题目
现有用户点击行为数据文件,每天产生会上传到hdfs目录,按天区分目录,现在我们需要每天凌晨两点定时导入Hive表指定分区中,并统计出今日活跃用户数插入指标表中。
日志文件(clicklog)
userId click_time index uid1 2020-06-21 12:10:10 a.html uid2 2020-06-21 12:15:10 b.html uid1 2020-06-21 13:10:10 c.html uid1 2020-06-21 15:10:10 d.html uid2 2020-06-21 18:10:10 e.html
说明:用户点击行为数据,三个字段是用户id,点击时间,访问页面
hdfs目录会以日期划分文件,例如
/user_clicks/20200621/clicklog.dat /user_clicks/20200622/clicklog.dat /user_clicks/20200623/clicklog.dat ...
Hive表
原始数据分区表
create table user_clicks(id string,click_time string ,index string) partitioned by(dt string) row format delimited fields terminated by ' ' ;
需要开发一个import.job每日从hdfs对应日期目录下同步数据到该表指定分区。(日期格式同上或者自定义)
指标表
create table user_info(active_num string,dateStr string) row format delimited fields terminated by ' ';
需要开发一个analysis.job依赖import.job执行,统计出每日活跃用户(一个用户出现多次算作一次)数并插入user_inof表中。
需求
开发以上提到的两个job,job文件内容和sql内容需分开展示,并能使用azkaban调度执行。
实现
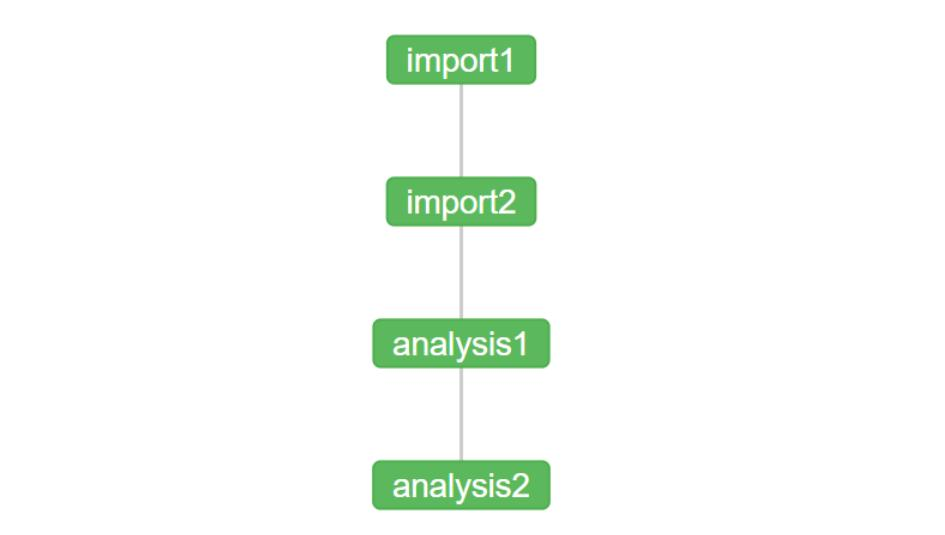
import1.job
type=command
command=/usr/bin/sh /root/job/import.sh
import.sh
前面一段有一个时间处理来模拟不同天份的执行,通过返回日期,通过load data到指定的日起目录,将上游的点击数据input到指定表homework.user_clicks的对用分区中,将SQL写为文件提供给import2.job调度。
#!/bin/bash time=$(date "+%M") sub=$[$time/3] if [ $sub -eq 0 ];then echo "$sub, 20200621" dt="20200621" elif [ $sub -eq 1 ];then echo "$sub, 20200622" dt="20200622" else dt="20200623" echo "$sub, 20200623" fi sql='load data inpath "/data/'$dt'/clicklog.dat" into table homework.user_clicks PARTITION(dt='$dt');' echo $sql > /root/job/import.sql
import2.job
依赖于import1的完成,通过hive -f命令完成装数
type=command dependencies=import1 command=nohup /opt/hive/hive-2.3.7/bin/hive -f /root/job/import.sql > /root/job/import.log &
analysis1.job
依赖于import2的完成生成对应的SQL文件
type=command dependencies=import2 command=/usr/bin/sh /root/job/analysis.sh
analysis.sh
#!/bin/bash time=$(date "+%M") sub=$[$time/3] if [ $sub -eq 0 ];then echo "$sub, 20200621" dt="20200621" elif [ $sub -eq 1 ];then echo "$sub, 20200622" dt="20200622" else dt="20200623" echo "$sub, 20200623" fi sql="insert into table homework.user_info select count(distinct id),'$dt' from homework.user_clicks where dt='$dt'" echo $sql > /root/job/analysis.sql
analysis2.job
依赖于analysis1.job对已装载的数据进行数据汇总,并插入到homework.user_info汇总表中。
type=command dependencies=analysis1 command=nohup /opt/hive/hive-2.3.7/bin/hive -f /root/job/analysis.sql > /root/job/analysis.log &
备注:
任务依赖关系: