许多Windows程序开发者喜欢使用WM_COPYDATA来实现一些进程间的简单通信(笔者也正在学习共享内存的一些知识来实现一些更高级的通信),这篇文章描述了笔者在使用这项技术时候的一些总结以及所遇到的一个问题回顾和分析。
进程通讯的相关知识
在Windows程序中,各个进程之间常常需要交换数据,进行数据通讯。常用的方法有
- 使用内存映射文件
- 通过共享内存DLL共享内存
- 使用SendMessage向另一进程发送WM_COPYDATA消息
比起前两种的复杂实现来,WM_COPYDATA消息无疑是一种经济实惠的一种方法
WM_COPYDATA的相关知识
typedef struct tagCOPYDATASTRUCT {
ULONG_PTR dwData; //用户定义数据
DWORD cbData; //用户定义数据的长度
__field_bcount(cbData) PVOID lpData; //指向用户定义数据的指针
} COPYDATASTRUCT, *PCOPYDATASTRUCT;
COPYDATASTRUCT结构是WM_COPYDATA的参数,在这里可以指定对象的内存地址,对象的长度,data可以是子进程和父进程都认识的对象
- WM_COPYDATA消息只可以使用SendMessage函数(同步)发送,不可以使用PostMessage(异步)发送,笔者认为可能是异步形式下无法保证指向数据的指针可以正确的释放。
- COPYDATA结构体的实质依然是共享内存,区别是这一片特殊的共享内存由操作系统管理而不用用户手动申请管理。
- WM_COPYDATA适合小数据量的进程间通信,大数据量可能造成内存问题,以及界面卡死,因为消息的发送形式是同步的。
WM_COPYDATA运用在进程通信
一个简单的发送方和接收方的代码(C++实现):
发送端
void CSendDlg::OnDataSend()
{
CWnd *pWnd = CWnd::FindWindow(NULL,"接收窗口的标题");
CString sCopyData = "HELLO";
COPYDATASTRUCT cpd;
cpd.dwData = 0;
cpd.cbData = sCopyData.GetLength() + 1;//多加一个长度,防止乱码
cpd.lpData = (void*)sCopyData.GetBuffer(cpd.cbData);
pWnd->SendMessage(WM_COPYDATA,NULL,(LPARAM)&cpd);
}
接收端(需要根据实际情况做一些修改,下面的文章会更新)
// 声明 afx_msg void OnCopyData(CWnd* pWnd, COPYDATASTRUCT* pCopyDataStruct);
// 添加消息映射 BEGIN_MESSAGE_MAP(CMainFrame, CCJMDIFrameWnd)
...
...
ON_MESSAGE(WM_COPYDATA, OnCopyData)
...
...
END_MESSAGE_MAP()
//函数实现
BOOL CReceiveDlg::OnCopyData( CWnd* pWnd, COPYDATASTRUCT* pCopyDataStruct ) { AfxMessageBox((LPCSTR)(pCopyDataStruct->lpData)); }
WM_COPYDATA使用过程中遇到的一个问题
在使用了类似上述代码时,笔者遇到一个问题,如果使用CString类型传递数据时,在接受方的窗体内,始终只能接受到第一个字母,既如果发送端发送“HELLO”,接收端只能收到“H”。
原因:
单步调试的时候发现传进去的其实是L"HELLO",这表示“HelloWorld”将以unicode形式编码,Visual Studio默认默认采用unicode编码
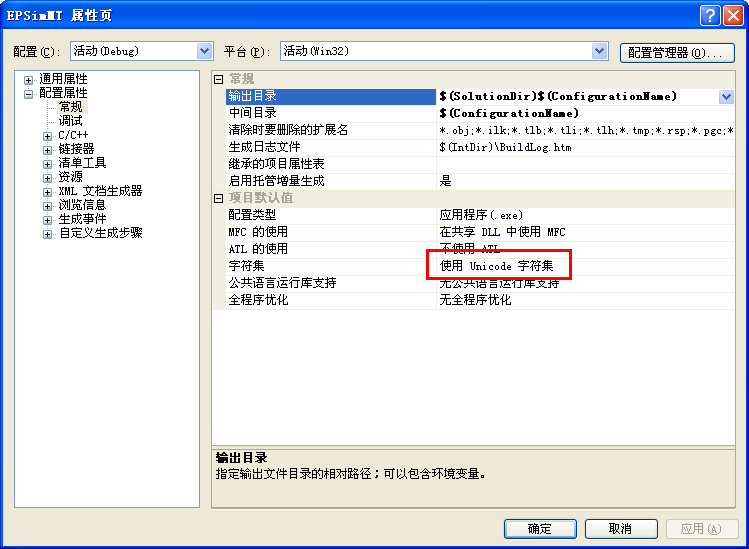
客户端读取的方式是LPTSTR,LPTSTR被定义成是一个指向以NULL(‘�’)结尾的16位ANSI字符数组指针,而接受到的数据是一个以Unicode编码的32位双字节字符数组指针。这必然将产生截断的问题
Unicode使用两个字节表示一个字符,字符'H'的Unicode编码就是0x0072,此时“HELLO”在内存中的表现形式是:
72 00 - ‘H’
69 00 - ‘E'
76 00 - ‘E'
76 00 - ‘E'
79 00 - 'O'
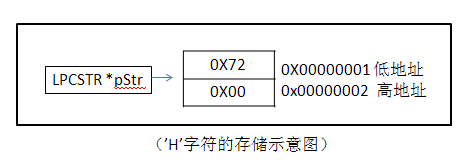
(注:基于X86平台的PC是基于Little Endian既将低字节存储在起始地址,故有如上地址分布)
因为x86CPU是little-endian,值0x0072在内存中的存储形式是72 00。你能看出如果这个字符串被传给strlen()函数会出现什么问题吗?它将先看到第一个字节42,然后是00,而00是字符串结束的标志,于是 strlen()将会返回1。所以如果用LPTSTR既1个字节对齐的方式去读取数据,只能得到首字母H
解决方法:
遇到类似的问题,一定需要了解字符的编码方式,然后用正确的方式去读取,在这里应该用微软所提供的LPWSTR既指向宽字符的指针去读取该字符串方可以得到正确的输出:
CString sCopyData = (LPWSTR)(pCopyDataStruct->lpData);
注:LPWSTR可使用上述方式显示转换为CString
反思:
字符的编码方式一定要理解清楚,否则将会带来难以发现的bug
以上是笔者粗略的理解,如果有不当之处欢迎指正。