language-ai
文章AI伪原创,文章自动生成,NLP,自然语言技术处理,DNN语言模型,词义相似度分析。全网首个AI伪原创开源应用类项目。
点击右侧about内的链接极速体验!
代码托管在github,需要的可以自取:https://github.com/LovebuildJ/language-ai
快速开始
- 环境准备:
JDK1.8,maven3.6+,redis - 在
application.yml中配置百度AI的相关信息
baidu:
appid: 你的app_id
appkey: 你的app_key
secret: 你的app_secret
如何获取? 输入https://ai.baidu.com/tech/nlp_basic, 点击立即使用, 根据提示一步一步完成即可获得。
有免费调用额度, 对于个人而言已经够了。
3.启动项目, 前端页面访问 http://localhost:8080/ai,swagger文档访问http://localhost:8080/ai/doc.html
- 加载词库到redis中, 项目启动后, 发送post请求
http://localhost:8080/ai/command/initRedis初始化redis即可。该操作会将库清空再初始化,请悉知
请求参数格式如下:
{
"appName": "",
"params": {
"password": "你的用户名",
"username": "你的密码"
},
"sign": "",
"timestamp": "",
"version": ""
}
也可直接使用swagger执行接口初始化
测试版本未作校验, 所有参数默认为空即可。
项目截图
【词义分析】

【词义相似度计算】
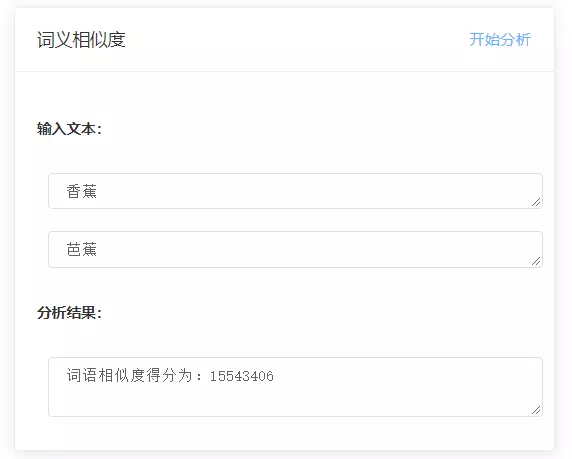
【DNN语言模型计算】

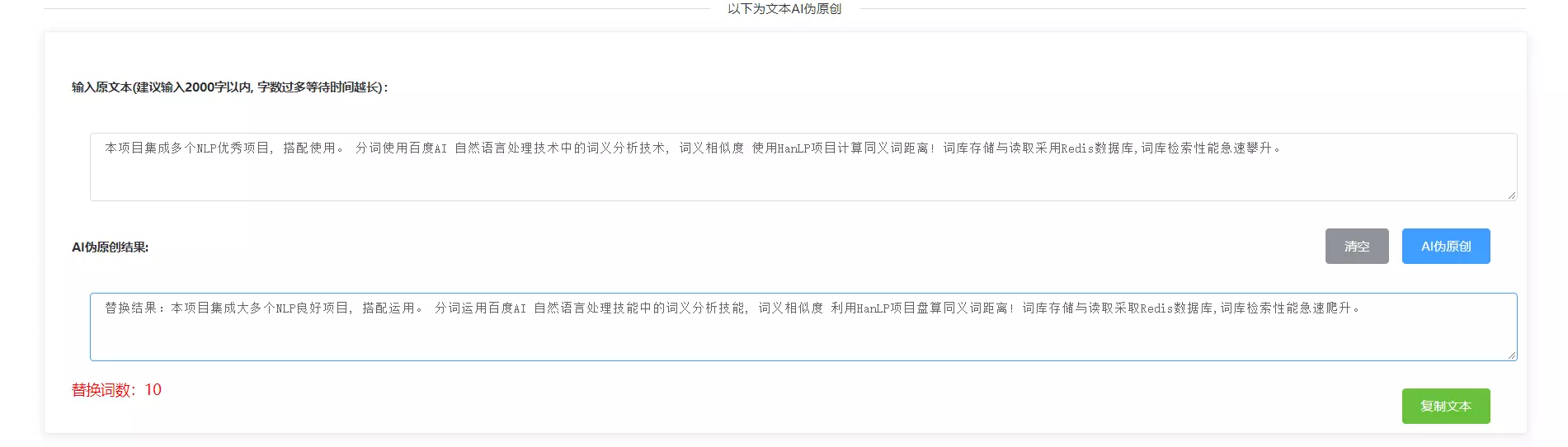
【AI伪原创】
【BootstrapSwaggerUI在线文档】
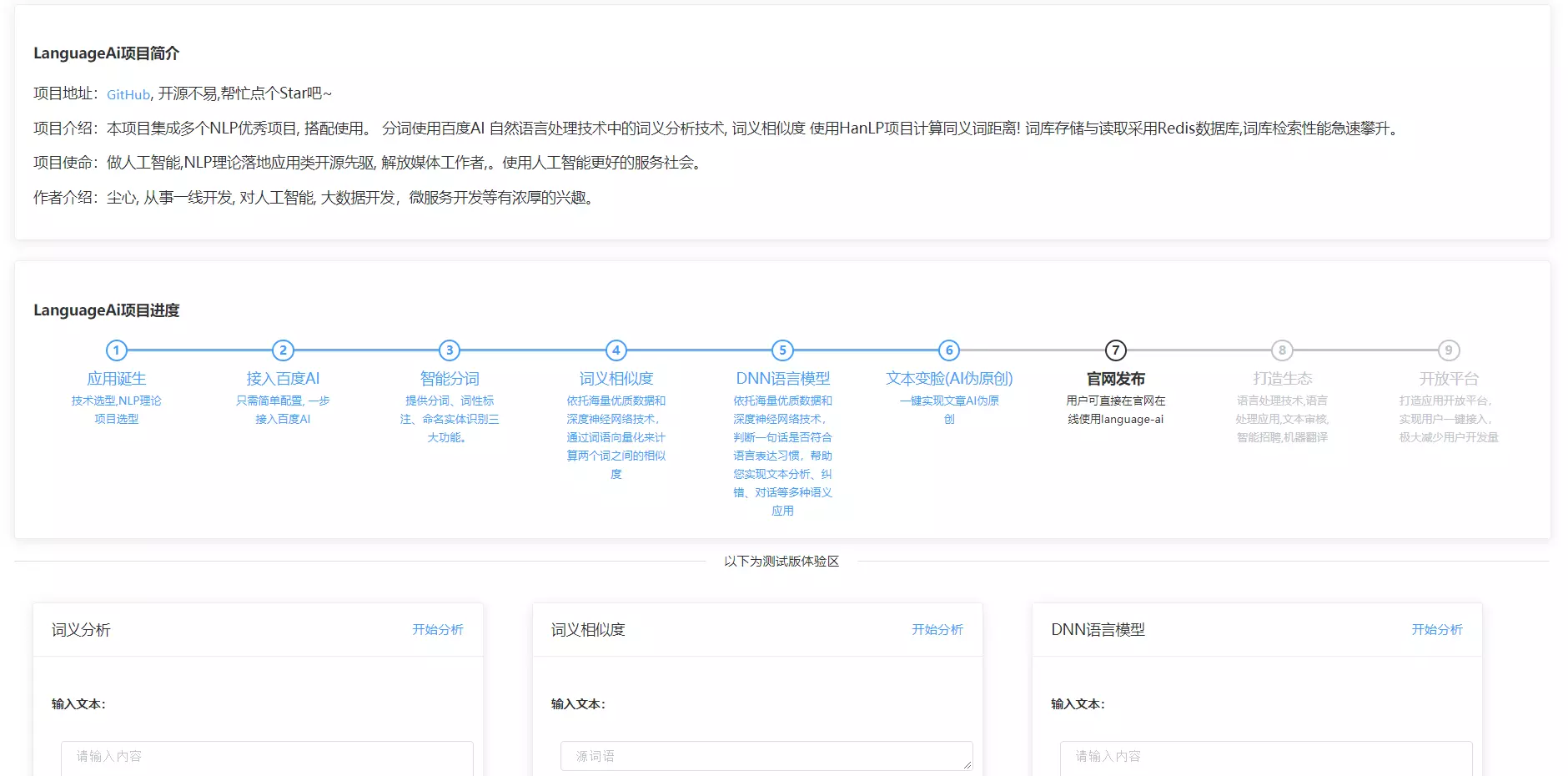
【首页】

源码目录详解
language-ai
|- src/main
| |- java java源码所在目录
| |- com.chenxin
| |- auth 百度AI授权认证模块
| |- base 基础公共抽象模块
| |- config 项目所有自定义配置模块
| |- controller 这个不用多说
| |- exception 全局异常与自定义一次模块
| |- model 项目所有使用的数据模型, dto,vo,bo等
| |- service 业务模块
| |- util 工具模块
| |- auth 授权认证模块
| |- consts 常量类
| |- http http相关
| |- nlp NLP同义词库加载工具
| |- system 系统相关
| |- CommonEnum.java 统一信息处理枚举类
|
| |- AiApplication.java 主启动类
|
|- src/test/java
|- com.chenxin 相关测试代码, 经验证, 若idea版本太低将会导致该单元测试无法使用
其他自行查看源码, 不一一概述
关于词库
- 使用到的中文同义词词库是哈工大的同义词词林(扩展版)
- 下载地址:https://www.ltp-cloud.com/download#down_cilin
- 项目自带词库(csdn下载的)
拓展词库
想要更加精确的计算与替换, 就需要一个很精准庞大的词库, 这个词库大家可以自己慢慢的补充完整
只需要将词库添加进文件resource/res/word.txt, 按照格式进行添加即可, 然后调用初始化redis接口即可。
初始化redis接口/ai/command/initRedis
关于词库中词语重复问题
这个大家无需担心, 作者在此方面做了大量优化。 相同键值Key的词组,将会全部存储至redis中,以Key0,Key1的形式存储,
查询时, 会将所有相同Key的词组全部找出, 并进行去重, 然后在进行其他操作, 计算词义相似度等等。相同的Key,为了提升
查询效率, 默认取相同Key的前20组!
技术图谱
本项目集成多个NLP优秀项目, 搭配使用。 分词使用百度AI 自然语言处理技术中的词义分析技术, 词义相似度
使用HanLP项目计算同义词距离!
自然语言处理技术(百度AI提供技术支持)
- 词义分析技术
- 词向量表示
- 词义相似度
- DNN语言模型
- 依存句法分析
- 短文本相似度
自然语言处理(hanLP提供技术支持)
HanLP是一系列模型与算法组成的NLP工具包,目标是普及自然语言处理在生产环境中的应用。
同义词词库
- 哈工大的同义词词林(扩展版)
技术架构
后端
- SpringBoot, 简单配置, 快速开发
- MyBatis , 复杂数据操作(轻量级版本无需数据库, 提高灵活性)
- Spring Data Jpa , 简单数据操作(轻量级版本无需数据库, 提高灵活性)
- SwaggerUI BootstrapSwaggerUI, 在线接口文档, 增强美化, 接口文档导出
- Redis 数据存储与缓存
- Async 异步多线程, 提升文章切割替换速度(单核cpu可能效果不太明显)
前端
本项目的页面只是简单作为测试, 后续会打造一个完整的产品网站。
- Vue
- ElementUI
问题与优化
- Q: 当文本长度稍微大一点的时候,文本变脸就变得十分缓慢, 因为这涉及到将几万的词库加载到内存然后进行词义距离计算
- A:这时候加载词库比对的思路,明显已经不适用了。因此采用高性能的redis数据库,进行词库的存储与读取,极大的提升了同义词的查找效率
- 优点 同义词精确匹配, 替换性能提升十几倍
- Q:只能有一组同义词, 例如 安分守己 - 循规蹈矩 和 循规蹈矩 - 安分守己。那 安分守己 - 诚实本分就添加不进词库。 初版先牺牲词库丰富性而达到高性能
- A: 现在已优化, 自动给同名键增加后缀, 后使用redis模糊查询进行匹配 (真正的性能和效率并存)
- Q:当文本过长,百度AI接口会抛出异常
- A:用户端或者服务端做好文本切片的操作
- Q: 当用户直接输入文章, 几千字如何处理?
- A: 根据文本大小进行切片, 采用异步多线程处理, 提升程序性能
- Q: 直接粘贴文章进行AI伪原创可能会报json注入异常
- A: 建议去掉空格, 回车等。或者换成转义字符。
关于作者
热衷于ai,分布式微服务,web应用,大数据等领域。工作室:1024代码工作室,有需求的可以联系作者哦,交流也是可以滴。
邮箱:amazingjava@163.com
其他
为什么会使用多个NLP项目, 原因是因为最初是想使用百度AI将整个项目完成。 但由于百度自然语言处理API
对于普通用户调用有次数限制, 超量需要收费, 因此数据量比较大的处理将给了HanLP项目处理。将数据量较小
的分词交给百度AI处理。
- 关于同义词库文件的位置, 不建议移动和改变, 文件夹以及名字都是。后续有时间, 再优化这个问题吧。