-----------------------------------------------------------------------------------------------
W 至少获胜一次并且一次也未输过
L 至少失败一次并且一次也未赢过
WL 至少失败一次成功一次
N 还未参加比较
每个W或者L都是一个信息元,一次N的状态转换没有信息元。在上面表格中描述了对策论,除了两个关键字还未参加过比较外,重点是对手可以给出最多的新的信息元的回应,如果对手遵循这个原则,我们就需要证实它的回应是和输入相一致的,然后我们需要说明对手总是强迫任何一个算法去做像它理论宣称的那样尽量多次的比较
观察在表格中的所有的情况,除了最后一个,不管一个从未失败过的元素被对手选中作为胜利者还是一个从未成功过的元素被对手选中作为失败者,考虑到第一种可能性;假设算法要x和y参加比较,对手选择x作为胜者,而且x在任何对比中从未失败过,即使如果这个值已经被对手分配给x,那么更小的值分配给了y,对手可以改变x的值来让它打败y,而且不与他之前给出的回应相矛盾。另一种情况,关键字是从未赢过的失败者,可以同样的处理,可以按需要减少关键字的值,所以对手可以构建一个输入使其与表格中对算法比较次数的回应相一致,在下面例子中给予描述
------------------------------------------------------------------------------------------------
比较 x1 x2 x3 x4 x5 x6
---------- --------- -------- ------- -------- ----------
元素 状态值 状态值 状态值 状态值 状态值 状态值
x1,x2 W 20 L 10 N * N * N * N *
x1,x5 W 20 L 5
x3,x4 W 15 L 8
x3,x6 W 15 L 12
x3,x1 WL 20 W 25
x2,x4 WL 10 L 8
x5,x6 WL 5 L 3
x6,x4 L 2 WL 3
------------------------------------------------------------------------------------------------
表格5.2 一个最值对策论的例子
例5.1利用对策论的原则构建一个输出
表格5.2的第一栏显示的是一系列被某个算法执行的比较,其余的栏显示的是被对手赋的值和状态。(用星号表示尚未分配了一个值的键)每行后的第一只包含当前比较相关的条目,注意,当x3和x1比较的时候,对手增加了x3的值,因为他想让x3获胜。后来,对手又改变了x4和x6的值,是符合其规则的。在前五次比较之后,除了x3之外,每个键都失败过一次,所以x3是最大的。在最后一次比较之后,x4是唯一一个从来没有获胜过的键,所以它是最小的,在这个例子中,算法做了8次比较;6个键最坏情况下的比较次数(有待证明)是3/2*6-2=7
为了完成定理5.1的证明,我们就不得不利用对策论的原则迫使任何算法都至少做3n/2-2次比较来得到2n-2个所需的信息元。一个算法一次比较可以得到两个信息元只有一种情况两个参加比较的元素从未进行过任何比较。假定n是偶数,一个算法对先前从未看到过两个键最多进行n/2次。所以这样他可以得到n个信息元,从其他的每次比较中他都最多可以得到1个信息元。该算法还需要n-2个信息元,他至少还需要做n-2次比较,因为要想得到信息元,他至少总共要做n/2+n-2=3n/2-2次比较。读者可以很容易检验,当n是奇数时,至少需要3n/2-3/2次比较。定理5.1的证明完毕。
5.3 寻找第二最大值
我们可以通过查找一个集合和去除最大值来找到第二最大值,然后找剩余元素中的最大值。有没有更高效的方法呢??我们可否证明某种方法是优化的,本节将回答这个问题。
5.3.1 简介
本节中我们使用max和secondLargest分别来表示最大值和次大值,为了简单的描述该问题和算法,我们假设键值都是唯一的。
次大值可以通过使用算法1.3FindMax运行两次经过2n-3次比较找到,但是这可能不是优化的。我们希望在找最大值时有些信息可以被发现,并被用到进行比较查找secondLargest中,以减少比较次数。具体地,任何一个失败于其他不是max键的键,都不可能是secondLargest。所有这些在查找max时发现的键在本集合的第二轮查找中都可以忽略。(跟踪他们的问题稍后将会考虑)。
一个只有5个元素的集合使用算法1.3,可能结果如下:
比较 胜利者
--------------------------
x1,x2 x1
x1,x3 x1
x1,x4 x4
x4,x5 x4
那么max=x4并且secondLargest是x5或者x1,因为x2和x3都败给了x1.因此在本例中仅仅需要再多比较一次就可以找到secondLargest。
这种情况有可能发生,然而,在整个集合的第一轮查找max的比较中,我们没有获取任何对查找secondLargest游泳的信息。如果max就是x1,然后其他每个键都讲被比较除了max。这是不是就意味着为了找到secondLargest最坏情况下一定需要2n-3次比较呢??不是必须得。在我们使用算法1.3的前面的讨论中,没有一种算法找到最大值可以比n-1做更少的比较,但是另外一种算法可以提供更多的信息,可以用来从第二轮的比较中去除一些键。下面描述的竞技法提供这些信息。
5.3.2 竞技法
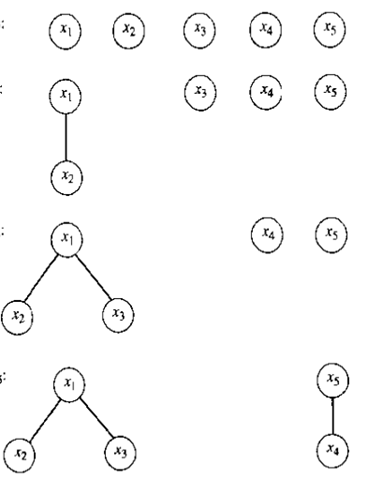
竞技法之所以这样命名是因为在比赛时他用同样的方式进行比较的,键值配对,并进行“轮”比较,第一轮以后的每一轮中,从先前轮种胜利者将再次配对再比较(在任何一轮,如果键的数目是奇数时,他们中间的一个简单地等待下一轮),竞技法可以用二叉树来描述,如图5.1,每一个叶子都包含一个元素,在其后的每一层中,每一对的双亲节点都包括着胜利者。
 图5.1 竞技法的一个例子,max=x6;secondLargest可能是x4,x5,或者x7
图5.1 竞技法的一个例子,max=x6;secondLargest可能是x4,x5,或者x7
根节点包含了最大值,就像在算法1.3中一样,进行了n-1次比较得到最大值。
在找到最大值的过程中,除了max,每一个值都失败了一次,多少次失败才到达max?如果n是2的权,确切的说需要lgn轮比较;一般而言,轮的数目是lgn的上界。因为max在每轮比较中最多一次比较,那么最多有lgn的上界个元素失败于max,那么这些键值可能就是secondLargest。那么算法1.3可以被用来在lgn的上界个键值中比较lgn-1次找到最大值,。因此竞技法寻找max和secondLargest在最坏情况下总共需要n+lgn-2次比较。这是我们第一次结果2n-3的改进。我们还能做的更好吗?
5.3.3 下界对策论
我们考虑的需找次大值,先找最大值的两种方法。没有白费,任何一种需找secondLargest的算法也都需要找到max,因为要找到次大,必须知道他不是最大;也就是,他必须在一次比较重失败过,secondLargest失败的比较的获胜者当然一定是max。这个论据就给出了找到secondLargest需要比较的下界,也就是n-1,因为我们已经知道了得到最大值需要比较n-1次,但是也希望更低的界限被提高,因为算法找到secondLargest比一个算法找打max需要做更多的工作。我们将证明下面的定理,作为一个必然结果,竞技法是最优的。
定理5.2 任何一种算法(通过比较键值工作的)在一个有n个元素的集合中找次大值在最坏情况下必须至少进行n+lgn-2次比较。
证明:最坏情况下,我们假设所有的键值都是唯一的。我们已经观察到一定有n-1次和相异失败者的比较,在这么多次比较中,如果max的比较元是lgn的上界,那么除了lgn中的一个值之外所有失败于max的值都一定失败于secondLargest,已经正确的决定了。那么总数至少是n+lgn-2次比较是必须完成的。因此我们将展示对策论,迫使任何一种算法寻找secondLargest去比较和max比较过的不同的lgn个相异的键。
对手为每个在集合中的键x都分配了“权重”w(x),所有的x都初始化w(x)=1。当算法比较两个键值x和y时,对手决定于他的回应,并修改权重,如下:
情况 对手的回应 权重的更新
---------------------------------------------------------------------------
w(x)>w(y) x>y w(x)=w(x)+w(y); w(y)=0
w(x)=w(y)>0 如上 如上
w(y)>w(x) y>x w(y)=w(x)+w(y) ;w(x)=0
w(x)=w(y) 与前面的回应保持一致 不做改变
为了解释权重和对手的规则,想象对手为了表示元素之间顺序的关系建立了树。如果x是y的父节点,那么x在一次比较中打败了y。图5.2展示了该例子。只有当他们的根比较的时候对手就合并两棵树。如果算法比较非根元素,则树没有改变,键的权重是在键树中节点的个数,如果他是根和否则都是0.
{kind=link}


如果对手遵循以下策略,我们就需要修改,它的回应和某个输入是一致的,并且max至少有lgn个键值需要比较。这些结论从一系列的简单的观察中得到:
1.一个键在有且仅有一次比较中失败,它的权重为0。
2.在第一棵树的情况中,被选出来做获胜者的键权重都不为0,所以它也从未失败过。在与任何其先前的答复不矛盾的情况下,对手可以给它一个任意高的值,确保它获胜。
3.权重的总值总是n,这是初始化的,并且总值靠更新权重来维持。
4.当算法停下来时,仅有一个键有非0权重。否则,至少有两个键在比较重从未失败过,并且对手将选择值,来使算法选择的secondLargest是不正确的。
设x是当算法停止时,拥有非0权重的键值。通过上述因素1和4,x=max,当算法停止时,利用因素3,w(x)=n.
为了完成该定理的证明,我们需要展示x至少需要赢得lgn个相异的键,设wk=w(x),在k次和从未输过的元素比较获胜之后。那么对手的规则就是![]()
现在是K等于x赢得以前从来没输过的键的比较次数,那么
![]()
因此K≥lgn,并且因为K是整数,所以K≥lgn的上界。当然,数到这里的K的值是唯一的,因为一旦被x打败,这个键就不再是先前从未被打败的值了并且也不能再算数了(即使一种算法愚蠢的把它和x再比一遍)。
例5.2对策论的实施
为了描述对策论的行为,并展示他的决策是怎样和输入架构一步一步的照应的,我们举一个例子,该集合中有n=5个元素,没有指定的用*来标注,因此元素初始化为*,*,*,*。注意分配的值在后续可能会改变。看表格5.3,显示的仅仅是第一批的几个比较(找到max,但还不能够找到secondLargest)。权重和分配给键的值在任何子序列的比较中都不再改变。

5.3.4查找max和secondLargest的竞技法的实现
为了查找max和secondLargest的竞技法在每一轮中都需要跟踪胜利者。通过竞技法找到max之后,那些和max比较失败过的元素中再找secondLargest,当我们事先并不找到哪个元素是max时,我们怎么跟踪那些和max比较失败过的元素呢?因为竞技法从概念上是一棵尽可能平衡的二叉树,就想4.8.1节中堆结构一样,n个元素的集合,堆结构有2n-1个节点;也就是说一个数组E[1],……,E[2*n-1].初始化,把元素放到位置n,……,2n-1的位置上,当竞技法演进时,位置1……n-1将被填上获胜者。习题5.4概括了剩余细节。该算法使用了线性多余空间,并且执行了线性时间。
5.4选择问题
假设我们想找到数组E中n个元素的中间值,在前面的部分,我们已经找到有效的方法来查找与极值相邻或者另一个极值,例如最大值,最小值,最大和最小值,以及次大值。该练习找到了很多变种,但这些问题的所有技术在寻找中间值的问题上都失效了。如果我们想找到一个比给整个集合排序更有效的找到中间值的解决办法,那么久需要一个新的想法。
5.4.1分治法
假设我们将集合分为两个部分S1和S2,所有在S1中的元素都小于所有在S2中的元素,那么中间值就在两个集合中规模较大的一个中(也就是说这个集合有更多的键值,并不需要这个集合有更大的键值)。我们就可以忽略另一个集合,并将我们的搜索局限在规模较大的集合了。
但是在较大集合中哪个值才是我们查找的呢?它的中间值并不是一般集合的中间值。
例5.3 分区查找中间值
假设n=255.我们要查找中间元素(排列k=128)。假设分区后,S1中友96个元素,S2中友159个元素,那么中间值就在S2中,而且是S2中的第32小的元素,因此问题就减少为查找有159个元素的S2中排在第32位的元素。
该例子展示了解决中间值的很自然的方法例子表明我们解决一般性的选择问题。
因此我们找到了一种分治法来解决一般性选择问题,像二叉树和堆的建立,将一个问题划分成两个更小的问题,但是仅需要解决两个小问题中的一个就可以了。快速排序用的是分区,根据参照元素将元素划分为“小”和“大”的子序列。我们可以用一个修改过的快速排序的版本来解决选择问题,叫做找出第k个最值,在这里仅仅有一次递归子问题需要解决,该细节将在习题5.8中解决。
在习题5.8的分析中,我们知道了当我们分析快速排序的时候,我们发现相同的模式出现,尽管找出k次大最值平均上很好,但最坏情况下遇到快速排序就是灾难:参照值元素可能给定的划分的S1和S2极其不均衡,为了找到更好的解决方法,思考我们从快速排序中得到了什么。
我们看到这个问题的症结在于选出一个“好”的参照元素,我们可以重温一下4.4.4的方案,但是他们中没有一个敢保证将集合元素划分为相等的两个集合或者几乎相等,规模。在下一节中,我们将看到,通过投入更大的努力,可能会选出一个保证“好”的参照元素,它保证了每个集合至少有0.3n和最多有0.7n的元素。有了这“高质量”的参照元素,分治法在最坏情况下也可以很高效,平均情况也一样。
5.5寻找中间值的下界
我们假设E是有n个元素的集合,并且n是偶数。我们将建立任何一种基于比较来找中间值的算法的比较的下界,(n+1)/2.因为我们要建立一个下界,不失一般性,我们可以假设这些键都是相异的。
我们宣称首先知道median,一个算法一定知道其他每个元素与median的关系,也就是说,对于每一个其他元素x,算法必须知道x>median还是x<median,换句话而言,它必须建立想图5.5描述那样的用树表示的关系。
每个节点都代表一个键值,并且每个分支都代表依次比较,在更高分支的键都是更大的键值,假设某个键,比如说y,它和median的关

系式不知道的,(看图5.6(a)) 一个对手可以改变y的值,将它移到median的对面(如图5.6(b)),没有任何矛盾的结果进行的比较。那么median就不是中间值,该算法的回答是错的。
因为在图5.5的树中有n个节点,有n-1个分支,因此至少有n-1次比较。这是既没有惊喜的也没有令人兴奋的下界。在它需要建立图5.5中的树,它执行n-1次比较之前,我们将表明对手可以迫使一个算法做其他“无用”的比较。
定义5.1 关键的比较
一个涉及到键x的比较对x而言如果这是它的第一次比较且当某个y≥median时x>y,或者当某个y≤median时x<y,则是关键的比较,。当x>median且y<median时,x与y的比较就不重要了。
一个关键的比较可以建立x与median的关系,事先知道y与median的关系在X的关键比较的时候是不需要。
我们将展示一个攻击者迫使一个算法做非关键性的比较。攻击者会选择某个值(但不是某个特定的值)为median。当算法第一次用到这个键参加比较的时候,它将分配给一个值给一个键。只要它这样做,攻击者就分配值给新参与到盖茨比较中的键,致使该键移到median的对立面。攻击者可能不分配比median大的值给超过(n-1)/2个键,也不会分配比median小的值给超过(n-1)/2个键。它跟踪曾经做过的分配的轨迹,保证不违反限制条件。我们指明,在算法执行的过程中键的状态如下:
L 已经被分配给比median大的值
S 已经被分配给比median小的值
N 还没有参见比较
-------------------------------------------------------------------------------------------------
比较者 攻击者的行为
-----------------------------------------------------------------------------------------------------
N,N 使一个值大于median,另一个小于
L,N N,L 分配给N一个比median小的值
S,N N,S 分配给N一个比median大的值
-----------------------------------------------------------------------------------------------------
表格5.4 寻找中间值问题的对策论
在表格5.4中总结了对策论,在所有情况下,如果状态S或者L已经有(n-1)/2个键了,那么攻击者就忽略表格中的规则,并分配比median大(小)的值给新的键。当只剩下一个键没有值的时候,攻击者就把median分配给这个键。不管什么时候算法比较两个状态为LL的键,或者SS,或者LS的时候,攻击者会给予它已经分配值给键来做出正确的回应。
表格5.4中描述的所有比较都不是关键的,攻击者可以迫使算法做多少次这样的比较呢?每一次这样的比较至少生成一个L键,并且每次至少产生一个S键,因为攻击者可以很随意的做这种指的分配,至到有(n-1)/2个L键或者有(n-1)/2个S键,它可以迫使任何一种算法做至少(n-1)/2次不关键的比较。(因为一个算法可以通过比较(n-1)/2次两个N键来开始,攻击者不能保证多于(n-1)/2次的非关键比较)。
我们现在可以总结比较的总数至少为n-1次(关键比较)+(n-1)/2次(非关键比较)。我们在下面定理中总结了该结果
定理5.3任何通过比较找n个元素中间值的问题最坏情况下至少需要做3n/2-3/2次比较。
我们的对手是不聪明,因为它可能企图迫使算法做非关键比较。在过去的纪念,寻找中间值问题的下界已经粗略到1.75n-logn,那么粗略到1.8n,那么仍然有一点高。目前众所周知的最好的下界在2n稍微之上。在寻找中间值问题上,这仍然有一个小的空间在最好的下界和最好的算法之间。
5.6针对对手的设计
针对对手的设计是一个十足的技术活,来开发一个有像比较这样操作的算法,这将引出一些关于输入元素的信息,最主要的思想是去预测任何问题(即算法执行的比较或者其他执行的测试)将收到一个由对手选择的尽最大可能对算法不利的答案,经常是得到最少的信息。为了解决这个问题,算法应该选择正反两个答案都将可能给出同样多的信息的比较(或者其他什么操作)。
当我们学习了决策树,一个好的算法的思想用到一些之前出现的平衡的概念。对一个算法而言最坏情况下比较的次数就是该算法决策树的高度。为了保持一个固定问题规模的小的树高,就意味着尽可能的保持树的平衡。一个很好的算法选择比较了一些该比较一个结果的可能输出的数目与另一个结果的输出数目大致相等。
我们已经看到了这个技术的几个例子:归并排序,同时找最大值和最小值,找次大值。利用竞技法找次大值的第一部分,也就是竞技法找最大值时最好的一个例子。第一轮每个元素的比较是两个什么都不知道的元素的比较,所以攻击者对有利于一个答案或者另一个答案,没有偏见。在下面几轮中,尽可能地,有相等输和赢记录的比较,所以攻击者给不出一个回答使得到比另一个少的信息。相反,一个简单的算法首先比较x1和x2来获得最大值,然后再用胜利者和x3比较,在这种情况下,攻击者可以给出另一个更少信息的回答。(哪个)
一般来说,基于比较的问题,元素的完整的状态,包括多于以前的胜利和失败,而,一个元素的状态包含的括比已知要小一些的元素数量并且由及物性元素的数量比已知的要多一些,像图5.2中描述的一样树的结构可以用来代表信息的图形化的状态。
为了进一步的描述对策论设计的技术,我们考虑两个问题,这两个问题的最优解决是很困难的:5个元素中找中间值和五个元素排序,通过6次比较可以找到中间值,通过7次比较可以将5个元素排序,许多同学花费大量的时间尝试各种策略,该解决看起来并不成功。最优的算法尽可能从每一次的比较中挤出最多的信息,我们在该节中描述的技术在开始给出了最大的提高。第一个比较是任意的;在两个我们不找到任何信息的元素之间是必须的,第二个比较是否应该包括这些中的任一键呢?不;比较两个新的元素,将有两个相等的状态,给出更多的信息。现在我们有两个元素一个大于另一个,两个元素一个小于另一个,和一个没有检测的元素,下面你将要比较哪两个?
你是否已经开始考虑我们在进行哪个问题?针对对策论的设计技术建议第一课同样的树的比较为中间值问题和排序问题,结束该算法仍然是棘手的,启发性的练习。