一、Hadoop Java API
静态类实现Mapper类
@Public @Stable public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public Mapper() { } protected void setup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { } protected void map(KEYIN key, VALUEIN value, Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { context.write(key, value); } protected void cleanup(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { } public void run(Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { this.setup(context); try { while(context.nextKeyValue()) { this.map(context.getCurrentKey(), context.getCurrentValue(), context); } } finally { this.cleanup(context); } } public abstract class Context implements MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public Context() { } } }
Context的接口
@Public @Evolving public interface MapContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends TaskInputOutputContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { InputSplit getInputSplit(); }
继承了
@Public @Evolving public interface TaskInputOutputContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends TaskAttemptContext { boolean nextKeyValue() throws IOException, InterruptedException; KEYIN getCurrentKey() throws IOException, InterruptedException; VALUEIN getCurrentValue() throws IOException, InterruptedException; void write(KEYOUT var1, VALUEOUT var2) throws IOException, InterruptedException; OutputCommitter getOutputCommitter(); }
继承了
@Public @Evolving public interface TaskAttemptContext extends JobContext, Progressable { TaskAttemptID getTaskAttemptID(); void setStatus(String var1); String getStatus(); float getProgress(); Counter getCounter(Enum<?> var1); Counter getCounter(String var1, String var2); }
继承了


Public @Evolving public interface JobContext extends MRJobConfig { Configuration getConfiguration(); Credentials getCredentials(); JobID getJobID(); int getNumReduceTasks(); Path getWorkingDirectory() throws IOException; Class<?> getOutputKeyClass(); Class<?> getOutputValueClass(); Class<?> getMapOutputKeyClass(); Class<?> getMapOutputValueClass(); String getJobName(); Class<? extends InputFormat<?, ?>> getInputFormatClass() throws ClassNotFoundException; Class<? extends Mapper<?, ?, ?, ?>> getMapperClass() throws ClassNotFoundException; Class<? extends Reducer<?, ?, ?, ?>> getCombinerClass() throws ClassNotFoundException; Class<? extends Reducer<?, ?, ?, ?>> getReducerClass() throws ClassNotFoundException; Class<? extends OutputFormat<?, ?>> getOutputFormatClass() throws ClassNotFoundException; Class<? extends Partitioner<?, ?>> getPartitionerClass() throws ClassNotFoundException; RawComparator<?> getSortComparator(); String getJar(); RawComparator<?> getCombinerKeyGroupingComparator(); RawComparator<?> getGroupingComparator(); boolean getJobSetupCleanupNeeded(); boolean getTaskCleanupNeeded(); boolean getProfileEnabled(); String getProfileParams(); IntegerRanges getProfileTaskRange(boolean var1); String getUser(); /** @deprecated */ @Deprecated boolean getSymlink(); Path[] getArchiveClassPaths(); URI[] getCacheArchives() throws IOException; URI[] getCacheFiles() throws IOException; /** @deprecated */ @Deprecated Path[] getLocalCacheArchives() throws IOException; /** @deprecated */ @Deprecated Path[] getLocalCacheFiles() throws IOException; Path[] getFileClassPaths(); String[] getArchiveTimestamps(); String[] getFileTimestamps(); int getMaxMapAttempts(); int getMaxReduceAttempts(); }
@Private @Evolving public interface MRJobConfig { String MAP_SORT_CLASS = "map.sort.class"; String INPUT_FORMAT_CLASS_ATTR = "mapreduce.job.inputformat.class"; String MAP_CLASS_ATTR = "mapreduce.job.map.class"; String MAP_OUTPUT_COLLECTOR_CLASS_ATTR = "mapreduce.job.map.output.collector.class"; String COMBINE_CLASS_ATTR = "mapreduce.job.combine.class"; String REDUCE_CLASS_ATTR = "mapreduce.job.reduce.class"; String OUTPUT_FORMAT_CLASS_ATTR = "mapreduce.job.outputformat.class"; String PARTITIONER_CLASS_ATTR = "mapreduce.job.partitioner.class"; String SETUP_CLEANUP_NEEDED = "mapreduce.job.committer.setup.cleanup.needed"; String TASK_CLEANUP_NEEDED = "mapreduce.job.committer.task.cleanup.needed"; String TASK_LOCAL_WRITE_LIMIT_BYTES = "mapreduce.task.local-fs.write-limit.bytes"; long DEFAULT_TASK_LOCAL_WRITE_LIMIT_BYTES = -1L; String JAR = "mapreduce.job.jar"; String ID = "mapreduce.job.id"; String JOB_NAME = "mapreduce.job.name"; String JAR_UNPACK_PATTERN = "mapreduce.job.jar.unpack.pattern"; String USER_NAME = "mapreduce.job.user.name"; String PRIORITY = "mapreduce.job.priority"; String QUEUE_NAME = "mapreduce.job.queuename"; String JOB_NODE_LABEL_EXP = "mapreduce.job.node-label-expression"; String AM_NODE_LABEL_EXP = "mapreduce.job.am.node-label-expression"; String MAP_NODE_LABEL_EXP = "mapreduce.map.node-label-expression"; String REDUCE_NODE_LABEL_EXP = "mapreduce.reduce.node-label-expression"; String AM_STRICT_LOCALITY = "mapreduce.job.am.strict-locality"; String RESERVATION_ID = "mapreduce.job.reservation.id"; String JOB_TAGS = "mapreduce.job.tags"; String JVM_NUMTASKS_TORUN = "mapreduce.job.jvm.numtasks"; String SPLIT_FILE = "mapreduce.job.splitfile"; String SPLIT_METAINFO_MAXSIZE = "mapreduce.job.split.metainfo.maxsize"; long DEFAULT_SPLIT_METAINFO_MAXSIZE = 10000000L; String NUM_MAPS = "mapreduce.job.maps"; String MAX_TASK_FAILURES_PER_TRACKER = "mapreduce.job.maxtaskfailures.per.tracker"; String COMPLETED_MAPS_FOR_REDUCE_SLOWSTART = "mapreduce.job.reduce.slowstart.completedmaps"; String NUM_REDUCES = "mapreduce.job.reduces"; String SKIP_RECORDS = "mapreduce.job.skiprecords"; String SKIP_OUTDIR = "mapreduce.job.skip.outdir"; /** @deprecated */ @Deprecated String SPECULATIVE_SLOWNODE_THRESHOLD = "mapreduce.job.speculative.slownodethreshold"; String SPECULATIVE_SLOWTASK_THRESHOLD = "mapreduce.job.speculative.slowtaskthreshold"; /** @deprecated */ @Deprecated String SPECULATIVECAP = "mapreduce.job.speculative.speculativecap"; String SPECULATIVECAP_RUNNING_TASKS = "mapreduce.job.speculative.speculative-cap-running-tasks"; double DEFAULT_SPECULATIVECAP_RUNNING_TASKS = 0.1D; String SPECULATIVECAP_TOTAL_TASKS = "mapreduce.job.speculative.speculative-cap-total-tasks"; double DEFAULT_SPECULATIVECAP_TOTAL_TASKS = 0.01D; String SPECULATIVE_MINIMUM_ALLOWED_TASKS = "mapreduce.job.speculative.minimum-allowed-tasks"; int DEFAULT_SPECULATIVE_MINIMUM_ALLOWED_TASKS = 10; String SPECULATIVE_RETRY_AFTER_NO_SPECULATE = "mapreduce.job.speculative.retry-after-no-speculate"; long DEFAULT_SPECULATIVE_RETRY_AFTER_NO_SPECULATE = 1000L; String SPECULATIVE_RETRY_AFTER_SPECULATE = "mapreduce.job.speculative.retry-after-speculate"; long DEFAULT_SPECULATIVE_RETRY_AFTER_SPECULATE = 15000L; String JOB_LOCAL_DIR = "mapreduce.job.local.dir"; String OUTPUT_KEY_CLASS = "mapreduce.job.output.key.class"; String OUTPUT_VALUE_CLASS = "mapreduce.job.output.value.class"; String KEY_COMPARATOR = "mapreduce.job.output.key.comparator.class"; String COMBINER_GROUP_COMPARATOR_CLASS = "mapreduce.job.combiner.group.comparator.class"; String GROUP_COMPARATOR_CLASS = "mapreduce.job.output.group.comparator.class"; String WORKING_DIR = "mapreduce.job.working.dir"; String CLASSPATH_ARCHIVES = "mapreduce.job.classpath.archives"; String CLASSPATH_FILES = "mapreduce.job.classpath.files"; String CACHE_FILES = "mapreduce.job.cache.files"; String CACHE_ARCHIVES = "mapreduce.job.cache.archives"; String CACHE_FILES_SIZES = "mapreduce.job.cache.files.filesizes"; String CACHE_ARCHIVES_SIZES = "mapreduce.job.cache.archives.filesizes"; String CACHE_LOCALFILES = "mapreduce.job.cache.local.files"; String CACHE_LOCALARCHIVES = "mapreduce.job.cache.local.archives"; String CACHE_FILE_TIMESTAMPS = "mapreduce.job.cache.files.timestamps"; String CACHE_ARCHIVES_TIMESTAMPS = "mapreduce.job.cache.archives.timestamps"; String CACHE_FILE_VISIBILITIES = "mapreduce.job.cache.files.visibilities"; String CACHE_ARCHIVES_VISIBILITIES = "mapreduce.job.cache.archives.visibilities"; String JOBJAR_VISIBILITY = "mapreduce.job.jobjar.visibility"; boolean JOBJAR_VISIBILITY_DEFAULT = false; String JOBJAR_SHARED_CACHE_UPLOAD_POLICY = "mapreduce.job.jobjar.sharedcache.uploadpolicy"; boolean JOBJAR_SHARED_CACHE_UPLOAD_POLICY_DEFAULT = false; String CACHE_FILES_SHARED_CACHE_UPLOAD_POLICIES = "mapreduce.job.cache.files.sharedcache.uploadpolicies"; String CACHE_ARCHIVES_SHARED_CACHE_UPLOAD_POLICIES = "mapreduce.job.cache.archives.sharedcache.uploadpolicies"; String FILES_FOR_SHARED_CACHE = "mapreduce.job.cache.sharedcache.files"; String FILES_FOR_CLASSPATH_AND_SHARED_CACHE = "mapreduce.job.cache.sharedcache.files.addtoclasspath"; String ARCHIVES_FOR_SHARED_CACHE = "mapreduce.job.cache.sharedcache.archives"; String SHARED_CACHE_MODE = "mapreduce.job.sharedcache.mode"; String SHARED_CACHE_MODE_DEFAULT = "disabled"; /** @deprecated */ @Deprecated String CACHE_SYMLINK = "mapreduce.job.cache.symlink.create"; String USER_LOG_RETAIN_HOURS = "mapreduce.job.userlog.retain.hours"; String MAPREDUCE_JOB_USER_CLASSPATH_FIRST = "mapreduce.job.user.classpath.first"; String MAPREDUCE_JOB_CLASSLOADER = "mapreduce.job.classloader"; String MAPREDUCE_JOB_SHUFFLE_PROVIDER_SERVICES = "mapreduce.job.shuffle.provider.services"; String MAPREDUCE_JOB_CLASSLOADER_SYSTEM_CLASSES = "mapreduce.job.classloader.system.classes"; String MAPREDUCE_JVM_SYSTEM_PROPERTIES_TO_LOG = "mapreduce.jvm.system-properties-to-log"; String DEFAULT_MAPREDUCE_JVM_SYSTEM_PROPERTIES_TO_LOG = "os.name,os.version,java.home,java.runtime.version,java.vendor,java.version,java.vm.name,java.class.path,java.io.tmpdir,user.dir,user.name"; String IO_SORT_FACTOR = "mapreduce.task.io.sort.factor"; int DEFAULT_IO_SORT_FACTOR = 10; String IO_SORT_MB = "mapreduce.task.io.sort.mb"; int DEFAULT_IO_SORT_MB = 100; String INDEX_CACHE_MEMORY_LIMIT = "mapreduce.task.index.cache.limit.bytes"; String PRESERVE_FAILED_TASK_FILES = "mapreduce.task.files.preserve.failedtasks"; String PRESERVE_FILES_PATTERN = "mapreduce.task.files.preserve.filepattern"; String TASK_DEBUGOUT_LINES = "mapreduce.task.debugout.lines"; String RECORDS_BEFORE_PROGRESS = "mapreduce.task.merge.progress.records"; String SKIP_START_ATTEMPTS = "mapreduce.task.skip.start.attempts"; String TASK_ATTEMPT_ID = "mapreduce.task.attempt.id"; String TASK_ISMAP = "mapreduce.task.ismap"; boolean DEFAULT_TASK_ISMAP = true; String TASK_PARTITION = "mapreduce.task.partition"; String TASK_PROFILE = "mapreduce.task.profile"; String TASK_PROFILE_PARAMS = "mapreduce.task.profile.params"; String DEFAULT_TASK_PROFILE_PARAMS = "-agentlib:hprof=cpu=samples,heap=sites,force=n,thread=y,verbose=n,file=%s"; String NUM_MAP_PROFILES = "mapreduce.task.profile.maps"; String NUM_REDUCE_PROFILES = "mapreduce.task.profile.reduces"; String TASK_MAP_PROFILE_PARAMS = "mapreduce.task.profile.map.params"; String TASK_REDUCE_PROFILE_PARAMS = "mapreduce.task.profile.reduce.params"; String TASK_TIMEOUT = "mapreduce.task.timeout"; long DEFAULT_TASK_TIMEOUT_MILLIS = 300000L; String TASK_PROGRESS_REPORT_INTERVAL = "mapreduce.task.progress-report.interval"; String TASK_TIMEOUT_CHECK_INTERVAL_MS = "mapreduce.task.timeout.check-interval-ms"; String TASK_EXIT_TIMEOUT = "mapreduce.task.exit.timeout"; int TASK_EXIT_TIMEOUT_DEFAULT = 60000; String TASK_EXIT_TIMEOUT_CHECK_INTERVAL_MS = "mapreduce.task.exit.timeout.check-interval-ms"; int TASK_EXIT_TIMEOUT_CHECK_INTERVAL_MS_DEFAULT = 20000; String TASK_ID = "mapreduce.task.id"; String TASK_OUTPUT_DIR = "mapreduce.task.output.dir"; String TASK_USERLOG_LIMIT = "mapreduce.task.userlog.limit.kb"; String MAP_SORT_SPILL_PERCENT = "mapreduce.map.sort.spill.percent"; String MAP_INPUT_FILE = "mapreduce.map.input.file"; String MAP_INPUT_PATH = "mapreduce.map.input.length"; String MAP_INPUT_START = "mapreduce.map.input.start"; String MAP_MEMORY_MB = "mapreduce.map.memory.mb"; int DEFAULT_MAP_MEMORY_MB = 1024; String MAP_CPU_VCORES = "mapreduce.map.cpu.vcores"; int DEFAULT_MAP_CPU_VCORES = 1; String MAP_RESOURCE_TYPE_PREFIX = "mapreduce.map.resource."; String RESOURCE_TYPE_NAME_VCORE = "vcores"; String RESOURCE_TYPE_NAME_MEMORY = "memory"; String RESOURCE_TYPE_ALTERNATIVE_NAME_MEMORY = "memory-mb"; String MAP_ENV = "mapreduce.map.env"; String MAP_JAVA_OPTS = "mapreduce.map.java.opts"; String MAP_MAX_ATTEMPTS = "mapreduce.map.maxattempts"; String MAP_DEBUG_SCRIPT = "mapreduce.map.debug.script"; String MAP_SPECULATIVE = "mapreduce.map.speculative"; String MAP_FAILURES_MAX_PERCENT = "mapreduce.map.failures.maxpercent"; String MAP_SKIP_INCR_PROC_COUNT = "mapreduce.map.skip.proc-count.auto-incr"; String MAP_SKIP_MAX_RECORDS = "mapreduce.map.skip.maxrecords"; String MAP_COMBINE_MIN_SPILLS = "mapreduce.map.combine.minspills"; String MAP_OUTPUT_COMPRESS = "mapreduce.map.output.compress"; String MAP_OUTPUT_COMPRESS_CODEC = "mapreduce.map.output.compress.codec"; String MAP_OUTPUT_KEY_CLASS = "mapreduce.map.output.key.class"; String MAP_OUTPUT_VALUE_CLASS = "mapreduce.map.output.value.class"; String MAP_OUTPUT_KEY_FIELD_SEPARATOR = "mapreduce.map.output.key.field.separator"; /** @deprecated */ @Deprecated String MAP_OUTPUT_KEY_FIELD_SEPERATOR = "mapreduce.map.output.key.field.separator"; String MAP_LOG_LEVEL = "mapreduce.map.log.level"; String REDUCE_LOG_LEVEL = "mapreduce.reduce.log.level"; String DEFAULT_LOG_LEVEL = "INFO"; String REDUCE_MERGE_INMEM_THRESHOLD = "mapreduce.reduce.merge.inmem.threshold"; String REDUCE_INPUT_BUFFER_PERCENT = "mapreduce.reduce.input.buffer.percent"; String REDUCE_MARKRESET_BUFFER_PERCENT = "mapreduce.reduce.markreset.buffer.percent"; String REDUCE_MARKRESET_BUFFER_SIZE = "mapreduce.reduce.markreset.buffer.size"; String REDUCE_MEMORY_MB = "mapreduce.reduce.memory.mb"; int DEFAULT_REDUCE_MEMORY_MB = 1024; String REDUCE_CPU_VCORES = "mapreduce.reduce.cpu.vcores"; int DEFAULT_REDUCE_CPU_VCORES = 1; String REDUCE_RESOURCE_TYPE_PREFIX = "mapreduce.reduce.resource."; String REDUCE_MEMORY_TOTAL_BYTES = "mapreduce.reduce.memory.totalbytes"; String SHUFFLE_INPUT_BUFFER_PERCENT = "mapreduce.reduce.shuffle.input.buffer.percent"; float DEFAULT_SHUFFLE_INPUT_BUFFER_PERCENT = 0.7F; String SHUFFLE_MEMORY_LIMIT_PERCENT = "mapreduce.reduce.shuffle.memory.limit.percent"; String SHUFFLE_MERGE_PERCENT = "mapreduce.reduce.shuffle.merge.percent"; float DEFAULT_SHUFFLE_MERGE_PERCENT = 0.66F; String REDUCE_FAILURES_MAXPERCENT = "mapreduce.reduce.failures.maxpercent"; String REDUCE_ENV = "mapreduce.reduce.env"; String REDUCE_JAVA_OPTS = "mapreduce.reduce.java.opts"; String MAPREDUCE_JOB_DIR = "mapreduce.job.dir"; String REDUCE_MAX_ATTEMPTS = "mapreduce.reduce.maxattempts"; String SHUFFLE_PARALLEL_COPIES = "mapreduce.reduce.shuffle.parallelcopies"; String REDUCE_DEBUG_SCRIPT = "mapreduce.reduce.debug.script"; String REDUCE_SPECULATIVE = "mapreduce.reduce.speculative"; String SHUFFLE_CONNECT_TIMEOUT = "mapreduce.reduce.shuffle.connect.timeout"; String SHUFFLE_READ_TIMEOUT = "mapreduce.reduce.shuffle.read.timeout"; String SHUFFLE_FETCH_FAILURES = "mapreduce.reduce.shuffle.maxfetchfailures"; String MAX_ALLOWED_FETCH_FAILURES_FRACTION = "mapreduce.reduce.shuffle.max-fetch-failures-fraction"; float DEFAULT_MAX_ALLOWED_FETCH_FAILURES_FRACTION = 0.5F; String MAX_FETCH_FAILURES_NOTIFICATIONS = "mapreduce.reduce.shuffle.max-fetch-failures-notifications"; int DEFAULT_MAX_FETCH_FAILURES_NOTIFICATIONS = 3; String SHUFFLE_FETCH_RETRY_INTERVAL_MS = "mapreduce.reduce.shuffle.fetch.retry.interval-ms"; int DEFAULT_SHUFFLE_FETCH_RETRY_INTERVAL_MS = 1000; String SHUFFLE_FETCH_RETRY_TIMEOUT_MS = "mapreduce.reduce.shuffle.fetch.retry.timeout-ms"; String SHUFFLE_FETCH_RETRY_ENABLED = "mapreduce.reduce.shuffle.fetch.retry.enabled"; String SHUFFLE_NOTIFY_READERROR = "mapreduce.reduce.shuffle.notify.readerror"; String MAX_SHUFFLE_FETCH_RETRY_DELAY = "mapreduce.reduce.shuffle.retry-delay.max.ms"; long DEFAULT_MAX_SHUFFLE_FETCH_RETRY_DELAY = 60000L; String MAX_SHUFFLE_FETCH_HOST_FAILURES = "mapreduce.reduce.shuffle.max-host-failures"; int DEFAULT_MAX_SHUFFLE_FETCH_HOST_FAILURES = 5; String REDUCE_SKIP_INCR_PROC_COUNT = "mapreduce.reduce.skip.proc-count.auto-incr"; String REDUCE_SKIP_MAXGROUPS = "mapreduce.reduce.skip.maxgroups"; String REDUCE_MEMTOMEM_THRESHOLD = "mapreduce.reduce.merge.memtomem.threshold"; String REDUCE_MEMTOMEM_ENABLED = "mapreduce.reduce.merge.memtomem.enabled"; String COMBINE_RECORDS_BEFORE_PROGRESS = "mapreduce.task.combine.progress.records"; String JOB_NAMENODES = "mapreduce.job.hdfs-servers"; String JOB_NAMENODES_TOKEN_RENEWAL_EXCLUDE = "mapreduce.job.hdfs-servers.token-renewal.exclude"; String JOB_JOBTRACKER_ID = "mapreduce.job.kerberos.jtprinicipal"; String JOB_CANCEL_DELEGATION_TOKEN = "mapreduce.job.complete.cancel.delegation.tokens"; String JOB_ACL_VIEW_JOB = "mapreduce.job.acl-view-job"; String DEFAULT_JOB_ACL_VIEW_JOB = " "; String JOB_ACL_MODIFY_JOB = "mapreduce.job.acl-modify-job"; String DEFAULT_JOB_ACL_MODIFY_JOB = " "; String JOB_RUNNING_MAP_LIMIT = "mapreduce.job.running.map.limit"; int DEFAULT_JOB_RUNNING_MAP_LIMIT = 0; String JOB_RUNNING_REDUCE_LIMIT = "mapreduce.job.running.reduce.limit"; int DEFAULT_JOB_RUNNING_REDUCE_LIMIT = 0; String JOB_MAX_MAP = "mapreduce.job.max.map"; int DEFAULT_JOB_MAX_MAP = -1; String MAPREDUCE_JOB_CREDENTIALS_BINARY = "mapreduce.job.credentials.binary"; String JOB_TOKEN_TRACKING_IDS_ENABLED = "mapreduce.job.token.tracking.ids.enabled"; boolean DEFAULT_JOB_TOKEN_TRACKING_IDS_ENABLED = false; String JOB_TOKEN_TRACKING_IDS = "mapreduce.job.token.tracking.ids"; String JOB_SUBMITHOST = "mapreduce.job.submithostname"; String JOB_SUBMITHOSTADDR = "mapreduce.job.submithostaddress"; String COUNTERS_MAX_KEY = "mapreduce.job.counters.max"; int COUNTERS_MAX_DEFAULT = 120; String COUNTER_GROUP_NAME_MAX_KEY = "mapreduce.job.counters.group.name.max"; int COUNTER_GROUP_NAME_MAX_DEFAULT = 128; String COUNTER_NAME_MAX_KEY = "mapreduce.job.counters.counter.name.max"; int COUNTER_NAME_MAX_DEFAULT = 64; String COUNTER_GROUPS_MAX_KEY = "mapreduce.job.counters.groups.max"; int COUNTER_GROUPS_MAX_DEFAULT = 50; String JOB_UBERTASK_ENABLE = "mapreduce.job.ubertask.enable"; String JOB_UBERTASK_MAXMAPS = "mapreduce.job.ubertask.maxmaps"; String JOB_UBERTASK_MAXREDUCES = "mapreduce.job.ubertask.maxreduces"; String JOB_UBERTASK_MAXBYTES = "mapreduce.job.ubertask.maxbytes"; String MAPREDUCE_JOB_EMIT_TIMELINE_DATA = "mapreduce.job.emit-timeline-data"; boolean DEFAULT_MAPREDUCE_JOB_EMIT_TIMELINE_DATA = false; String MR_PREFIX = "yarn.app.mapreduce."; String MR_AM_PREFIX = "yarn.app.mapreduce.am."; String MR_CLIENT_TO_AM_IPC_MAX_RETRIES = "yarn.app.mapreduce.client-am.ipc.max-retries"; int DEFAULT_MR_CLIENT_TO_AM_IPC_MAX_RETRIES = 3; String MR_CLIENT_TO_AM_IPC_MAX_RETRIES_ON_TIMEOUTS = "yarn.app.mapreduce.client-am.ipc.max-retries-on-timeouts"; int DEFAULT_MR_CLIENT_TO_AM_IPC_MAX_RETRIES_ON_TIMEOUTS = 3; String MR_CLIENT_MAX_RETRIES = "yarn.app.mapreduce.client.max-retries"; int DEFAULT_MR_CLIENT_MAX_RETRIES = 3; String MR_CLIENT_JOB_MAX_RETRIES = "yarn.app.mapreduce.client.job.max-retries"; int DEFAULT_MR_CLIENT_JOB_MAX_RETRIES = 3; String MR_CLIENT_JOB_RETRY_INTERVAL = "yarn.app.mapreduce.client.job.retry-interval"; long DEFAULT_MR_CLIENT_JOB_RETRY_INTERVAL = 2000L; String MR_AM_STAGING_DIR = "yarn.app.mapreduce.am.staging-dir"; String DEFAULT_MR_AM_STAGING_DIR = "/tmp/hadoop-yarn/staging"; String MR_AM_VMEM_MB = "yarn.app.mapreduce.am.resource.mb"; int DEFAULT_MR_AM_VMEM_MB = 1536; String MR_AM_CPU_VCORES = "yarn.app.mapreduce.am.resource.cpu-vcores"; int DEFAULT_MR_AM_CPU_VCORES = 1; String MR_AM_RESOURCE_PREFIX = "yarn.app.mapreduce.am.resource."; String MR_AM_COMMAND_OPTS = "yarn.app.mapreduce.am.command-opts"; String DEFAULT_MR_AM_COMMAND_OPTS = "-Xmx1024m"; String MR_AM_ADMIN_COMMAND_OPTS = "yarn.app.mapreduce.am.admin-command-opts"; String DEFAULT_MR_AM_ADMIN_COMMAND_OPTS = ""; String MR_AM_LOG_LEVEL = "yarn.app.mapreduce.am.log.level"; String DEFAULT_MR_AM_LOG_LEVEL = "INFO"; String MR_AM_LOG_KB = "yarn.app.mapreduce.am.container.log.limit.kb"; int DEFAULT_MR_AM_LOG_KB = 0; String MR_AM_LOG_BACKUPS = "yarn.app.mapreduce.am.container.log.backups"; int DEFAULT_MR_AM_LOG_BACKUPS = 0; String MR_AM_NUM_PROGRESS_SPLITS = "yarn.app.mapreduce.am.num-progress-splits"; int DEFAULT_MR_AM_NUM_PROGRESS_SPLITS = 12; String MR_AM_CONTAINERLAUNCHER_THREAD_COUNT_LIMIT = "yarn.app.mapreduce.am.containerlauncher.thread-count-limit"; int DEFAULT_MR_AM_CONTAINERLAUNCHER_THREAD_COUNT_LIMIT = 500; String MR_AM_CONTAINERLAUNCHER_THREADPOOL_INITIAL_SIZE = "yarn.app.mapreduce.am.containerlauncher.threadpool-initial-size"; int DEFAULT_MR_AM_CONTAINERLAUNCHER_THREADPOOL_INITIAL_SIZE = 10; String MR_AM_JOB_CLIENT_THREAD_COUNT = "yarn.app.mapreduce.am.job.client.thread-count"; int DEFAULT_MR_AM_JOB_CLIENT_THREAD_COUNT = 1; String MR_AM_JOB_CLIENT_PORT_RANGE = "yarn.app.mapreduce.am.job.client.port-range"; String MR_AM_WEBAPP_PORT_RANGE = "yarn.app.mapreduce.am.webapp.port-range"; String MR_AM_JOB_NODE_BLACKLISTING_ENABLE = "yarn.app.mapreduce.am.job.node-blacklisting.enable"; String MR_AM_IGNORE_BLACKLISTING_BLACKLISTED_NODE_PERECENT = "yarn.app.mapreduce.am.job.node-blacklisting.ignore-threshold-node-percent"; int DEFAULT_MR_AM_IGNORE_BLACKLISTING_BLACKLISTED_NODE_PERCENT = 33; String MR_AM_JOB_RECOVERY_ENABLE = "yarn.app.mapreduce.am.job.recovery.enable"; boolean MR_AM_JOB_RECOVERY_ENABLE_DEFAULT = true; String MR_AM_JOB_REDUCE_PREEMPTION_LIMIT = "yarn.app.mapreduce.am.job.reduce.preemption.limit"; float DEFAULT_MR_AM_JOB_REDUCE_PREEMPTION_LIMIT = 0.5F; String MR_AM_PREEMPTION_POLICY = "yarn.app.mapreduce.am.preemption.policy"; String JOB_AM_ACCESS_DISABLED = "mapreduce.job.am-access-disabled"; boolean DEFAULT_JOB_AM_ACCESS_DISABLED = false; String MR_AM_JOB_REDUCE_RAMPUP_UP_LIMIT = "yarn.app.mapreduce.am.job.reduce.rampup.limit"; float DEFAULT_MR_AM_JOB_REDUCE_RAMP_UP_LIMIT = 0.5F; String MR_AM_JOB_SPECULATOR = "yarn.app.mapreduce.am.job.speculator.class"; String MR_AM_TASK_ESTIMATOR = "yarn.app.mapreduce.am.job.task.estimator.class"; String MR_AM_TASK_ESTIMATOR_SMOOTH_LAMBDA_MS = "yarn.app.mapreduce.am.job.task.estimator.exponential.smooth.lambda-ms"; long DEFAULT_MR_AM_TASK_ESTIMATOR_SMOOTH_LAMBDA_MS = 60000L; String MR_AM_TASK_ESTIMATOR_EXPONENTIAL_RATE_ENABLE = "yarn.app.mapreduce.am.job.task.estimator.exponential.smooth.rate"; String MR_AM_TASK_LISTENER_THREAD_COUNT = "yarn.app.mapreduce.am.job.task.listener.thread-count"; int DEFAULT_MR_AM_TASK_LISTENER_THREAD_COUNT = 30; String MR_AM_TO_RM_HEARTBEAT_INTERVAL_MS = "yarn.app.mapreduce.am.scheduler.heartbeat.interval-ms"; int DEFAULT_MR_AM_TO_RM_HEARTBEAT_INTERVAL_MS = 1000; String MR_AM_TO_RM_WAIT_INTERVAL_MS = "yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms"; int DEFAULT_MR_AM_TO_RM_WAIT_INTERVAL_MS = 360000; String MR_AM_COMMITTER_CANCEL_TIMEOUT_MS = "yarn.app.mapreduce.am.job.committer.cancel-timeout"; int DEFAULT_MR_AM_COMMITTER_CANCEL_TIMEOUT_MS = 60000; String MR_AM_COMMIT_WINDOW_MS = "yarn.app.mapreduce.am.job.committer.commit-window"; int DEFAULT_MR_AM_COMMIT_WINDOW_MS = 10000; String MR_AM_CREATE_JH_INTERMEDIATE_BASE_DIR = "yarn.app.mapreduce.am.create-intermediate-jh-base-dir"; String MR_AM_HISTORY_MAX_UNFLUSHED_COMPLETE_EVENTS = "yarn.app.mapreduce.am.history.max-unflushed-events"; int DEFAULT_MR_AM_HISTORY_MAX_UNFLUSHED_COMPLETE_EVENTS = 200; String MR_AM_HISTORY_JOB_COMPLETE_UNFLUSHED_MULTIPLIER = "yarn.app.mapreduce.am.history.job-complete-unflushed-multiplier"; int DEFAULT_MR_AM_HISTORY_JOB_COMPLETE_UNFLUSHED_MULTIPLIER = 30; String MR_AM_HISTORY_COMPLETE_EVENT_FLUSH_TIMEOUT_MS = "yarn.app.mapreduce.am.history.complete-event-flush-timeout"; long DEFAULT_MR_AM_HISTORY_COMPLETE_EVENT_FLUSH_TIMEOUT_MS = 30000L; String MR_AM_HISTORY_USE_BATCHED_FLUSH_QUEUE_SIZE_THRESHOLD = "yarn.app.mapreduce.am.history.use-batched-flush.queue-size.threshold"; int DEFAULT_MR_AM_HISTORY_USE_BATCHED_FLUSH_QUEUE_SIZE_THRESHOLD = 50; String MR_AM_HARD_KILL_TIMEOUT_MS = "yarn.app.mapreduce.am.hard-kill-timeout-ms"; long DEFAULT_MR_AM_HARD_KILL_TIMEOUT_MS = 10000L; String MR_JOB_REDUCER_UNCONDITIONAL_PREEMPT_DELAY_SEC = "mapreduce.job.reducer.unconditional-preempt.delay.sec"; int DEFAULT_MR_JOB_REDUCER_UNCONDITIONAL_PREEMPT_DELAY_SEC = 300; String MR_JOB_REDUCER_PREEMPT_DELAY_SEC = "mapreduce.job.reducer.preempt.delay.sec"; int DEFAULT_MR_JOB_REDUCER_PREEMPT_DELAY_SEC = 0; String MR_AM_ENV = "yarn.app.mapreduce.am.env"; String MR_AM_ADMIN_USER_ENV = "yarn.app.mapreduce.am.admin.user.env"; String DEFAULT_MR_AM_ADMIN_USER_ENV = Shell.WINDOWS ? "" : "LD_LIBRARY_PATH=" + Apps.crossPlatformify("HADOOP_COMMON_HOME") + "/lib/native"; String MR_AM_PROFILE = "yarn.app.mapreduce.am.profile"; boolean DEFAULT_MR_AM_PROFILE = false; String MR_AM_PROFILE_PARAMS = "yarn.app.mapreduce.am.profile.params"; String MAPRED_MAP_ADMIN_JAVA_OPTS = "mapreduce.admin.map.child.java.opts"; String MAPRED_REDUCE_ADMIN_JAVA_OPTS = "mapreduce.admin.reduce.child.java.opts"; String DEFAULT_MAPRED_ADMIN_JAVA_OPTS = "-Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN "; String MAPRED_ADMIN_USER_SHELL = "mapreduce.admin.user.shell"; String DEFAULT_SHELL = "/bin/bash"; String MAPRED_ADMIN_USER_ENV = "mapreduce.admin.user.env"; String DEFAULT_MAPRED_ADMIN_USER_ENV = Shell.WINDOWS ? "PATH=%PATH%;%HADOOP_COMMON_HOME%\bin" : "LD_LIBRARY_PATH=" + Apps.crossPlatformify("HADOOP_COMMON_HOME") + "/lib/native"; String WORKDIR = "work"; String OUTPUT = "output"; String HADOOP_WORK_DIR = "HADOOP_WORK_DIR"; String STDOUT_LOGFILE_ENV = "STDOUT_LOGFILE_ENV"; String STDERR_LOGFILE_ENV = "STDERR_LOGFILE_ENV"; String JOB_SUBMIT_DIR = "jobSubmitDir"; String JOB_CONF_FILE = "job.xml"; String JOB_JAR = "job.jar"; String JOB_SPLIT = "job.split"; String JOB_SPLIT_METAINFO = "job.splitmetainfo"; String APPLICATION_MASTER_CLASS = "org.apache.hadoop.mapreduce.v2.app.MRAppMaster"; String MAPREDUCE_V2_CHILD_CLASS = "org.apache.hadoop.mapred.YarnChild"; String APPLICATION_ATTEMPT_ID = "mapreduce.job.application.attempt.id"; String MR_JOB_END_NOTIFICATION_URL = "mapreduce.job.end-notification.url"; String MR_JOB_END_NOTIFICATION_PROXY = "mapreduce.job.end-notification.proxy"; String MR_JOB_END_NOTIFICATION_TIMEOUT = "mapreduce.job.end-notification.timeout"; String MR_JOB_END_RETRY_ATTEMPTS = "mapreduce.job.end-notification.retry.attempts"; String MR_JOB_END_RETRY_INTERVAL = "mapreduce.job.end-notification.retry.interval"; String MR_JOB_END_NOTIFICATION_MAX_ATTEMPTS = "mapreduce.job.end-notification.max.attempts"; String MR_JOB_END_NOTIFICATION_MAX_RETRY_INTERVAL = "mapreduce.job.end-notification.max.retry.interval"; int DEFAULT_MR_JOB_END_NOTIFICATION_TIMEOUT = 5000; String MR_AM_SECURITY_SERVICE_AUTHORIZATION_TASK_UMBILICAL = "security.job.task.protocol.acl"; String MR_AM_SECURITY_SERVICE_AUTHORIZATION_CLIENT = "security.job.client.protocol.acl"; String MAPREDUCE_APPLICATION_CLASSPATH = "mapreduce.application.classpath"; String MAPREDUCE_JOB_LOG4J_PROPERTIES_FILE = "mapreduce.job.log4j-properties-file"; String MAPREDUCE_APPLICATION_FRAMEWORK_PATH = "mapreduce.application.framework.path"; @Public @Unstable String DEFAULT_MAPREDUCE_CROSS_PLATFORM_APPLICATION_CLASSPATH = Apps.crossPlatformify("HADOOP_MAPRED_HOME") + "/share/hadoop/mapreduce/*," + Apps.crossPlatformify("HADOOP_MAPRED_HOME") + "/share/hadoop/mapreduce/lib/*"; String DEFAULT_MAPREDUCE_APPLICATION_CLASSPATH = Shell.WINDOWS ? "%HADOOP_MAPRED_HOME%\share\hadoop\mapreduce\*,%HADOOP_MAPRED_HOME%\share\hadoop\mapreduce\lib\*" : "$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*,$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*"; String WORKFLOW_ID = "mapreduce.workflow.id"; String TASK_LOG_BACKUPS = "yarn.app.mapreduce.task.container.log.backups"; int DEFAULT_TASK_LOG_BACKUPS = 0; String REDUCE_SEPARATE_SHUFFLE_LOG = "yarn.app.mapreduce.shuffle.log.separate"; boolean DEFAULT_REDUCE_SEPARATE_SHUFFLE_LOG = true; String SHUFFLE_LOG_BACKUPS = "yarn.app.mapreduce.shuffle.log.backups"; int DEFAULT_SHUFFLE_LOG_BACKUPS = 0; String SHUFFLE_LOG_KB = "yarn.app.mapreduce.shuffle.log.limit.kb"; long DEFAULT_SHUFFLE_LOG_KB = 0L; String WORKFLOW_NAME = "mapreduce.workflow.name"; String WORKFLOW_NODE_NAME = "mapreduce.workflow.node.name"; String WORKFLOW_ADJACENCY_PREFIX_STRING = "mapreduce.workflow.adjacency."; String WORKFLOW_ADJACENCY_PREFIX_PATTERN = "^mapreduce\.workflow\.adjacency\..+"; String WORKFLOW_TAGS = "mapreduce.workflow.tags"; String MR_AM_MAX_ATTEMPTS = "mapreduce.am.max-attempts"; int DEFAULT_MR_AM_MAX_ATTEMPTS = 2; String MR_APPLICATION_TYPE = "MAPREDUCE"; String TASK_PREEMPTION = "mapreduce.job.preemption"; String HEAP_MEMORY_MB_RATIO = "mapreduce.job.heap.memory-mb.ratio"; float DEFAULT_HEAP_MEMORY_MB_RATIO = 0.8F; String MR_ENCRYPTED_INTERMEDIATE_DATA = "mapreduce.job.encrypted-intermediate-data"; boolean DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA = false; String MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS = "mapreduce.job.encrypted-intermediate-data-key-size-bits"; int DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_KEY_SIZE_BITS = 128; String MR_ENCRYPTED_INTERMEDIATE_DATA_BUFFER_KB = "mapreduce.job.encrypted-intermediate-data.buffer.kb"; int DEFAULT_MR_ENCRYPTED_INTERMEDIATE_DATA_BUFFER_KB = 128; String MAX_RESOURCES = "mapreduce.job.cache.limit.max-resources"; int MAX_RESOURCES_DEFAULT = 0; String MAX_RESOURCES_MB = "mapreduce.job.cache.limit.max-resources-mb"; long MAX_RESOURCES_MB_DEFAULT = 0L; String MAX_SINGLE_RESOURCE_MB = "mapreduce.job.cache.limit.max-single-resource-mb"; long MAX_SINGLE_RESOURCE_MB_DEFAULT = 0L; String MR_NUM_OPPORTUNISTIC_MAPS_PERCENT = "mapreduce.job.num-opportunistic-maps-percent"; int DEFAULT_MR_NUM_OPPORTUNISTIC_MAPS_PERCENT = 0; String MR_JOB_REDACTED_PROPERTIES = "mapreduce.job.redacted-properties"; String MR_JOB_SEND_TOKEN_CONF = "mapreduce.job.send-token-conf"; String FINISH_JOB_WHEN_REDUCERS_DONE = "mapreduce.job.finish-when-all-reducers-done"; boolean DEFAULT_FINISH_JOB_WHEN_REDUCERS_DONE = true; String MR_AM_STAGING_DIR_ERASURECODING_ENABLED = "yarn.app.mapreduce.am.staging-dir.erasurecoding.enabled"; boolean DEFAULT_MR_AM_STAGING_ERASURECODING_ENABLED = false; }
静态类实现Reducer类
@Checkpointable @Public @Stable public class Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public Reducer() { } protected void setup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { } protected void reduce(KEYIN key, Iterable<VALUEIN> values, Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { Iterator var4 = values.iterator(); while(var4.hasNext()) { VALUEIN value = var4.next(); context.write(key, value); } } protected void cleanup(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { } public void run(Reducer<KEYIN, VALUEIN, KEYOUT, VALUEOUT>.Context context) throws IOException, InterruptedException { this.setup(context); try { while(context.nextKey()) { this.reduce(context.getCurrentKey(), context.getValues(), context); Iterator<VALUEIN> iter = context.getValues().iterator(); if (iter instanceof ValueIterator) { ((ValueIterator)iter).resetBackupStore(); } } } finally { this.cleanup(context); } } public abstract class Context implements ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { public Context() { } } }
@Public @Evolving public interface ReduceContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> extends TaskInputOutputContext<KEYIN, VALUEIN, KEYOUT, VALUEOUT> { boolean nextKey() throws IOException, InterruptedException; Iterable<VALUEIN> getValues() throws IOException, InterruptedException; public interface ValueIterator<VALUEIN> extends MarkableIteratorInterface<VALUEIN> { void resetBackupStore() throws IOException; } }
后面和Mapper中context一样继承了
常用
Mapper<LongWritable, Text, Text, IntWritable>
Reducer<Text, IntWritable, Text, IntWritable>
Writable类
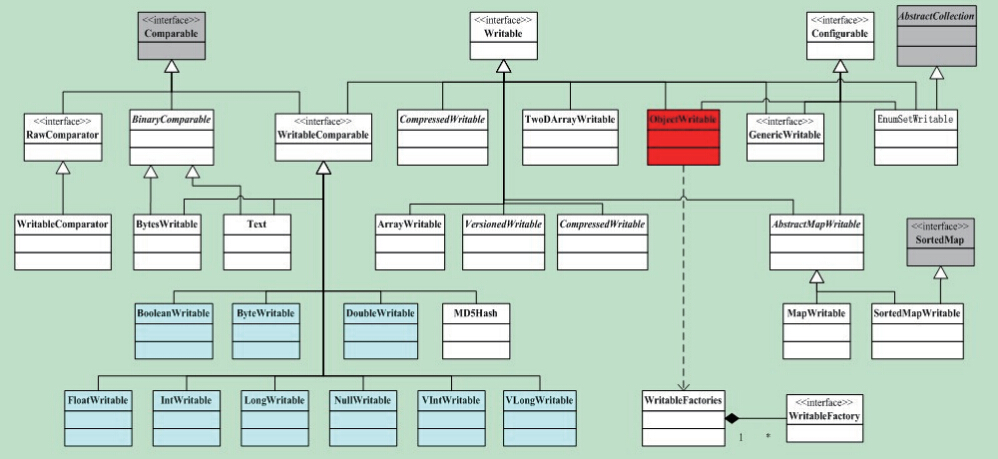
LongWritable, Text, IntWritable 等类都属于 org.apache.hadoop.io 包 http://hadoop.apache.org/docs/current/api/
目前Java基本类型对应的Writable封装如下表所示。所有这些Writable类都继承自WritableComparable。也就是说,它们是可比较的。同时,它们都有get()和set()方法,用于获得和设置封装的值。
| Java基本类型 | Writable实现 | 序列化大小(字节) |
|---|---|---|
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| Short | ShortWritable | 2 |
| int | IntWritable VintWritable |
4 1~5 |
| float | FloatWritable | 4 |
| long | LongWritable VlongWritable |
8 1~9 |
| double | DoubleWritable | 8 |
Text是针对UTF-8序列的Writable类。一般可以认为他是java.lang.String的Writable等价。Text类使用整型(通过变长编码的方式)来存储字符串编码中所需的字节数,因此该最大值为2GB。另外,Text使用标准UTF-8编码,这使得能够更简便的与其他理解UTF-8编码的工具进行交互操作。
Job要设置的内容
job = Job.getInstance(conf); job.setJarByClass(WordCountMRJob.class); // 设置mapper执行阶段 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class);//map输出key类型 job.setMapOutputValueClass(IntWritable.class); //map输出value类型 // 设置reduce执行阶段 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class);//reduce输出key类型 job.setOutputValueClass(IntWritable.class);//reduce输出value类型
还要有输入和输出路径
FileInputFormat.addInputPath(job,path);
FileOutputFormat.setOutputPath(job,output);
二、热身-WordCount
新建Maven项目
根据zookeeper和hadoop版本配置pom.xml,可用使用 echo stat|nc localhost 2181 查看zookeeper版本
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.aidata</groupId> <artifactId>bigdata</artifactId> <version>1.0-SNAPSHOT</version> <properties> <hadoop-version>3.0.0</hadoop-version> <zookeeper-version>3.4.5</zookeeper-version> </properties> <dependencies> <dependency> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> <version>${zookeeper-version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop-version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>2.3</version> <configuration> <classifier>dist</classifier> <appendAssemblyId>true</appendAssemblyId> <descriptorRefs> <descriptor>jar-with-dependencies</descriptor> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.2</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> </plugins> </build> </project>
三个有单词文件上传HDFS,使用tab分隔
hdfs dfs -put wc_tes* /input/wc
编写MapReduce程序
package com.aidata.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountMRJob { //Map阶段 /** * 输入数据键值对类型: * LongWritable:输入数据的偏移量 * Text:输入数据类型 * * 输出数据键值对类型: * Text:输出数据key的类型 * IntWritable:输出数据value的类型 */ public static class WordCountMapper extends Mapper<LongWritable,Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for(String word : words){ //word 1 context.write(new Text(word),new IntWritable(1)); } } } //Reduce阶段 /** * 输入数据键值对类型: * Text:输入数据的key类型 * IntWritable:输入数据的key类型 * * 输出数据键值对类型: * Text:输出数据的key类型 * IntWritable:输出数据的key类型 */ public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // word {1,1,1,...} int sum = 0; for(IntWritable value : values){ sum += value.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) { //1.配置job Configuration conf = new Configuration(); Job job = null; //2.创建job try { job = Job.getInstance(conf); } catch (IOException e) { e.printStackTrace(); } job.setJarByClass(WordCountMRJob.class); //3.给job添加执行流程 //3.1 HDFS中需要处理的文件路径 Path path = new Path(args[0]); try { //job添加输入路径 FileInputFormat.addInputPath(job,path); } catch (IOException e) { e.printStackTrace(); } //3.2设置map执行阶段 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class);//map输出key类型 job.setMapOutputValueClass(IntWritable.class); //map输出value类型 //3.3设置reduce执行阶段 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class);//reduce输出key类型 job.setOutputValueClass(IntWritable.class);//reduce输出value类型 //3.4设置job计算结果输出路径 Path output = new Path(args[1]); FileOutputFormat.setOutputPath(job,output); //4. 提交job,并等待job执行完成 try { boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }
点击maven的package进行打包,jar包会在target目录中,如果idea没有target
上传jar包到集群,运行
hadoop jar bigdata-1.0-SNAPSHOT.jar com.aidata.mapreduce.WordCountMRJob /input/wc/ /output/wc
查看节点的输出结果
hdfs dfs -ls /output/wc
如果你使用的是LZO
比如CDH中安装了LZO,想使用下
安装lzop
yum install lzop
拷贝jar包到本地,本人使用的CDH6.3.1的,LZOjar包如下
/opt/cloudera/parcels/GPLEXTRAS-6.3.1-1.gplextras6.3.1.p0.1470567/lib/hadoop/lib/hadoop-lzo-0.4.15-cdh6.3.1.jar
三个制表符分隔单词的文件
压缩文件
lzop -v wc*.txt
上传到hdfs
hdfs dfs -put wc*.txt.lzo /input
建立索引
lzo压缩文件的可切片特性依赖于其索引,故我们需要手动为lzo压缩文件创建索引。若无索引,则lzo文件的切片只有一个。
hadoop jar /opt/cloudera/parcels/GPLEXTRAS-6.3.1-1.gplextras6.3.1.p0.1470567/lib/hadoop/lib/hadoop-lzo-0.4.15-cdh6.3.1.jar com.hadoop.compression.lzo.DistributedLzoIndexer /input/
将LZOjar包放到idea的resources目录中,点击 add library
第三方包,需要在maven中配置一下,否正maven不识别
maven打包过程用的是maven-compiler-plugin插件进行编译,但是由于项目中存在第三方jar包,maven-compiler-plugin无法获知第三方jar包的位置,因此报错“程序包xxx不存在”,解决方法:
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.2</version> <configuration> <source>1.8</source> <target>1.8</target> <compilerArguments> <extdirs>${project.basedir}/src/main/resources</extdirs> </compilerArguments> <encoding>UTF-8</encoding> </configuration> </plugin>
mapreduce程序修改一下
package com.aidata.mapreduce; import com.hadoop.compression.lzo.LzopCodec; import com.hadoop.mapreduce.LzoTextInputFormat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class WordCountMRJob { //Map阶段 public static class WordCountMapper extends Mapper<LongWritable,Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for(String word : words){ //word 1 context.write(new Text(word),new IntWritable(1)); } } } //Reduce阶段 public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { // word {1,1,1,...} int sum = 0; for(IntWritable value : values){ sum += value.get(); } context.write(key,new IntWritable(sum)); } } public static void main(String[] args) { //1.配置job Configuration conf = new Configuration(); Job job = null; //2.创建job try { job = Job.getInstance(conf); } catch (IOException e) { e.printStackTrace(); } job.setJarByClass(WordCountMRJob.class); job.setInputFormatClass(LzoTextInputFormat.class); //配置reduce结果压缩以及压缩格式 FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, LzopCodec.class); //3.给job添加执行流程 //3.1 HDFS中需要处理的文件路径 Path path = new Path(args[0]); try { //job添加输入路径 FileInputFormat.addInputPath(job,path); } catch (IOException e) { e.printStackTrace(); } //3.2设置map执行阶段 job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class);//map输出key类型 job.setMapOutputValueClass(IntWritable.class); //map输出value类型 //3.3设置reduce执行阶段 job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class);//reduce输出key类型 job.setOutputValueClass(IntWritable.class);//reduce输出value类型 //3.4设置job计算结果输出路径 Path output = new Path(args[1]); FileOutputFormat.setOutputPath(job,output); //4. 提交job,并等待job执行完成 try { boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } } }
运行程序
hadoop jar bigdata-1.0-SNAPSHOT.jar com.aidata.mapreduce.WordCountMRJob /input/ /output
如果没有
FileOutputFormat.setCompressOutput(job, true); FileOutputFormat.setOutputCompressorClass(job, LzopCodec.class);
则要指定输出格式
如若未在程序中配置输入和输出都为Lzo格式,可以在命令行通过 -D 开头的参数进行配置
hadoop jar myjar.jar -D mapred.reduce.tasks=2 -D mapreduce.job.inputformat.class=com.hadoop.mapreduce.LzoTextInputFormat -D mapred.output.compress=true -D mapred.output.compression.codec=com.hadoop.compression.lzo.LzopCodec /input /output
CDH中reduce task数量的设置

MapReduce工具类
mapreduce2.0以后的版本为了规范开发,为我们提供了新的辅助工具类
需要实现Tool接口
@Public @Stable public interface Tool extends Configurable { int run(String[] var1) throws Exception; }
Tool接口继承了Configurable
@Public @Stable public interface Configurable { void setConf(Configuration var1); Configuration getConf(); }
为了更方便,提供了Configured方法,该方法实现了Configurable接口的方法,因此继承该方法就不用我们自己再实现Configurable接口的方法了
@Public @Stable public class Configured implements Configurable { private Configuration conf; public Configured() { this((Configuration)null); } public Configured(Configuration conf) { this.setConf(conf); } public void setConf(Configuration conf) { this.conf = conf; } public Configuration getConf() { return this.conf; } }
我们只需实现run()方法即可,已经提供了ToolRunner工具类为我们调用run()方法
@Public @Stable public class ToolRunner { public ToolRunner() { } public static int run(Configuration conf, Tool tool, String[] args) throws Exception { if (CallerContext.getCurrent() == null) { CallerContext ctx = (new Builder("CLI")).build(); CallerContext.setCurrent(ctx); } if (conf == null) { conf = new Configuration(); } GenericOptionsParser parser = new GenericOptionsParser(conf, args); tool.setConf(conf); String[] toolArgs = parser.getRemainingArgs(); return tool.run(toolArgs); } public static int run(Tool tool, String[] args) throws Exception { return run(tool.getConf(), tool, args); } public static void printGenericCommandUsage(PrintStream out) { GenericOptionsParser.printGenericCommandUsage(out); } public static boolean confirmPrompt(String prompt) throws IOException { while(true) { System.err.print(prompt + " (Y or N) "); StringBuilder responseBuilder = new StringBuilder(); while(true) { int c = System.in.read(); if (c == -1 || c == 13 || c == 10) { String response = responseBuilder.toString(); if (!response.equalsIgnoreCase("y") && !response.equalsIgnoreCase("yes")) { if (!response.equalsIgnoreCase("n") && !response.equalsIgnoreCase("no")) { System.err.println("Invalid input: " + response); break; } return false; } return true; } responseBuilder.append((char)c); } } } }
来看一下ToolRunner的run()方法
public static int run(Configuration conf, Tool tool, String[] args) throws Exception { if (CallerContext.getCurrent() == null) { CallerContext ctx = (new Builder("CLI")).build(); CallerContext.setCurrent(ctx); } if (conf == null) { conf = new Configuration(); } GenericOptionsParser parser = new GenericOptionsParser(conf, args); tool.setConf(conf); String[] toolArgs = parser.getRemainingArgs(); return tool.run(toolArgs); }
第一个参数是个Configuration,和实现了Tool接口覆写的run()方法的Configuration不是一个,这个专门用来存放参数的
如果conf是空,重新创建一个Configuration,所以传null也是可以的
解析提交job的时候外部的参数
GenericOptionsParser parser = new GenericOptionsParser(conf, args);
和job相关的会被加入到conf中
tool.setConf(conf);
这个tool中setConf是实现了Tool接口的对象的一个conf,也就是把这里的接收的和job有关的参数合并到那个总的conf中去了
和job不相关的则会被传入到run方法中
String[] toolArgs = parser.getRemainingArgs(); return tool.run(toolArgs);
外部可以传入的参数也是mapred-default.xml 的设置项,具体可用的参数见 https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
比如我们想设置reduceTask的数量,-D后面加设置项即可
hadoop jar xxx.jar 主类 input路径 output路径 -Dmapreduce.job.reduces=3
前面加-D的参数会被设置到conf中去,没有加的比如输入和输出路径会传给tool.run()
public class WordCount extends Configured implements Tool { public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); String[] words = line.split(" "); for (String word: words) { context.write(new Text(word), new IntWritable(1)); } } } public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value: values){ sum = sum + value.get(); } context.write(key, new IntWritable(sum)); } } @Override public int run(String[] args) throws Exception { Configuration conf = this.getConf(); Job job = null; try { job = Job.getInstance(conf); } catch (IOException e) { e.printStackTrace(); } job.setJarByClass(WordCount.class); job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); Path path = new Path(args[0]); FileInputFormat.addInputPath(job, path); Path out = new Path(args[1]); FileOutputFormat.setOutputPath(job, out); boolean result = job.waitForCompletion(true); return result? 0: 1; } public static void main(String[] args) { // 用于本地测试 if (args.length == 0){ args = new String[]{ "hdfs://ns/input/wc/", "hdfs://ns/output/wc" }; } // 配置job Configuration conf = new Configuration(); Path hdfsOutPutPath = new Path(args[1]); try { FileSystem fileSystem = FileSystem.get(conf); if (fileSystem.exists(hdfsOutPutPath)){ fileSystem.delete(hdfsOutPutPath, true); } }catch (Exception e){ e.printStackTrace(); } try { int stat = ToolRunner.run(null, new WordCount(), args); System.exit(stat); } catch (Exception e) { e.printStackTrace(); } } }
下面这句
int stat = ToolRunner.run(null, new WordCount(), args);
接收的数值实质上是来自
boolean result = job.waitForCompletion(true); return result? 0: 1;
也就是job完成返回0,否正返回1
因为下面使用 System.exit(stat) 来退出整个程序,System.exit(0)是正常退出程序,而System.exit(1)或者说非0表示非正常退出程序。
三、网站日志分析项目
Java基本类型Writable实现序列化大小(字节)booleanBooleanWritable1byteByteWritable1ShortShortWritable2intIntWritable
VintWritable4
1~5floatFloatWritable4longLongWritable
VlongWritable8
1~9doubleDoubleWritable8