数据:使用的文章给出的数据,保存在/home/amelie/Haddoop_file/ncdc.txt
环境:ubuntu16.04LTS,hadoop伪分布式
- 使用eclipse,新建一个Map/Reduce project(我感觉普通的project也可以),名字为Chap2
- 在目录src目录下新建package,名为chap2_Package
- 在这个package包下分别建立三个class,分别为MaxTemperatureMapper,MaxTemperatureReducer,MaxTemperature。
- MaxTemperatureMapper.java
package chap2_Package; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MaxTemperatureMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ private static final int MISSING=9999; public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ String line= value.toString(); String year=line.substring(5,9); int airTemperature=Integer.parseInt(line.substring(15,19)); if(airTemperature!=MISSING){ context.write(new Text(year),new IntWritable(airTemperature)); } } }
- MaxTemperatureReducer.java
package chap2_Package; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MaxTemperatureReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int maxValue=Integer.MIN_VALUE; for(IntWritable value:values){ maxValue=Math.max(maxValue, value.get()); } context.write(key, new IntWritable(maxValue)); } }
- MaxTemperature.java
package chap2_Package; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MaxTemperature { public static void main(String[] args) throws Exception { if(args.length!=2){ System.err.println("Usage: MaxTemperature <input path> <output path>"); System.exit(-1); } Job job=new Job(); job.setJarByClass(MaxTemperature.class); job.setJobName("Max temperature"); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setMapperClass(MaxTemperatureMapper.class); job.setReducerClass(MaxTemperatureReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
可能还会有什么问题,修修改改的就好啦
4.将这三个文件所在的package,点击export
- 选择为jar file
- next:文件位置:/home/amelie/Hadoop_file/,写入文件名称,不限定,此处为:HadoopTest.jar
- next:接下来的设置默认
- next:需要选择main class,点击页面的Browse..即可选择,如此处填入:Chap2_package.MaxTemperature

jar包形成,接下来进行操作
#cd /usr/local/hadoop/hadoop-2.5.2 //进入hadoop目录
打开hadoop后,进行下面操作
#hadoop fs -put /home/amelie/Hadoop_file/ncdc.txt /data/input //将数据文件放入hadoop目录下的/data/input
经常会出现提示,找不到hadoop命令,此时,用命令更新profile就好:source /etc/profile
#export HADOOP_CLASSPATH=/home/amelie/Hadoop_file //这个地址是放jar文件的地址,不知道这句话什么用,但还是运行了
执行jar命令
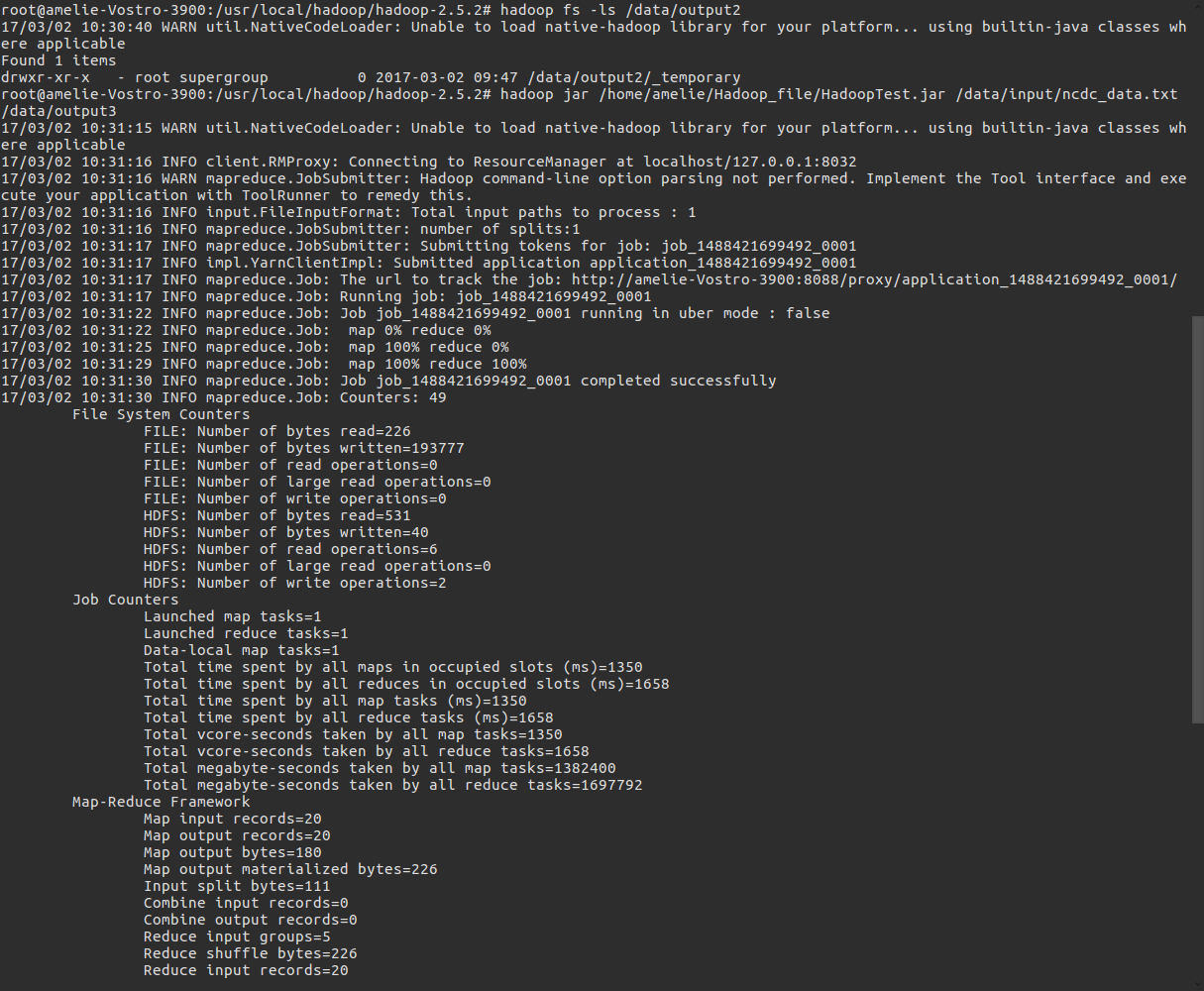
#hadoop jar /home/amelie/Hadoop_file/HadoopTest.jar /data/input/ncdc_data.txt /data/output3
因为打包时已经制定了mainclass,所以,没有写class name
若未指定,运行hadoop jar 命令时在***.jar后面需要指定包括包路径的mainclass类名
例如 hadoop jar /home/amelie/Hadoop_file/HadoopTest.jar Chap2_package.MaxTemperature /data/input/ncdc_data.txt /data/output3
运行结果:
查看输出:
#hadoop fs -ls /data/output3 #hadoop fs -cat /data/output3/part-r-00000
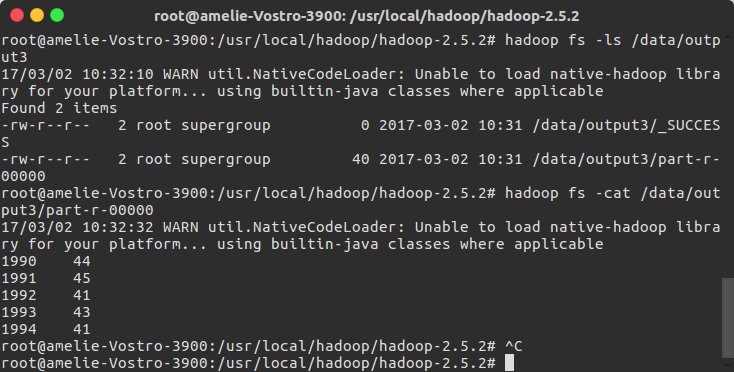
完成!!