
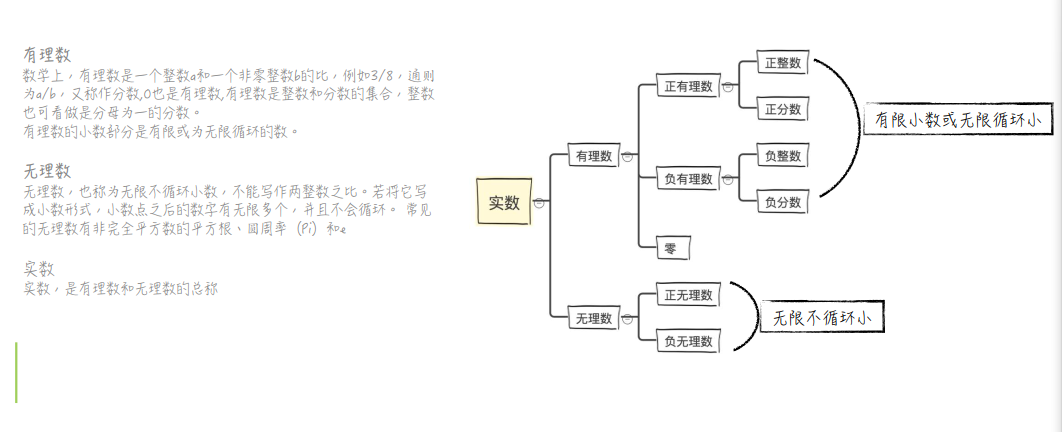
浮点数
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数的整数次幂得到,这种表示方法类似于基数为10的科学计数法

列表
列表是一个数据的集合,集合内可以放任何数据类型,可以对集合进行方便的增删改查操作
有序的 可变的
1.创建
#方法1 L1 = []#定义空列表 L2 = ['a','b','c','d']#存4个值,索引为0-3 L3 = ['abc',['def','ghi']]#嵌套列表 #方法2 L4 = list() print(L4)
2.查询
L2 = ['a','b','c','d','a','e',1,2] L2[2]#通过索引取值 c L2[-1]#通过索引从右边开始取值 2 L2[-2] 1 L2.index('a')#返回指定元素的索引值,从左右查找,找到第一个匹配值,则返回 0 L2.count('a')#统计指定元素的个数 2
3.切片
L2 = ['a','b','c','d','a','e',1,2] L2[0:3]#返回从索引0至3的元素,不包括3,顾头不顾尾 L2[0:-1]#返回从索引0至最后一个值,不包括最后一个值 L2[3:7]#返回从索引3至6的元素 L2[3:]#返回从索引3至最后所有的值 L2[:3]#返回从索引0至3的值 L2[1:7:2]#返回索引1至6的值,但是步长为2 L2[:]#返回所有值 L2[::2]#按步长2返回所有值
4.增加
L2 = ['a','b','c','d','a','e',1,2] L2.append('A')#列表最后面追加A >>['a', 'b', 'c', 'd', 'a', 'e', 1, 2, 'A'] L2.insert(3,'B')#在列表的索引3的位置插入一个值B >>['a', 'b', 'c', 'B', 'd', 'a', 'e', 1, 2, 'A']
5.修改
L2 = ['a','b','c','d','a','e',1,2] L2[6] = 'Boy'#把索引3改成Boy >>['a', 'b', 'c', 'd', 'a', 'e', 'Boy', 2] L2[1:5]='Mahoro'#把索引1-5的元素改为Mahoro,不够的元素自动增加 >>['a', 'M', 'a', 'h', 'o', 'r', 'o', 'e', 'Boy', 2]
6.删除
L2.pop()#删除最后一个元素 L2.remove('a')#删除从左找到的第一个指定元素 del L2[2]#用python全局的删除方法删除指定元素 del L2[3:7]#删除多个元素
7.循环
for i in L2: print(i)
有的时候需要用for发起一个循环,但是没有用列表 这时候就可如下
for i in range(10): print(i)
while 和 for循环的最大区别,while可以是死循环,while True
而for循环需要有边界
8.排序
列表是有序的,根据索引来
L2 = ['a','b','c','d','A','a','!','e','$','K'] L2.sort()#需要同类型 不能str和int 排列顺序是根据ASCII顺序来排 >>['!', '$', 'A', 'K', 'a', 'a', 'b', 'c', 'd', 'e']
9.其他
合并 L1.extend(L2)
清空 L2.clear()
拷贝 L1 = L2.copy() 此时L1,L2是独立的
如果用 = ,L1,L2 指向同一内存地址(引用)
代码说明
#变量是独立
a = 1 b = 2 c=a a=4 print(c) >>1
n1 = [1,2,3] #1 n2 = n1 #2 n2[0] = 'X' #3 print('n1 = ',n1) print('n2 = ',n2) >>n1 = ['X', 2, 3] >>n2 = ['X', 2, 3] #列表和变量不同,当你将列表赋给一个变量时,实际上是将该列表的“引用”赋给了该变量。引用是一个值,指向某些数据。 #列表的引用是指向一个列表的值。 #当创建列表时(1),你将对他的引用赋给了变量。但是下一行(2)只是将n1中的列表引用 拷贝到n2,而不是列表值本身。 #这意味着存储在n1和n2中的值,现在指向了同一个列表,因为列表本身实际从未复制。所以当修改n2的值时候(3),也修改了n1指向的同一个列表
需要完全独立两个列表就需要用到.copy()方法
深层次完完全全独立 需要.deepcopy()方法 需要import copy
数据类型-字符串
字符串是一个有序的字符的集合,用于存储和表示基本的文本信息,一对单、双、或三引号中间包含的内容称为字符串
创建:
s = 'hello world'
特性:有序 不可变
改变变量值实际上是改变了内存地址,并不是改变原字符串
字符串操作:
s = "hello world" print(s.swapcase()) s.capitalize() #首字母大写 其他小写 s.casefold() #统一进行小写 s.center(50,'*')#放中间,其他用*代替 s.count("0")#统计有几个0 s.count('o',0,5)#从0到5统计有几个o s.endswith("ads")#判断以什么结尾 s.expandtabs()#扩展tab键 把默认长度边长 s.find('x')#查询一个值,返回索引,没有返回-1 #格式化输出1 s3 = ' my name is {0},i am {1} years old' s3.format('alex',22) #格式化输出2 s3 = ' my name is {name},i am {age} years old' s3.format(name = 'alex',age = 22) #格式化输出3 name = 'alex' age = 18 s3 = 'my name is %s ,i am %s years old'%(name,age) print(s3) name.index('l',1,3)#返回索引 '22b'.isalnum()#是不是阿拉伯数字或字母 'dd'.isalpha()#是不是阿拉伯字母 '22'.isdecimal()#是不是整数 '22'.isdigit()#是不是整数 name.isidentifier()#判断是不是一个合法变量名 'a'.islower()#是不是小写 '123'.isnumeric()#是不是只有数字在里面 '33'.isprintable()#是不是可以打印 ' '.isspace()#是不是空格 'abc'.istitle()#看是不是标题,首字母大写 'ABC'.isupper()#是不是大写 #将列表转换为字符串方法 list1 = ['hello','my','friend'] '-'.join(list1) #.之前是所用分隔符,结果是'hello-my-friend' s.ljust(50,'-')#从左边开始,将字符串变成长度50,剩余用-补充 如果本身长度超过50则没有-,显示全部字符串 s.rjust()#从右边开始 # s.rjust() s.lower()#转小写 s.upper()#转大写 s.strip()#去掉首尾空格,换行,tab # s.lstrip() # s.rstrip() # str_in = 'abcdef' str_out = '!@#$%^' table = str.maketrans(str_in,str_out) #结果:{97: 33, 98: 64, 99: 35, 100: 36, 101: 37, 102: 94} #一张对应表 s.translate(table) #通过以table为翻译版对table进行加密 s.rpartition()#从右边开始 s.partition('0')#以0为中心(第一个)将字符串隔两半 ('hell','o',' world') s.replace('h','H',1)#替换 需要替换的值 新值 从左开始替换几个(默认全部替换) s.rfind()#从右边开始找, 找不到-1 s.find()#从左边开始找 找不到-1 s.rindex()#从右边找,找不到报错 s.split('o',1) #按o进行分割,o就没了 分割几次 s.splitlines()#按行来分 s.startswith("he")#判断以什么开始 s.endswith("")#判断以什么结束 s.swapcase()#大小写互换 s.title()#改成title #常用的:isdigit replace find count index strip center split format join #注意以下代码: s = 'abcd' s.upper() print(s) #>>'abcd'
元组tuple
和列表类似,但是一旦创建,不能修改 ,又称为 只读列表
列表用[] 元组用()
names = ('alex','jack','ben')
不能修改,但能切片(实际上切片就是获取数据)
元组中有列表,列表是可以改的
元组 用处 :1.配置信息等 不让修改
hash
翻译成散列,哈希,就是把任意长度的输入,通过散列算法,变成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能送散列值来唯一的确定输出值。简单地说就是一种将任意长度的消息压缩到某一固定长度的小心摘要的函数
特征:
hash值的 计算过程是一句这个值的一些特征计算的,这就要求被hash的值必须固定,因此被hash的值必须是不可变的
数字 字符串 元组 是不可变的
列表可变
数据类型-字典
字典是一种key-value的数据类型
特性:
1.key-value结构 key必须可hash,且必须为不可变数据类型,必须唯一 >>>>>>类似于 但不是:通过hash 变成数值,进行排序后查询 对折查询 大大减少搜索次数。二分查找
2.可存放任意多个值、可修改、可以不唯一
3.无序
4.查找速度快
info = { 'stu1':'alex', 'sut2':'ben', 'stu3':'jack', }
增加
info['stu4']='武藤兰'
修改
info['stu1']='苍井空'
查找
'stu1' in info#标准用法 info.get('stu1')#获取 没有就返回none info['stu1']#有返回 没有报错
删除
info.pop('stu1') #删除指定值并返回该值 info.popitem()#随即删除 del info['stu1']#del方法删除
其他方法
info.clear()$#清空 info.keys()#所有key 列表 info.values()#所有值,列表 info.items()#字典转列表 key和value变成元组,塞入一个列表里 info.update(dic2)#合并两个字典,若有重复,dic2里的覆盖info的 有覆盖,没创建 info.setdefault(key,value)#如果字典有key,则返回已存在的value,如果字典没有这个key,则创建这个key:value info.fromkeys(['a','b','c'])#生成一个字典,key是a,b,c,value是None
循环
for k in info:#常用,高效 print(k,info[k]) for k,v in info.items():#不常用,低效,因为转换成了列表,查询速度慢 print(k,v)
集合
集合是一个无序的,不重复的数据组合,作用:
1.去重,把一个列表变成集合,就自动去重了
2.关系测试,测试两组数据之前的交集、差集、并集等关系
s= {} >>>type:dict
s={1} >>>type:set
列表:list 元组:tuple 字典:dict 集合:set
集合元素的三个特性
1.确定性,元素必须可以hash
2.互异性,去重
3.无序性(元素没有先后之分){1,2,3} == {3,2,1}
#列表转集合 li = [1,2,2,3] set(li) >>{1,2,3}#自动去重
常用方法:
#增加 一样的放不进去 只能放一个 s.add(2) #删除 随即删除 s.pop() #指定删除 没有就报错 s.remove(2) #丢弃 没有不报错 s.discard(6) #增加多个值 (元组,集合,列表) s.update([1,2,3]) #清空 s.clear()
集合关系测试
s1 = {1,2,3,4}
s2 = {3,4,5,6}
#交集
s1.intersection(s2)
s1 & s2
#差集
s1.difference(s2)
s1 - s2
#并集
s1.union(s2)
s1 | s2
#对称差集
s1.symmetric_difference(s2)
s1^s2
#包含关系
#两个集合有三种关系,相交,包含,不相交
s1.isdisjoint(s2)#判断两个集合是否 不相交
s1.issuperset(s)#判断集合是不是包含其他集合,a>=b
s1.issubset(s)#判断集合是不是被其他集合包含,a<=b