考虑到可移植性的问题,现代版本的Linux内核的可移植性是非常好的。
在把x86上的代码移植到新的体系架构上时,内核开发人员遇到的若干问题都和不正确的数据类型有关。坚持使用严格的数据类型,并且使用-Wall -Wstrict -prototypes选项编译可以防止大多数的代码缺陷。
内核使用的数据类型分成三大类:
- 类似int这样的标准C语言类型
- 类似u32这样的有确定大小的类型
- 像pid_t这样的用于特定内核对象的类型
一、使用标准C语言类型
尽管多数程序员习惯于使用像int和long这样的标准类型,编写涉笔驱动程序时需要小心,以避免缺陷。
普通C语言的数据类型所占空间的大小并不相同。
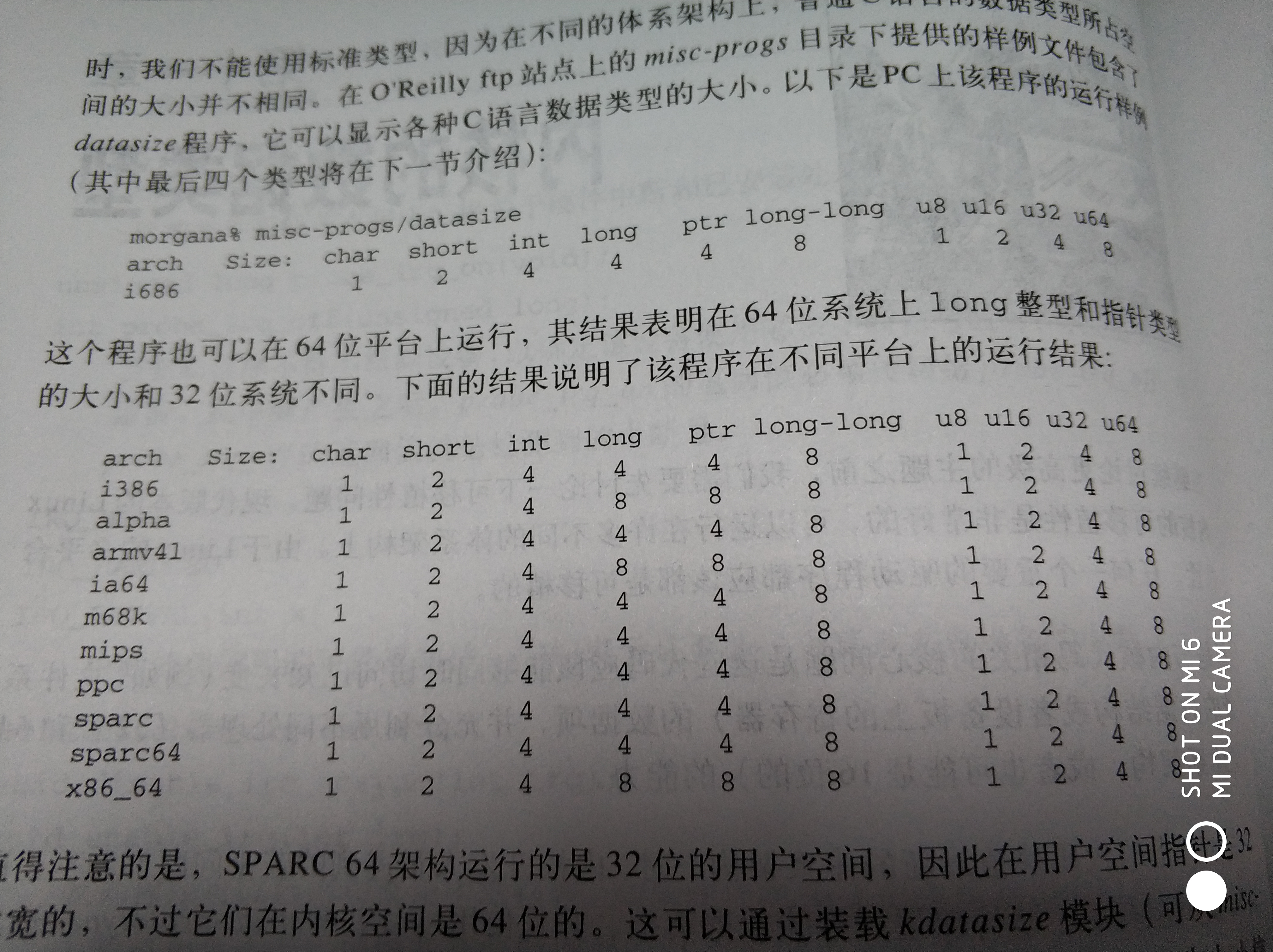
二、为数据项分配确定的空间大小
当我们需要知道自己的数据大小时,内核提供了下列数据结构。


#include <asm/types.h> u8; /* 无符号字节(8位) */ u16; /* 无符号字(16位) */ u32; /* 无符号32位值 */ u64; /* 无符号64位值 */
如果用户空间需要使用,需要在名字前面加两个下划线作为前缀,如__u8。
在C99标准中,有例如uint8_t和uint32_t,如果考虑到可移植性,可以使用这些而不是linux特有的变种。
接口特定的类型
内核汇总最常用的数据类型由他们自己的typedef声明,这样可以防止出现任何移植性问题。
其他有关移植性的问题
一个通用的原则是要避免使用显示的常量值。
时间间隔
不要假定每秒一定有100个jiffies,需要用HZ进行转化。
页大小
内存页的大小为PAGE_SIZE,而不是4KB。
#include <asm/page.h> int order = get_order(16*1024); buf = get_free_pages(GFP_KERNEL, order);
字节序
尽管PC是按照小端存储的,但某些高端平台是大端存储的。
#include <asm/byteorder.h>
u32 cpu_tole32(u32);
u32 le32_to_cpu(u32);
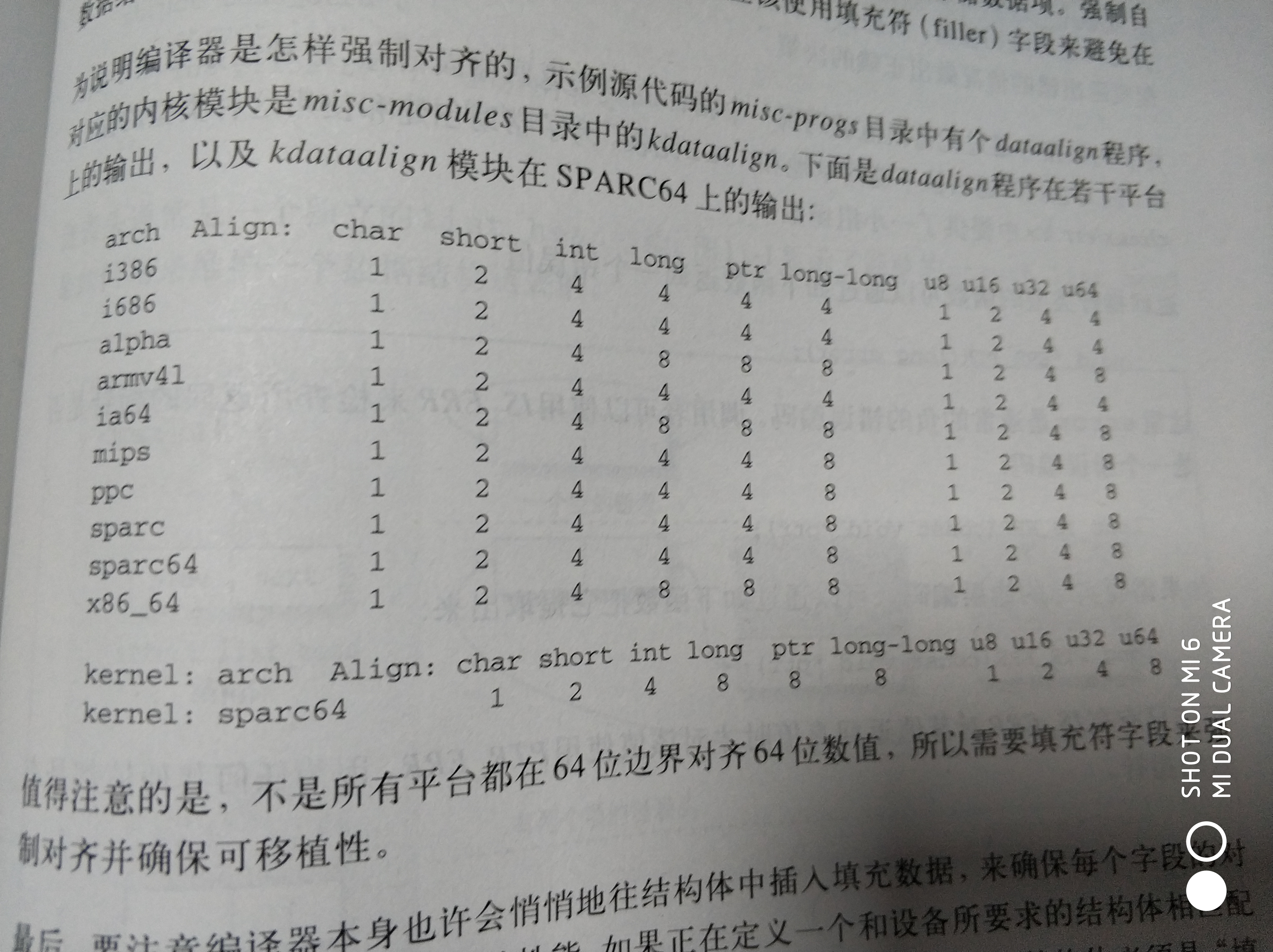
数据对齐
大部分现代体系架构在每次程序试图传输未对齐的数据时都会产生一个异常。数据传输会被异常处理程序处理,这样会带来大量的性能损失。访问未对齐的数据,应该使用下面的宏
#include <asm/unaligned.h>
get_unaligned(ptr);
put_unaligned(va, ptr);
为了编写可以在不同平台之间可移植的数据项的数据结构,除了规定特定的字节序以外,还应该时钟强制数据项的自然对齐。
自然对齐是指数据项大小的整数倍的地址处存储数据项。强制自然对齐可以防止编译器移动数据结构的字段,应该填充符字段来避免在数据结构中留下空洞。
指针和错误值
大部分情况,失败是通过返回一个NULL指针值来表示的。这样尽管有用,但不能传递问题的确切性质。某些接口确实需要返回一个实际的错误编码。
#include <linux/err.h> void *ERR_PTR(long error); error:是通常的负的错误编码 long IS_ERR(const void *ptr); 检查所返回的指针是否是一个错误编码 long PTR_ERR(const void *ptr); 只有IS_ERR为真时,才对该指针使用PTR_ERR
链表
内核开发者建立了一套标准的循环、双向链表的实现。
如果驱动程序试图对同一个链表执行并发操作,有责任实现一个锁。否则,崩溃的链表结构体、数据丢失、内核混乱等问题是很难诊断的。
#include <linux/list.h> struct list_head { struct list_head *next, *prev; }; /* 使用方法 */ struct todo_struct { struct list_head list; int priority; /* 驱动程序特定的 */ /* ... 增加其他驱动程序特定的字段 */ };
在使用之前必须用INIT_LIST_HEAD宏来初始化链表头,使用方法:
struct list_head todo_list; INIT_LIST_HEAD(&todo_list); /* 另外可在编译时想这样初始化链表 */ LIST_HEAD(todo_list);
然后是操作函数:
#include <linux/list.h> list_add(struct list_head *new, struct list_head *head); /* 在链表头后面添加新项,通常是链表头部,可以用来建立栈 */ list_add_tail(struct list_head *new, struct list_head *head); 在给定链表表头的前面添加一个新的项,即在链表的末尾处添加 */ list_del(struct list_head *entry); list_del_init(struct list_head *entry); /* 删除链表中的给定项 */ list_move(struct list_head *entry, struct list_head *head); list_move_tail(struct list_head *entry, struct list_head *head); /* 把给定项移动带链表开始处 */ list_empty(struct list_head *head); /* 如果给定的链表为空,返回非0值 */ list_splice(struct list_head *list, struct list_head *head); /* 通过head之后插入list来合并两个链表 */
可利用list_entry宏将要给list_head结构指针映射会指向包含它的大结构的指针
list_entry(struct list_head *ptr, type_of_struct, field_name);
类似下面的代码行,将一个链表项转换成包含它的结构:
struct todo_struct *todo_ptr = list_entry(listptr, struct todo_struct, list);
假设我们想让todo_struct链表中的项按照优先级降序排列,则增加新项的函数如下:
void todo_add_entry(struct todo_struct *new) { struct list_head *ptr; struct todo_struct *entry; for(ptr = todo_list.next; ptr != &todo_list; ptr = ptr->next) { entry = list_entry(ptr, struct todo_struct, list); if(entry->priority < new->priority) { list_add_tail(&new->list, ptr); return; } } list_add_tail(&new->list, &todo_struct); }
作为一个惯例,最好使用一组预定义的宏来创建可以遍历链表的循环。
void todo_add_entry(struct todo_struct *new) { struct list_head *ptr; struct todo_struct *entry; list_for_each(ptr, &todo_list) { entry = list_entry(ptr, struct todo_struct, list); if(entry->priority < new->priority) { list_add_tail(&new->list, ptr); return; } } list_add_tail(&new->list, &todo_struct); }
有一些函数变体,如下:
list_for_each(struct list_head *cursor, struct list_head *list) 宏创建一个for循环,每当游标指向链表中的下一项时执行一次 list_for_each_prev(struct list_head *cursor, struct list_head *list) 向后遍历链表 list_for_each_safe(struct list_head *cursor, struct list_head *next, struct list_head *list) 如果循环可能会删除链表汇总的项,就应该使用该版本 list_for_each_entry(type *cursor, struct list_head *list, member) list_for_each_entry_safe(type *cursor, type *next, struct list_head *list, member) 这些宏使处理一个包含给定类型结构体的链表时更加容易