一、Noisy Channel Model

应用场景:
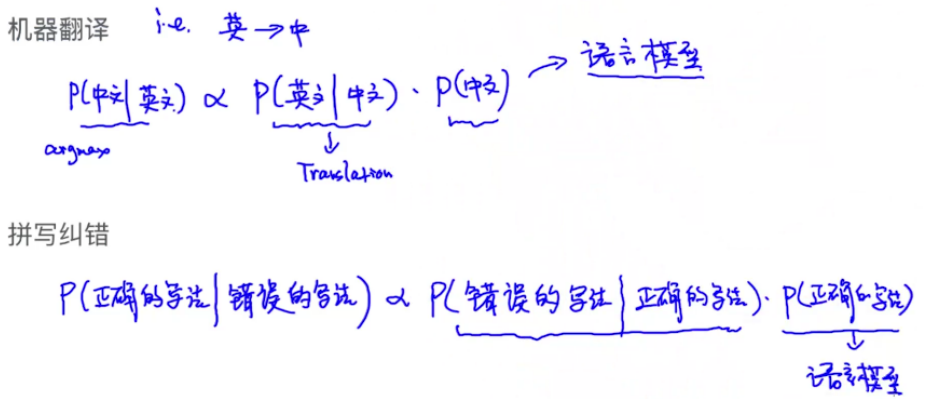
语音识别,机器翻译,拼写纠错,OCR,密码破解
上面场景共同点是将信号转为文本

二、Language Model
用来判断一句话从语法上是否通顺

一个已经训练好的语言模型可以通过概率进行判断:

如何训练模型?
语言模型的目标

Chain Rule

扫描文档,找 今天是春节我们都,找到了两句话:

因此,P(休息|今天,是,春节,我们,都)= 1/2
实际中长的句子往往是找不到的或很少,因此当条件包含多个单词时存在稀疏性问题
马尔可夫假设
近似

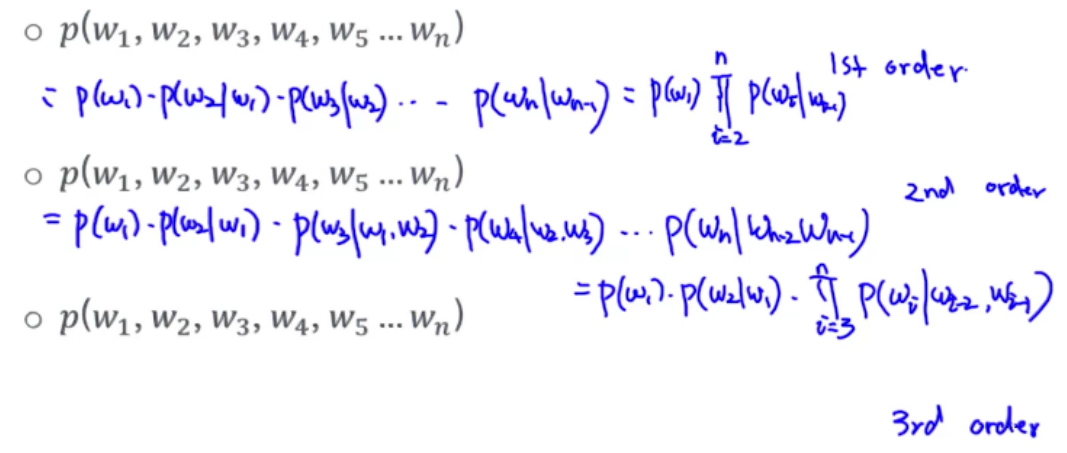
1st Order
当前单词只依赖前面一个单词

Unigram
当前单词与任何单词都是独立的关系

发向上面两个概率是一样的,不考虑单词顺序
Bigram
来自于1st Order Markov assumption

考虑前面一个单词
N-gram

估计语言模型的概率
Unigram
计算每个单词出现的概率



Bigram


今天出现了两次,其中 今天 后面是 上午 的有一次,因此P(上午|今天)概率是1/2
上午出现了一次,该次后面是 想,因此 P(想|上午)=1
N-gram
N=3

只要单词没出现在语料库中,概率都是0,不合理
给平滑项
评估语言模型


评估方法
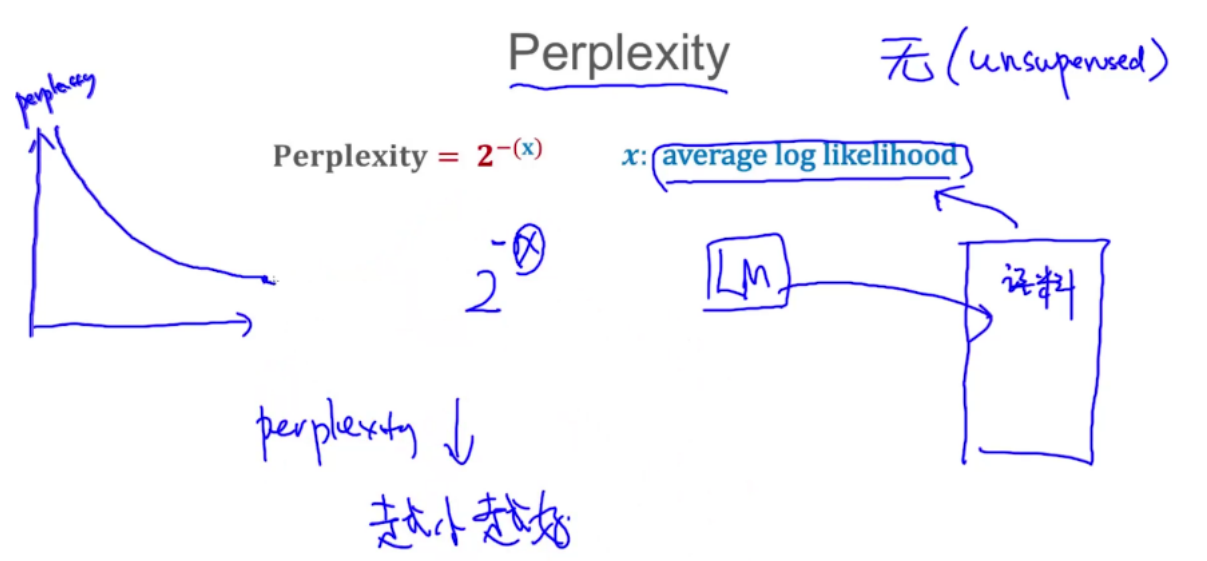

假设10为底的log,不好计算用a1、a2代替
平均log likelihood x = (a1+-2+-1+-2+a2+-1)/6

Add-one Smoothing
平滑概率为0的情况
Smoothing
- Add-one Smoothing
- Add-K Smoothing
- Interpolation
- Good-Turning Smoothing 现在未见到的东西,未来未必见不到

虽然 我们是 出现了0次,但是我们给它加1
实例
V是词典的大小,要排除重复的单词

如果下面不加V,总的概率加起来不等于1
Add-K Smoothing

K=1时就变为了Add-One smoothing
K可以自动选择,将K作为参数,进行优化

Interpolation

in the kitchen和in the arboretum都出现0次,但是in the kitchen显然不是什么生僻的词组,在未来的文档中肯定会出现
可以发现kitchen单词的频率是很高的,可以合理推断in the kitchen出现的概率应高于in the arboretum

