这篇论文发表在 2018 年的 ACL 上
Motivation
针对情感转换任务(也相当于是翻译的一种)无平行语料,提出了一种循环强化学习方法,该方法可以通过中和模块和情感模块之间的协作来训练未配对的数据,来提升转换后句子的语义内容保存
Method
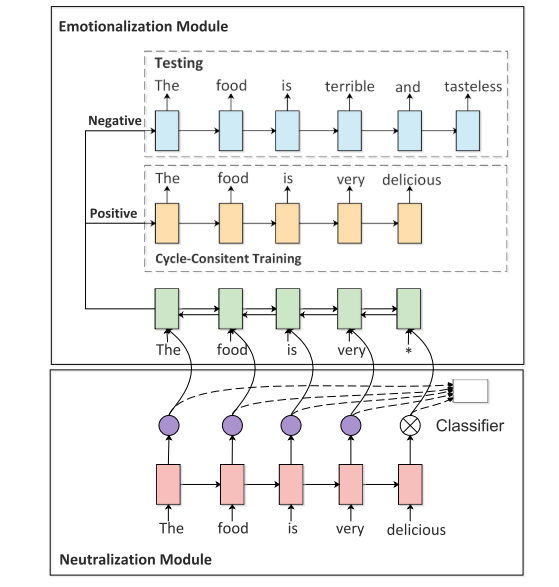
作者提出的模型结构包括两部分:
-
Neutralization
这个模块提取非情感部分的句子(即语义内容),再喂给情感模块
使用Nθ来显式过滤掉情绪信息,那么如何来分辨出情感词呢?
作者提出了一种新颖的预训练方法来让中和模块学习如何识别非情感单词,构造了一个基于 self-attention 的情感分类器,并将学习到的注意权重用作监督信号。在训练好的情感分类器中,注意力权重在一定程度上反映了每个单词的情感贡献,情感词倾向于获得更高的关注权重,而中性词通常获得更低的权重。
输入:句子序列 x
[y=softmax(W·c) ]输出:sentiment 标签 y ∈(0, 1)
W 是参数矩阵,c 为隐藏层向量的加权和
[c=sum_{i=0}^{T}{a_ih_i} ]其中 α_i 是 h_i 的权重, h_i是 LSTM 的第 i 个单词的输出
[a_i=frac{exp(e_i)}{sum_{i=0}^{T}{exp(e_i)}} ]e_i 是由一个对齐模型所产生,用来评估每个单词对情感分类的贡献
[e_i=f(h_i,h_T) ]h_T 表示上下文向量,包含输入的所有信息
计算 a_i 的均值 ,并用它来作为阈值区分情感词和非情感词
[a^-=frac{1}{T}sum_{i=0}^{T}{a_i} ]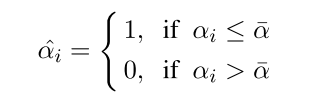
预训练-损失函数(交叉熵):
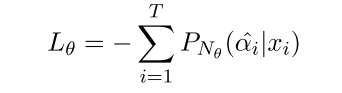
-
Emotionalization
生成情感词加到语义内容上
本文中作者基于 encoder-decoder 框架使用双解码器(LSTM),一个用于 positive sentiment,另一个用于 negative sentiment,使用哪一个取决于源始句子的sentiment。
(这个时候还没有进行情感转换,应该是一个重构的过程:有监督)
预训练-损失函数(交叉熵):

Cycled Reinforcement Learning
预训练好后,作者使用强化学习的 Policy Gradient 算法来训练中和模块。
-
通过中和模块生成不带情感的句子 (x --> x')
-
通过情感模块生成原句子(重构 (x', s) --> x)
-
计算情感模块的梯度
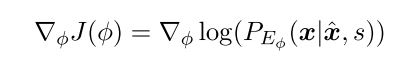
-
计算 R1
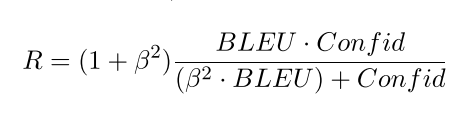
confid 是用来评价转换后的句子是否是目标句子(即分类器分类正确)
β is a harmonic weight (文中设置为 0.5)
在情感模块上,除了重构外还使用与原始句子相反的情感标签来生成目标句子
-
通过情感模块生成风格相反的句子((x’,s')--> (x,s))
-
计算 R2
-
计算 Rc = R1 + R2
-
计算中和模块的梯度(使其能更好地区分情感词,也能促进情感模块)
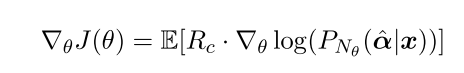
Policy Gradient:不通过误差反向传播,它通过观测信息选出一个行为直接进行反向传播,当然出人意料的是他并没有误差,而是利用reward奖励直接对选择行为的可能性进行增强和减弱,好的行为会被增加下一次被选中的概率,不好的行为会被减弱下次被选中的概率
模型结构:
Dataset
- Yelp Review Dataset (Yelp)
- Amazon Food Review Dataset(Amazon)
baselines: Cross-Alignment Auto-Encoder (CAAE)(shen et al. 2017)
Multi-Decoder with Adversarial Learning (MDAL)(Fu et al. 2018)
Evaluation Metrics:
-
Automatic Evaluation
ACC、BLEU、G-score(几何平均数)
-
Human Evaluation
score 1-10