本系列主要讲解kafka基本设计和原理分析,分如下内容:
- 基本概念
- 消息模型
- kafka副本同步机制
- kafka文件存储机制
- kafka数据可靠性和一致性保证
- kafka leader选举
- kafka消息传递语义
- Kafka集群partitions/replicas默认分配解析
kafka数据可靠性和一致性保证
当producer向leader发送数据时,可以通过request.required.acks参数来设置数据可靠性的级别:
- 1(默认):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果leader宕机了,则会丢失数据。
- 0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。
- -1:producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是这样也不能保证数据不丢失,比如当ISR中只有leader时(前面ISR那一节讲到,ISR中的成员由于某些情况会增加也会减少,最少就只剩一个leader),这样就变成了acks=1的情况。
如果要提高数据的可靠性,在设置request.required.acks=-1的同时,也要min.insync.replicas这个参数(可以在broker或者topic层面进行设置)的配合,这样才能发挥最大的功效。min.insync.replicas这个参数设定ISR中的最小副本数是多少,默认值为1,当且仅当request.required.acks参数设置为-1时,此参数才生效。如果ISR中的副本数少于min.insync.replicas配置的数量时,客户端会返回异常:org.apache.kafka.common.errors.NotEnoughReplicasExceptoin: Messages are rejected since there are fewer in-sync replicas than required。
接下来对acks=1和-1的两种情况进行详细分析。
request.required.acks=1
producer发送数据到leader,leader写本地日志成功,返回客户端成功;此时ISR中的副本还没有来得及拉取该消息,leader就宕机了,那么此次发送的消息就会丢失。
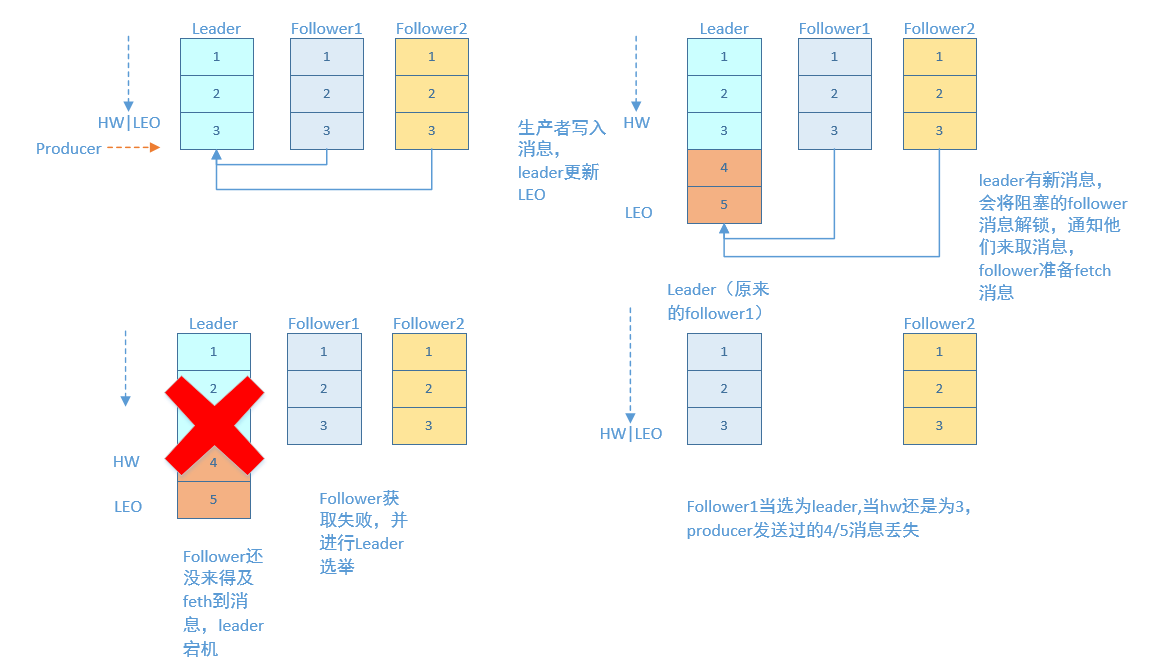
request.required.acks=-1
同步(Kafka默认为同步,即producer.type=sync)的发送模式,replication.factor>=2且min.insync.replicas>=2的情况下,不会丢失数据。
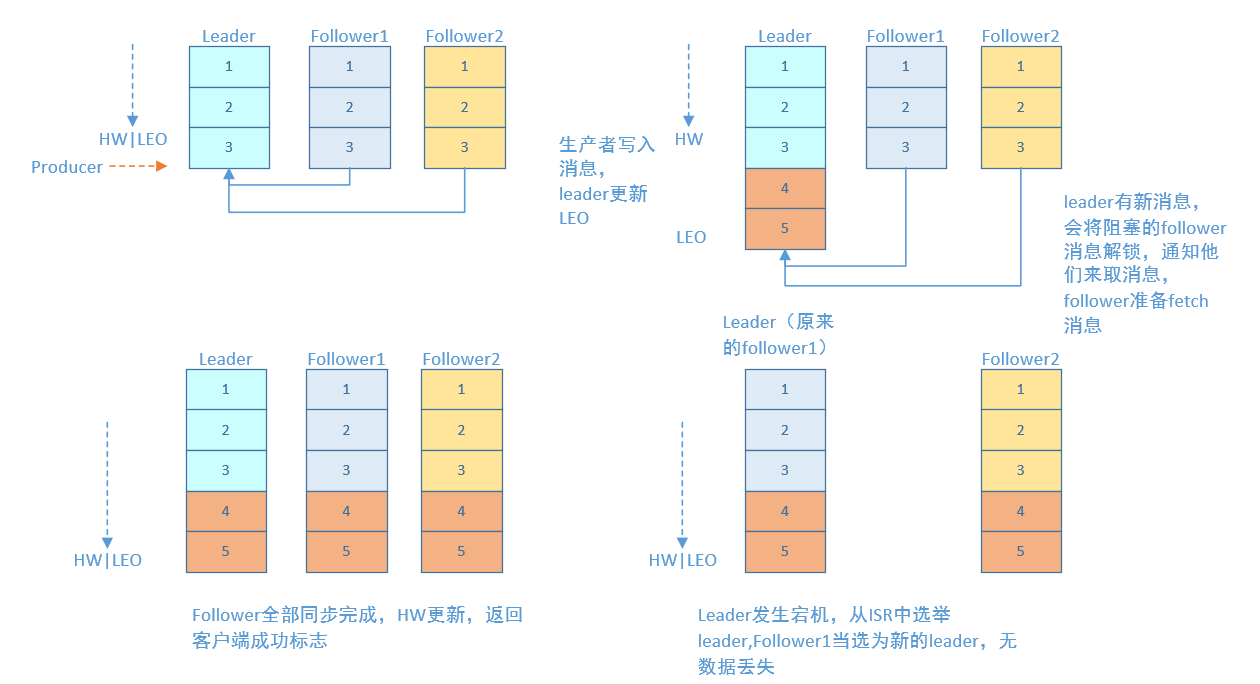
有两种典型情况,一种是follower完全同步,一种的follower部分同步
acks=-1的情况下(如无特殊说明,以下acks都表示为参数request.required.acks),数据发送到leader, ISR的follower全部完成数据同步后,leader此时挂掉,那么会选举出新的leader,数据不会丢失。
acks=-1的情况下,数据发送到leader后 ,部分ISR的副本同步,leader此时挂掉。比如follower1h和follower2都有可能变成新的leader, producer端会得到返回异常,producer端会重新发送数据,数据可能会重复。
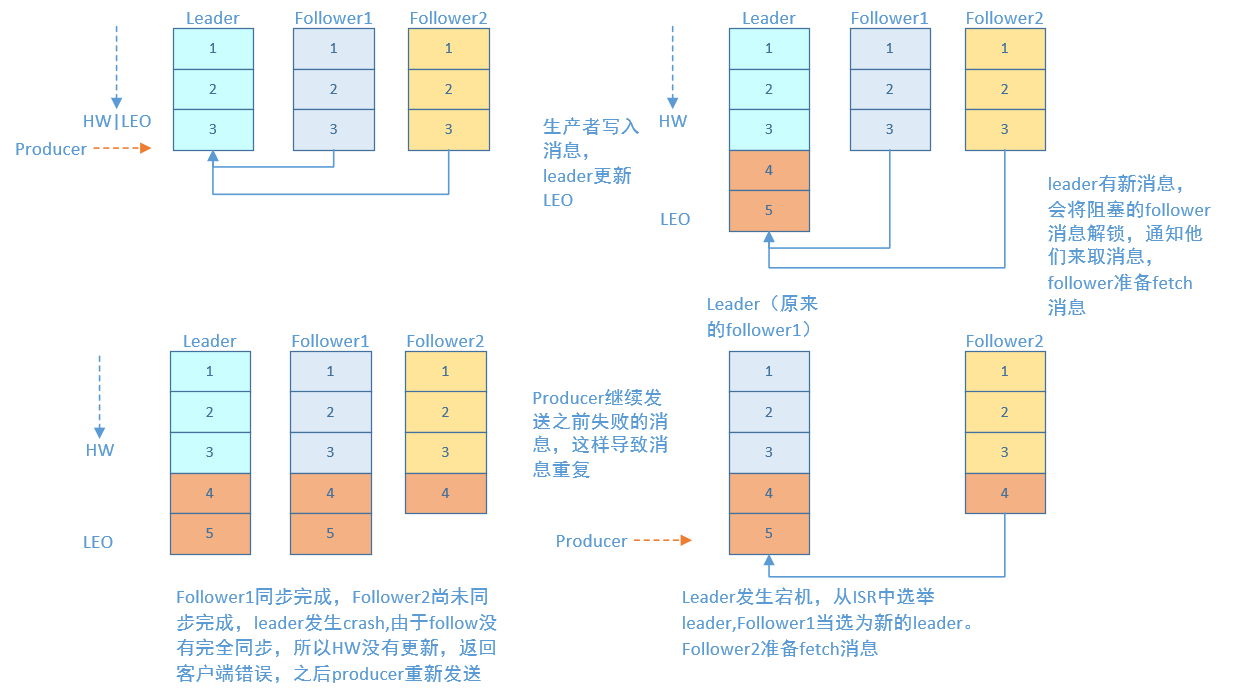
当然上图中如果在leader crash的时候,follower2还没有同步到任何数据,而且follower2被选举为新的leader的话,这样消息就不会重复。
HW深入讨论
考虑上图(即acks=-1,部分ISR副本同步)中的另一种情况,如果在Leader挂掉的时候,follower1同步了消息4,5,follower2同步了消息4,与此同时follower2被选举为leader,那么此时follower1中的多出的消息5该做如何处理呢?
这里就需要HW的协同配合了。如前所述,一个partition中的ISR列表中,leader的HW是所有ISR列表里副本中最小的那个的LEO。类似于木桶原理,水位取决于最低那块短板。
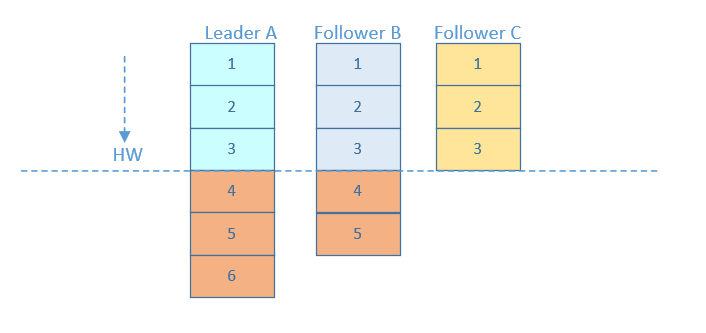
如上图,某个topic的某partition有三个副本,分别为A、B、C。A作为leader肯定是LEO最高,B紧随其后,C机器由于配置比较低,网络比较差,故而同步最慢。这个时候A机器宕机,这时候如果B成为leader,假如没有HW,在A重新恢复之后会做同步(makeFollower)操作,在宕机时log文件之后直接做追加操作,而假如B的LEO已经达到了A的LEO,会产生数据不一致的情况,所以使用HW来避免这种情况。
A在做同步操作的时候,先将log文件截断到之前自己的HW的位置,即3,之后再从B中拉取消息进行同步。
如果失败的follower恢复过来,它首先将自己的log文件截断到上次checkpointed时刻的HW的位置,之后再从leader中同步消息。leader挂掉会重新选举,新的leader会发送“指令”让其余的follower截断至自身的HW的位置然后再拉取新的消息。
当ISR中的个副本的LEO不一致时,如果此时leader挂掉,选举新的leader时并不是按照LEO的高低进行选举,而是按照ISR中的顺序选举。
关于作者
爱编程、爱钻研、爱分享、爱生活
关注分布式、高并发、数据挖掘
如需捐赠,请扫码
