1、数据来源:腾讯大数据平台/宜出行大数据
2、爬取方式: 获取基础行政区基础数据,根据范围经纬度进行数据爬取。
3、爬取过程:获取腾讯大数据请求地址,根据相关参数进行数据解析。
核心代码:
def get_TecentData(count=4,rank=0): #先默认为从rank从0开始 url='https://xingyun.map.qq.com/api/getXingyunPoints' #来源星云平台 locs='' paload={'count':count,'rank':rank} response=requests.post(url,data=json.dumps(paload)) datas=response.text dictdatas=json.loads(datas)#dumps是将dict转化成str格式,loads是将str转化成dict time=dictdatas['time'] #有了dict格式就可以根据关键字提取数据了,先提取时间 print(time) locs=dictdatas['locs'] #再提取locs(这个需要进一步分析提取出经纬度和定位次数) locss=locs.split(',') temp=[] #搞一个容器 for i in range(int(len(locss)/3)): lat = locss[0 + 3 * i] # 得到纬度 lon = locss[1 + 3 * i] # 得到经度 count = locss[2 + 3 * i] if(2521<int(lat)<2555 and 11768<int(lon)<11853):#永春坐标范围 temp.append([time,int(lat)/100,int(lon)/100,count]) #容器追加四个字段的数据:时间,纬度,经度和定位次数 result=pd.DataFrame(temp) #用到神器pandas,真好用 result.dropna() #去掉脏数据,相当于数据过滤了 if result.columns.__len__()>0: result.columns = ['time', 'lat', 'lon','count'] result.to_csv('YCData.txt',mode='a',index = False)
4、爬取结果处理分析:
根据时间段,爬取对应时间的人口热点数据,包括经纬度、人口数量、时间等信息,结果以csv表达。

图2.1 爬取结果表达
5、分析过程:
数据导入Arcmap,添加为点,根据不同时间段进行数据梳理,转为SHP点数据,采用核密度分析、反距离权重插值、线条函数插值等进行分析,
对分析结果进行可视化渲染,得到不同时间的区域人口热力密度图。
可视化成果:

图2.2 上午10点人口热力
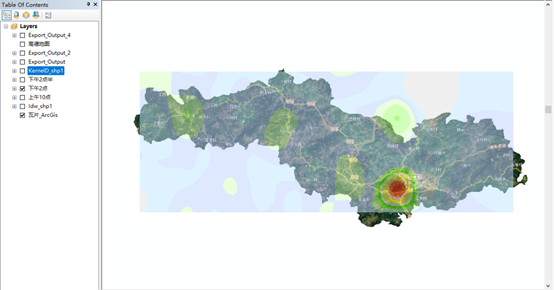
图2.3 下午2点人口热力

图2.4 下午5点人口热力
总结,本次实战主要是针对实地调研、网上、其他渠道无法直接获取数据时,通过爬虫技术,对相关大数据平台进行数据爬取,
主要是爬取了大数据平台的实时人口热力信息和POI信息,后期可以根据需求丰富爬取内容,对县城城镇化补短板强弱项的相关信息进行爬取分析。
原创版权声明,转载请说明出处,谢谢。