2、原理描述
一个topic 可以配置几个partition,produce发送的消息分发到不同的partition中,consumer接受数据的时候是按照group来接受,kafka确保每个partition只能同一个group中的同一个consumer消费,如果想要重复消费,那么需要其他的组来消费。Zookeerper中保存这每个topic下的每个partition在每个group中消费的offset
新版kafka把这个offsert保存到了一个__consumer_offsert的topic下
这个__consumer_offsert 有50个分区,通过将group的id哈希值%50的值来确定要保存到那一个分区. 这样也是为了考虑到zookeeper不擅长大量读写的原因。
所以,如果要一个group用几个consumer来同时读取的话,需要多线程来读取,一个线程相当于一个consumer实例。当consumer的数量大于分区的数量的时候,有的consumer线程会读取不到数据。
假设一个topic test 被groupA消费了,现在启动另外一个新的groupB来消费test,默认test-groupB的offset不是0,而是没有新建立,除非当test有数据的时候,groupB会收到该数据,该条数据也是第一条数据,groupB的offset也是刚初始化的ofsert, 除非用显式的用–from-beginnging 来获取从0开始数据
3、查看topic-group的offsert
位置:zookeeper
路径:[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics/__consumer_offsets/partitions
在zookeeper的topic中有一个特殊的topic __consumer_offserts
计算方法:(放入哪个partitions)
int hashCode = Math.abs("ttt".hashCode());
int partition = hashCode % 50;
先计算group的hashCode,再除以分区数(50),可以得到partition的值
使用命令查看: kafka-simple-consumer-shell.sh --topic __consumer_offsets --partition 11 --broker-list localhost:9092,localhost:9093,localhost:9094 --formatter "kafka.coordinator.GroupMetadataManager$OffsetsMessageFormatter"

4.参数
auto.offset.reset:默认值为largest,代表最新的消息,smallest代表从最早的消息开始读取,当consumer刚开始创建的时候没有offset这种情况,如果设置了largest,则为当收到最新的一条消息的时候开始记录offsert,若设置为smalert,那么会从头开始读partition


|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
import kafka.producer.Partitioner;import kafka.utils.VerifiableProperties;public class JasonPartitioner<T> implements Partitioner { public JasonPartitioner(VerifiableProperties verifiableProperties) {} @Override public int partition(Object key, int numPartitions) { try { int partitionNum = Integer.parseInt((String) key); return Math.abs(Integer.parseInt((String) key) % numPartitions); } catch (Exception e) { return Math.abs(key.hashCode() % numPartitions); } }} |
如果将上例中的类作为partition.class,并通过如下代码发送20条消息(key分别为0,1,2,3)至topic3(包含4个Partition)。
|
1
2
3
4
5
6
7
8
9
10
|
public void sendMessage() throws InterruptedException{ for(int i = 1; i <= 5; i++){ List messageList = new ArrayList<KeyedMessage<String, String>>(); for(int j = 0; j < 4; j++){ messageList.add(new KeyedMessage<String, String>("topic2", j+"", "The " + i + " message for key " + j)); } producer.send(messageList); } producer.close();} |
则key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和Partition序号相同。(Partition序号从0开始,本例中的key也从0开始)。下图所示是通过Java程序调用Consumer后打印出的消息列表。

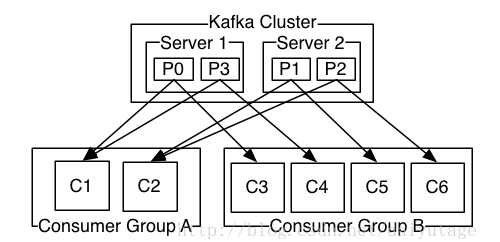
4、consumer group (本节所有描述都是基于Consumer hight level API而非low level API)。
使用Consumer high level API时,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息。

这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由的分组而不需要多次发送消息到不同的Topic。
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这三个操作所使用的Consumer属于不同的Consumer Group即可。
下面这个例子更清晰地展示了Kafka Consumer Group的特性。首先创建一个Topic (名为topic1,包含3个Partition),然后创建一个属于group1的Consumer实例,并创建三个属于group2的Consumer实例,最后通过Producer向topic1发送key分别为1,2,3的消息。结果发现属于group1的Consumer收到了所有的这三条消息,同时group2中的3个Consumer分别收到了key为1,2,3的消息。