#下面建立game表,设置name值为唯一索引。 CREATE TABLE `game` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) CHARACTER SET utf8 NOT NULL, `type_id` tinyint(4) NOT NULL DEFAULT '0', `attr` varchar(20) NOT NULL, `type_extends` varchar(20) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `name` (`name`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4

对于ON DUPLICATE KEY UPDATE语句:
MySQL手册:如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE。
这里的意思是说要设置记录不存在就添加存在就更新,必须在添加这个记录的时候唯一索引和主键发生相同才能触发。
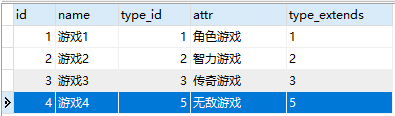
#当我们试图插入一条已经存在的唯一索引name值记录,提示:[Err] 1062 - Duplicate entry '游戏4' for key 'name' INSERT INTO game SET `name`='游戏4',`type_id`='5',`attr`='无敌游戏',`type_extends`='5' #下面是使用ON DUPLICATE KEY UPDATE,如果插入记录的时候存在唯一索引和主键重复的记录,那么就执行更新操作 INSERT INTO game SET `name`='游戏4',`type_id`='5',`attr`='无敌游戏',`type_extends`='5' ON DUPLICATE KEY UPDATE `type_id`='5',`attr`='无敌游戏',`type_extends`='5'
对于使用ON DUPLICATE KEY UPDATE子句如果记录不存在执行添加那么影响行数是一行,如果存在进行更新,如果更新发现没有变化那么影响行数为0,否则影响行数是两行。
对于REPLACE INTO语句
MSQL手册:REPLACE的运行与INSERT很相像。只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除。
注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义。该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行。
意思是说,对于REPLACE INTO语句如果发现存在记录那么先将记录删除在插入新记录。
表中原有记录是:
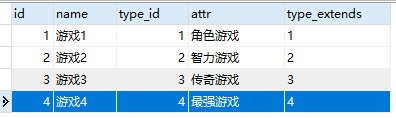
#运行语句: REPLACE INTO game SET `name`='游戏4',attr='最强的游戏2',type_extends='最强的游戏2_4'
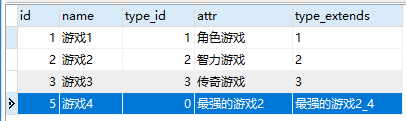
这里的id是设置自动增长主键,这里有两处特别的地方,1是自动增长的id变大了,2是type_id变成0了
在MySQL手册:所有列的值均取自在REPLACE语句中被指定的值。所有缺失的列被设置为各自的默认值,这和INSERT一样。您不能从当前行中引用值,也不能在新行中使用值。如果您使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
这里意思是说在REPLACE语句中没有设置的列会被设置成默认值,这里的type_id的默认值是0所以这里被设置成0了,这里也很好理解,因为REPLACE语句是先删除后插入了,而新插入数据如果没有设置值那么就是默认值了。所以下面的语句得到的结果也是不是预期的结果:
#这里的语句得到的结果type_id为1,因为type_id默认值为0。这里的type_id=type_id+1相当于type_id=DEFAULT(type_id) +1
REPLACE INTO game SET `name`='游戏4',type_id=type_id+1,attr='最强的游戏2',type_extends='最强的游戏2_4'
对于REPLACE INTO语句如果记录不存在那么执行添加影响行数为一行,否则执行删除后添加影响行数为两行。
对于存在记录就修改,不存在就添加记录的处理ON DUPLICATE KEY UPDATE和REPLACE INTO语句的区别:
ON DUPLICATE KEY UPDATE语句:是根据主键或者唯一索引判断是否存在记录,如果存在记录那么通过UPDATE子句更新记录内容,只更新UPDATE子句中设置的字段,对于没有设置的字段保持原状,因为是修改语句所以不会对自动增长字段做变化。
语句的返回值有:
0:发现有相同的唯一索引或者主键的记录,执行更新语句,但是更新语句中的字段内容和现有的字段内容一致执行结果没有发生变化;
1:发现没有相同的唯一索引或者主键的记录,直接执行插入语句;
2:发现有相同的唯一索引或者主键的记录,执行更新语句,并且更新语句中的字段内容和现有的字段内容一致执行结果发生变化;
REPLACE INTO语句:是根据主键或者唯一索引判断是否存在记录,如果存在记录那么就删除记录然后将当前语句中的字段内容执行INSERT。因为是删除后再INSERT,所以对自动增长字段做变化。
语句的返回值有:
1:发现没有相同的唯一索引或者主键的记录,直接执行插入语句;
2:发现有相同的唯一索引或者主键的记录,先删除指定语句再进行INSERT语句,这里要注意在执行INSERT的时候如果在REPLACE INTO语句中没有设置的字段那么就会是以默认值填充;
对于ON DUPLICATE KEY UPDATE语句在MySQL手册中有这样一句:
在一个INSERT … ON DUPLICATE KEY UPDATE …语句中,你可以在UPDATE 子句中使用 VALUES(col_name)函数,用来访问来自该语句的INSERT 部分的列值。换言之,UPDATE 子句中的 VALUES(col_name) 访问需要被插入的col_name 的值,并不会发生重复键冲突。
原表中数据:

INSERT INTO game SET `name`='游戏4',`type_id`='4',`attr`='无敌游戏',`type_extends`='无敌游戏_4' ON DUPLICATE KEY UPDATE `type_extends`=CONCAT(VALUES(attr),'_',VALUES(type_id))
结果数据:
