一、相同点
第一,LR和SVM都是分类算法(SVM也可以用与回归)
第二,如果不考虑核函数,LR和SVM都是线性分类算法,也就是说他们的分类决策面都是线性的。
这里要先说明一点,那就是LR也是可以用核函数的。总之,原始的LR和SVM都是线性分类器,这也是为什么通常没人问你决策树和LR什么区别,你说一个非线性分类器和一个线性分类器有什么区别?
第三,LR和SVM都是监督学习算法。
第四,LR和SVM都是判别模型。
这里简单讲解一下判别模型和生成模型的差别:
判别式模型(Discriminative Model)是直接对条件概率p(y|x;θ)建模。常见的判别式模型有线性回归模型、线性判别分析、支持向量机SVM、神经网络、boosting、条件随机场等。
举例:要确定一个羊是山羊还是绵羊,用判别模型的方法是从历史数据中学习到模型,然后通过提取这只羊的特征来预测出这只羊是山羊的概率,是绵羊的概率。
生成式模型(Generative Model)则会对x和y的联合分布p(x,y)建模,然后通过贝叶斯公式来求得p(yi|x),然后选取使得p(yi|x)最大的yi,即:
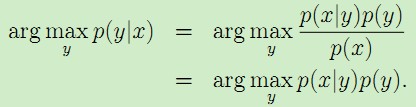
常见的生成式模型有 隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA、高斯、混合多项式、专家的混合物、马尔可夫的随机场
举例:利用生成模型是根据山羊的特征首先学习出一个山羊的模型,然后根据绵羊的特征学习出一个绵羊的模型,然后从这只羊中提取特征,放到山羊模型中看概率是多少,在放到绵羊模型中看概率是多少,哪个大就是哪个。
考虑这样一个例子,假设给定动物的若干个特征属性,我们希望通过这些特征学习给定的一个“个体”到底是属于“大象”(y=1)还是“狗”(y=0)
如果采用判别模型的思路,如逻辑回归,我们会根据训练样本数据学习类别分界面,然后对于给定的新样本数据,我们会判断数据落在分界面的哪一侧从而来判断数据究竟是属于“大象”还是属于“狗”。在这个过程中,我们并不会关心,究竟“大象”这个群体有什么特征,“狗”这个群体究竟有什么特征。
现在我们来换一种思路,我们首先观察“大象”群体,我们可以根据“大象”群体特征建立模型,然后再观察“狗”群体特征,然后再建立“狗”的模型。当给定新的未知个体时,我们将该个体分别于“大象”群体和“狗”群体模型进行比较,看这个个体更符合哪个群体模型的特征。
所以分析上面可知,判别模型是直接学习p(y|x) 或者直接从特征空间学习类别标签,生成分类决策面;生成模型是对类别模型进行学习,即学习p(x|y) (每一类别数据的特征模型)和p(y) (别类概率)。如在上面的例子中,对于“大象”群体,特征分布可以表示为p(x|y=1) ,对“狗”群体建立特征模型p(x|y=0) 假设类别概率分布p(y) 是已知的,那么我们可以通过贝叶斯公式,对给定数据特征x 的类别后验概率推导为,
第五,LR和SVM在学术界和工业界都广为人知并且应用广泛。
二、不同点
第一,本质上是其loss function不同
逻辑回归的损失函数:

支持向量机的目标函数:

逻辑回归方法基于概率理论,假设样本为1的概率可以用sigmoid函数来表示,然后通过极大似然估计的方法估计出参数的值
支持向量机基于几何间隔最大化原理,认为存在最大几何间隔的分类面为最优分类面
第二,支持向量机只考虑局部的边界线附近的点,而逻辑回归考虑全局(远离的点对边界线的确定也起作用,虽然作用会相对小一些)
SVM决策面的样本点只有少数的支持向量,当在支持向量外添加或减少任何样本点对分类决策面没有任何影响:
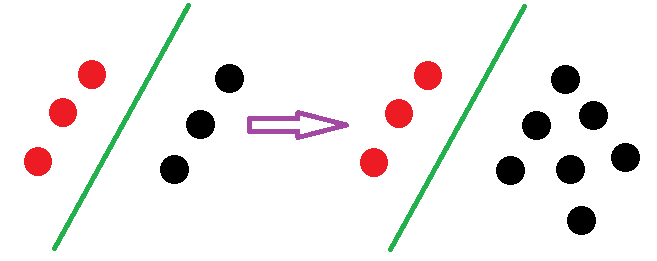
LR中,每个样本点都会影响决策面的结果。用下图进行说明:
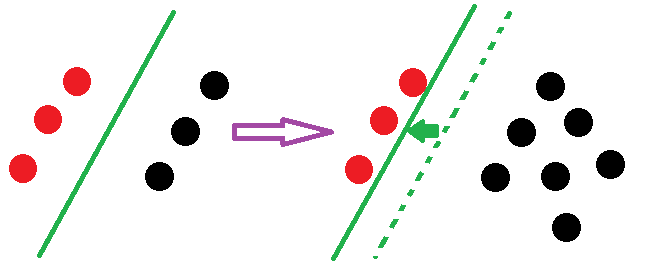
由上得知:线性SVM不直接依赖于数据分布,分类平面不受非支持向量点影响;LR则受所有数据点的影响,如果数据不同类别strongly unbalance,一般需要先对数据做balancing
第三,在解决非线性问题时,支持向量机采用核函数的机制,而LR通常不采用核函数的方法
这个问题理解起来非常简单。分类模型的结果就是计算决策面,模型训练的过程就是决策面的计算过程。通过上面的第二点不同点可以了解,在计算决策面时,SVM算法里只有少数几个代表支持向量的样本参与了计算,也就是只有少数几个样本需要参与核计算。然而,LR算法里,每个样本点都必须参与决策面的计算过程,也就是说,假设我们在LR里也运用核函数的原理,那么每个样本点都必须参与核计算,这带来的计算复杂度是相当高的。所以,在具体应用时,LR很少运用核函数机制
第四,线性SVM依赖数据表达的距离测度,所以需要对数据先做normalization,LR不受其影响
一个基于概率,一个基于距离!
第五,SVM的损失函数就自带正则!!!(损失函数中的1/2||w||^2项),这就是为什么SVM是结构风险最小化算法的原因!!!而LR必须另外在损失函数上添加正则项!!!
所谓结构风险最小化,意思就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,从而达到真实误差的最小化。未达到结构风险最小化的目的,最常用的方法就是添加正则项,SVM的目标函数里居然自带正则项!!!