感谢作者 –> 原文链接
本文翻译自The Flask Mega-Tutorial Part VIII: Followers
这是Flask Mega-Tutorial系列的第八部分,我将告诉你如何实现类似于Twitter和其他社交网络的“粉丝”功能。
在本章中,我将更多地使用应用的数据库。 我希望应用的用户能够轻松便捷地关注其他用户。 所以我要扩展数据库,以便跟踪谁关注了谁,这比你想象的要难得多。
本章的GitHub链接为:Browse, Zip, Diff.
深入理解数据库关系
我上面说过,我想为每个用户维护一个“粉丝”用户列表和“关注”用户列表。 不幸的是,关系型数据库没有列表类型的字段来保存它们,那么只能通过表的现有字段和他们之间的关系来实现。
数据库已有一个代表用户的表,所以剩下的就是如何正确地组织他们之间的关注与被关注的关系。 这正是回顾基本数据库关系类型的好时机:
一对多
我已经在第四章中用过了一对多关系。这是该关系的示意图(译者注:实际表名分别为user和post):
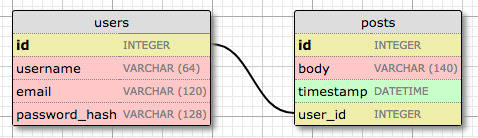
用户和用户动态通过这个关系来关联。其中,一个用户拥有多条用户动态,而一条用户动态属于一个用户(作者)。数据库在多的这方使用了一个外键以表示一对多关系。在上面的一对多关系中,外键是post表的user_id字段,这个字段将用户的每条动态都与其作者关联了起来。
很明显,user_id字段提供了直接访问给定用户动态的作者,但是反向呢? 透过这层关系,我如何通过给定的用户来获得其用户动态的列表?post表中的user_id字段也足以回答这个问题,数据库具有索引,可以进行高效的查询“返回所有user_id字段等于X的用户动态”。
多对多
多对多关系会更加复杂,举个例子,数据库中有students表和teachers表,一名学生学习多位老师的课程,一位老师教授多名学生。这就像两个重叠的一对多关系。
对于这种类型的关系,我想要能够查询数据库来获取教授给定学生的教师的列表,以及某个教师课程中的学生的列表。 想要在关系型数据库中梳理这样的关系并非轻易而举,因为无法通过向现有表添加外键来完成此操作。
展现多对多关系需要使用额外的关联表。以下是数据库如何查找学生和教师的示例:
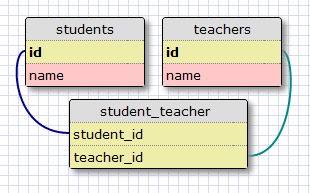
虽然起初看起来并不明显,但具有两个外键的关联表的确能够有效地回答所有多对多关系的查询。
多对一和一对一
多对一关系类似于一对多关系。 不同的是,这种关系是从“多”的角度来看的。
一对一的关系是一对多的特例。 实现是相似的,但是一个约束被添加到数据库,以防止“多”一方有多个链接。 虽然有这种类型的关系是有用的,但并不像其他类型那么普遍。
译者注:如果读者有兴趣,也可以看看我写的一篇类似的数据库关系文章——Web开发中常用的数据关系
实现粉丝机制
查看所有关系类型的概要,很容易确定维护粉丝关系的正确数据模型是多对多关系,因为用户可以关注多个其他用户,并且用户可以拥有多个粉丝。 不过,在学生和老师的例子中,多对多关系关联了两个实体。 但在粉丝关系中,用户关注其他用户,只有一个用户实体。 那么,多对多关系的第二个实体是什么呢?
该关系的第二个实体也是用户。 一个类的实例被关联到同一个类的其他实例的关系被称为自引用关系,这正是我在这里所用到的。
使用自引用多对多关系来实现粉丝机制的表结构示意图:
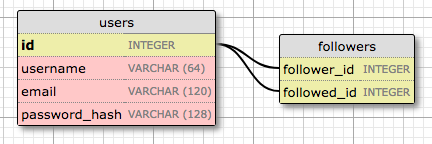
followers表是关系的关联表。 此表中的外键都指向用户表中的数据行,因为它将用户关联到用户。 该表中的每个记录代表关注者和被关注者的一个关系。 像学生和老师的例子一样,像这样的设计允许数据库回答所有关于关注和被关注的问题,并且足够干净利落。
数据库模型的实现
首先,让我们在数据库中添加粉丝机制吧。这是followers关联表:
这是上图中关联表的直接翻译。 请注意,我没有像我为用户和用户动态所做的那样,将表声明为模型。 因为这是一个除了外键没有其他数据的辅助表,所以我创建它的时候没有关联到模型类。
现在我可以在用户表中声明多对多的关系了:
建立关系的过程实属不易。 就像我为post一对多关系所做的那样,我使用db.relationship函数来定义模型类中的关系。 这种关系将User实例关联到其他User实例,所以按照惯例,对于通过这种关系关联的一对用户来说,左侧用户关注右侧用户。 我在左侧的用户中定义了followed的关系,因为当我从左侧查询这个关系时,我将得到已关注的用户列表(即右侧的列表)。 让我们逐个检查这个db.relationship()所有的参数:
'User'是关系当中的右侧实体(将左侧实体看成是上级类)。由于这是自引用关系,所以我不得不在两侧都使用同一个实体。secondary指定了用于该关系的关联表,就是使用我在上面定义的followers。primaryjoin指明了通过关系表关联到左侧实体(关注者)的条件 。关系中的左侧的join条件是关系表中的follower_id字段与这个关注者的用户ID匹配。followers.c.follower_id表达式引用了该关系表中的follower_id列。secondaryjoin指明了通过关系表关联到右侧实体(被关注者)的条件 。 这个条件与primaryjoin类似,唯一的区别在于,现在我使用关系表的字段的是followed_id了。backref定义了右侧实体如何访问该关系。在左侧,关系被命名为followed,所以在右侧我将使用followers来表示所有左侧用户的列表,即粉丝列表。附加的lazy参数表示这个查询的执行模式,设置为动态模式的查询不会立即执行,直到被调用,这也是我设置用户动态一对多的关系的方式。lazy和backref中的lazy类似,只不过当前的这个是应用于左侧实体,backref中的是应用于右侧实体。
如果理解起来比较困难,你也不必过于担心。我待会儿就会向你展示如何利用这些关系来执行查询,一切就会变得清晰明了。
数据库的变更,需要记录到一个新的数据库迁移中:
关注和取消关注
感谢SQLAlchemy ORM,一个用户关注另一个用户的行为可以通过followed关系抽象成一个列表来简便使用。 例如,如果我有两个用户存储在user1和user2变量中,我可以用下面这个简单的语句来实现:
要取消关注该用户,我可以这么做:
即便关注和取消关注的操作相当容易,我仍然想提高这段代码的可重用性,所以我不会直接在代码中使用“appends”和“removes”,取而代之,我将在User模型中实现“follow”和“unfollow”方法。 最好将应用逻辑从视图函数转移到模型或其他辅助类或辅助模块中,因为你会在本章之后将会看到,这使得单元测试更加容易。
下面是用户模型中添加和删除关注关系的代码变更:
follow()和unfollow()方法使用关系对象的append()和remove()方法。有必要在处理关系之前,使用一个is_following()方法来确认操作的前提条件是否符合,例如,如果我要求user1关注user2,但事实证明这个关系在数据库中已经存在,我就没必要重复操作了。 相同的逻辑可以应用于取消关注。
is_following()方法发出一个关于followed关系的查询来检查两个用户之间的关系是否已经存在。 你已经看到过我使用SQLAlchemy查询对象的filter_by()方法,例如,查找给定用户名的用户。 我在这里使用的filter()方法很类似,但是更加偏向底层,因为它可以包含任意的过滤条件,而不像filter_by(),它只能检查是否等于一个常量值。 我在is_following()中使用的过滤条件是,查找关联表中左侧外键设置为self用户且右侧设置为user参数的数据行。 查询以count()方法结束,返回结果的数量。 这个查询的结果是0或1,因此检查计数是1还是大于0实际上是相等的。 至于其他的查询结束符all()和first(),你已经看到我使用过了。
查看已关注用户的动态
在数据库中支持粉丝机制的工作几近尾声,但是我却遗漏了一项重要的功能。应用主页中需要展示已登录用户关注的其他所有用户的动态,我需要用数据库查询来返回这些用户动态。
最显而易见的方案是先执行一个查询以返回已关注用户的列表,如你所知,可以使用user.followed.all()语句。然后对每个已关注的用户执行一个查询来返回他们的用户动态。最后将所有用户的动态按照日期时间倒序合并到一个列表中。听起来不错?其实不然。
这种方法有几个问题。 如果一个用户关注了一千人,会发生什么? 我需要执行一千个数据库查询来收集所有的用户动态。 然后我需要合并和排序内存中的一千个列表。 作为第二个问题,考虑到应用主页最终将实现分页,所以它不会显示所有可用的用户动态,只能是前几个,并显示一个链接来提供感兴趣的用户查看更多动态。 如果我要按它们的日期排序来显示动态,我怎么能知道哪些用户动态才是所有用户中最新的呢?除非我首先得到了所有的用户动态并对其进行排序。 这实际上是一个糟糕的解决方案,不能很好地应对规模化。
用户动态的合并和排序操作是无法避免的,但是在应用中执行会导致效率十分低下, 而这种工作是关系数据库擅长的。 我可以使用数据库的索引,命令它以更有效的方式执行查询和排序。 所以我真正想要提供的方案是,定义我想要得到的信息来执行一个数据库查询,然后让数据库找出如何以最有效的方式来提取这些信息。
看看下面的这个查询:
这是迄今为止我在这个应用中使用的最复杂的查询。 我将尝试一步一步地解读这个查询。 如果你看一下这个查询的结构,你会注意到有三个主要部分,分别是join()、filter()和order_by(),他们都是SQLAlchemy查询对象的方法:
联合查询
要理解join操作的功能,我们来看一个例子。 假设我有一个包含以下内容的User表:
| id | username |
|---|---|
| 1 | john |
| 2 | susan |
| 3 | mary |
| 4 | david |
为了简单起见,我只会保留用户模型的id和username字段以便进行查询,其他的都略去。
假设followers关系表中数据表达的是用户john关注用户susan和 david,用户susan关注用户mary,用户mary关注用户david。这些的数据如下表所示:
| follower_id | followed_id |
|---|---|
| 1 | 2 |
| 1 | 4 |
| 2 | 3 |
| 3 | 4 |
最后,用户动态表中包含了每个用户的一条动态:
| id | text | user_id |
|---|---|---|
| 1 | post from susan | 2 |
| 2 | post from mary | 3 |
| 3 | post from david | 4 |
| 4 | post from john | 1 |
这张表也省略了一些不属于这个讨论范围的字段。
这是我为该查询再次设计的join()调用:
我在用户动态表上调用join操作。 第一个参数是followers关联表,第二个参数是join条件。 我的这个调用表达的含义是我希望数据库创建一个临时表,它将用户动态表和关注者表中的数据结合在一起。 数据将根据参数传递的条件进行合并。
我使用的条件表示了followers关系表的followed_id字段必须等于用户动态表的user_id字段。 要执行此合并,数据库将从用户动态表(join的左侧)获取每条记录,并追加followers关系表(join的右侧)中的匹配条件的所有记录。 如果followers关系表中有多个记录符合条件,那么用户动态数据行将重复出现。 如果对于一个给定的用户动态,followers关系表中却没有匹配,那么该用户动态的记录不会出现在join操作的结果中。
利用我上面定义的示例数据,执行join操作的结果如下:
| id | text | user_id | follower_id | followed_id |
|---|---|---|---|---|
| 1 | post from susan | 2 | 1 | 2 |
| 2 | post from mary | 3 | 2 | 3 |
| 3 | post from david | 4 | 1 | 4 |
| 3 | post from david | 4 | 3 | 4 |
注意user_id和followed_id列在所有数据行中都是相等的,因为这是join条件。 来自用户john的用户动态不会出现在临时表中,因为被关注列表中没有包含john用户,换句话说,没有任何人关注john。 而来自david的用户动态出现了两次,因为该用户有两个粉丝。
虽然创建了这个join操作,但却没有得到想要的结果。请继续看下去,因为这只是更大的查询的一部分。
过滤
Join操作给了我一个所有被关注用户的用户动态的列表,远超出我想要的那部分数据。 我只对这个列表的一个子集感兴趣——某个用户关注的用户们的动态,所以我需要用filter()来剔除所有我不需要的数据。
这是过滤部分的查询语句:
该查询是User类的一个方法,self.id表达式是指我感兴趣的用户的ID。filter()挑选临时表中follower_id列等于这个ID的行,换句话说,我只保留follower(粉丝)是该用户的数据。
假如我现在对id为1的用户john能看到的用户动态感兴趣,这是从临时表过滤后的结果:
| id | text | user_id | follower_id | followed_id |
|---|---|---|---|---|
| 1 | post from susan | 2 | 1 | 2 |
| 3 | post from david | 4 | 1 | 4 |
这正是我想要的结果!
请记住,查询是从Post类中发出的,所以尽管我曾经得到了由数据库创建的一个临时表来作为查询的一部分,但结果将是包含在此临时表中的用户动态, 而不会存在由于执行join操作添加的其他列。
排序
查询流程的最后一步是对结果进行排序。这部分的查询语句如下:
在这里,我要说的是,我希望使用用户动态产生的时间戳按降序排列结果列表。排序之后,第一个结果将是最新的用户动态。
组合自身动态和关注的用户动态
我在followed_posts()函数中使用的查询是非常有用的,但有一个限制,人们期望看到他们自己的动态包含在他们的关注的用户动态的时间线中,而该查询却力有未逮。
有两种可能的方式来扩展此查询以包含用户自己的动态。 最直截了当的方法是将查询保持原样,但要确保所有用户都关注了他们自己。 如果你是你自己的粉丝,那么上面的查询就会找到你自己的动态以及你关注的所有人的动态。 这种方法的缺点是会影响粉丝的统计数据。 所有人的粉丝数量都将加一,所以它们必须在显示之前进行调整。 第二种方法是通过创建第二个查询返回用户自己的动态,然后使用“union”操作将两个查询合并为一个查询。
深思熟虑之后,我选择了第二个方案。 下面你可以看到followed_posts()函数已被扩展成通过联合查询来并入用户自己的动态:
请注意,followed和own查询结果集是在排序之前进行的合并。
对用户模型执行单元测试
虽然我不担心这个稍显“复杂”的粉丝机制的运行是否无误。 但当我编写举足轻重的代码时,我担心的是我在应用的不同部分修改了代码之后,如何确保本处代码将来会继续工作。 确保已经编写的代码在将来继续有效的最佳方法是创建一套自动化测试,你可以在每次更新代码后执行测试。
Python包含一个非常有用的unittest包,可以轻松编写和执行单元测试。 让我们来为User类中的现有方法编写一些单元测试并存储到tests.py模块:
我添加了四个用户模型的测试,包含密码哈希、用户头像和粉丝功能。 setUp()和tearDown()方法是单元测试框架分别在每个测试之前和之后执行的特殊方法。 我在setUp()中实现了一些小技巧,以防止单元测试使用我用于开发的常规数据库。 通过将应用配置更改为sqlite://,我在测试过程中通过SQLAlchemy来使用SQLite内存数据库。 db.create_all()创建所有的数据库表。 这是从头开始创建数据库的快速方法,在测试中相当好用。 而对于开发环境和生产环境的数据库结构管理,我已经通过数据库迁移的手段向你展示过了。
你可以使用以下命令运行整个测试组件:
从现在起,每次对应用进行更改时,都可以重新运行测试,以确保正在测试的功能没有受到影响。 另外,每次将另一个功能添加到应用时,都应该为其编写一个单元测试。
在应用中集成粉丝机制
数据库和模型中粉丝机制的实现现在已经完成,但是我没有将它集成到应用中,所以我现在要添加这个功能。 值得高兴的是,实现它没有什么大的挑战,都将基于你已经学过的概念。
让我们来添加两个新的路由和视图函数,它们提供了用户关注和取消关注的URL和逻辑实现:
视图函数的逻辑不言而喻,但要注意所有的错误检查,以防止出现意外的问题,并尝试在出现问题时向用户提供有用的信息。
我将添加这两个视图函数的路由到每个用户的个人主页中,以便其他用户执行关注和取消关注的操作:
用户个人主页的变更,一是在最近访问的时间戳之下添加一行,以显示此用户拥有多少个粉丝和关注用户。二是当你查看自己的个人主页时出现的“Edit”链接的行,可能会变成以下三种链接之一:
- 如果用户查看他(她)自己的个人主页,仍然是“Edit”链接不变。
- 如果用户查看其他并未关注的用户的个人主页,显示“Follow”链接。
- 如果用户查看其他已经关注的用户的个人主页,显示“Unfollow”链接。
此时,你可以运行该应用,创建一些用户并测试一下关注和取消关注用户的功能。 唯一需要记住的是,需要手动键入你要关注或取消关注的用户的个人主页URL,因为目前没有办法查看用户列表。 例如,如果你想关注susan,则需要在浏览器的地址栏中输入http://localhost:5000/user/susan以访问该用户的个人主页。 请确保你在测试关注和取消关注的时候,留意到了其粉丝和关注的数量变化。
我应该在应用的主页上显示用户动态的列表,但是我还没有完成所有依赖的工作,因为用户不能发表动态。 所以我会暂缓这个页面的完善工作,直到发表用户动态功能的完成。