
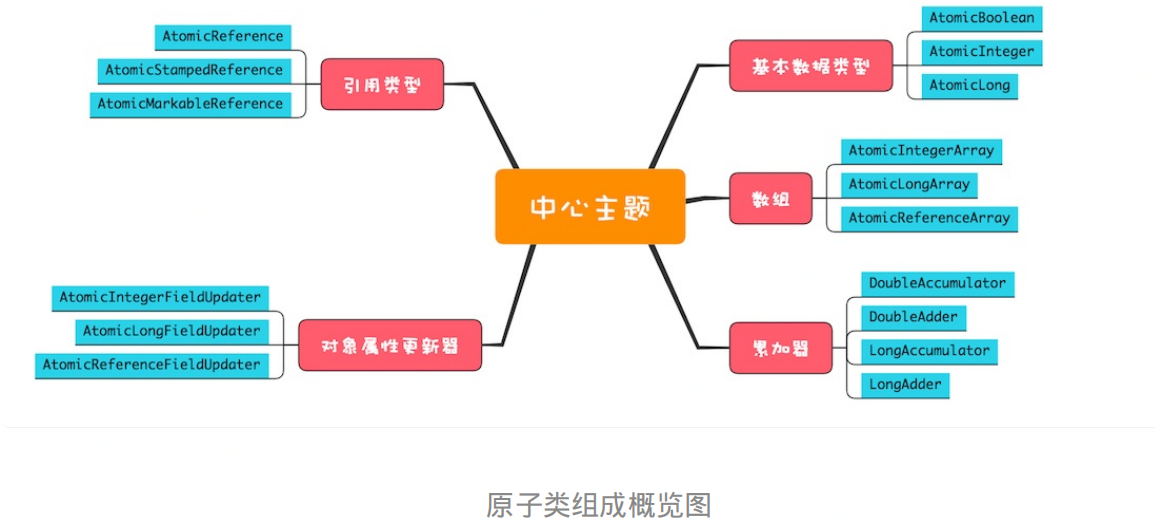
Java SDK 并发包里提供的原子类内容很丰富,我们可以将它们分为五个类别:原子化的基本数据类型、原子化的对象引用类型、原子化数组、原子化对象属性更新器和原子化的累加器。这五个类别提供的方法基本上是相似的,并且每个类别都有若干原子类,你可以通过下面的原子类组成概览图来获得一个全局的印象。
1. 原子化的基本数据类型
相关实现有 AtomicBoolean、AtomicInteger 和 AtomicLong,提供的方法主要有以下这些
1 getAndIncrement() // 原子化 i++ 2 getAndDecrement() // 原子化的 i-- 3 incrementAndGet() // 原子化的 ++i 4 decrementAndGet() // 原子化的 --i 5 //当前值+=delta,返回 += 前的值 6 getAndAdd(delta) 7 //当前值 +=delta,返回 += 后的值 8 addAndGet(delta) 9 //CAS操作,返回是否成功 10 compareAndSet(expect, update) 11 //以下四个⽅法 12 //新值可以通过传 func 函数来计算 13 getAndUpdate(func) 14 updateAndGet(func) 15 getAndAccumulate(x,func) 16 accumulateAndGet(x,func)
2.原子类底层用的是CAS自旋锁方案
打开任何一个源码,我们发现底层用的是unsafe的方法,而unsafe的方法又是被native修饰的,被native关键字修饰的方法叫做本地方法,本地方法和其它方法不一样,本地方法意味着和平台有关,另外native方法在JVM中运行时数据区也和其它方法不一样,它有专门的本地方法栈。native方法主要用于加载文件和动态链接库,由于Java语言无法访问操作系统底层信息(比如:底层硬件设备等),这时候就需要借助C语言来完成了。被native修饰的方法可以被C语言重写。

CAS中有经典的ABA问题,可参考之前的文章:CAS中的ABA问题 https://www.cnblogs.com/amberJava/p/12390939.html
实际上是用 AtomicStampedReference 和 AtomicMarkableReference 这两个原子类可以解决 ABA 问题
三、你可以编写自己原子类
根据上面的类结构图,使用 AtomicReference即可
public class SpinLock { private AtomicReference<Thread> sign =new AtomicReference<>(); public void lock(){ Thread current = Thread.currentThread(); while(!sign .compareAndSet(null, current)){ } } public void unlock (){ Thread current = Thread.currentThread(); sign .compareAndSet(current, null); } }