0、什么是数据不平衡问题
在机器学习的分类问题中,不同类别的样本数据量存在差异。在某些场景,比如网页点击率预估(网页点击率低),购物推荐(浏览产生的购买少),信用卡欺诈,网络攻击识别等,这种差异可能会较大。传统的学习算法,对不同类别的数据一视同仁地处理,会产生在多数类样本效果较好,但是在少数类样本上效果差的问题。而在上述的四种场景中,我们更关注的是少数类的效果,传统的算法对此处理的效果并不能达到预期。因此需要一些专门的方法来解决数据不平衡问题。
1、解决方案
目前解决数据不平衡问题的方法可以分为两类:一类是从数据层面出发,通过抽样改善样本的不平衡程度,从而提升效果;另一类是从算法层面出发,通过定义不同误分类的代价进行算法优化。下面描述一些具体的策略
1.1、基于数据的方法
1.1.1、随机采样
随机采样
随机采样包括两种方法:随机欠采样和随机过采样。
1.1.1.1、随机欠采样
随机欠采样是对多数类样本进行随机采样,通过设置适当的采样比,减少多数类样本的数量,从而使得多数类和少数类样本达到预期的比例。
优缺点:
优点: 减少样本量,降低样本不平衡比例,缓解少数类分类效果差问题;同时由于数据量减小,也可以缩短运行时间,降低存储成本。
缺点: 减少的样本中含有有用信息,可能改变原有数据分布,从而降低精度。
1.1.1.2、随机过采样
随机过采样是对少数类样本进行随机复制,通过设置适当的随便复制比,增加少数类样本的数量,从而使得多数类和少数量样本达到预期的比例。
优缺点:
优点: 相比欠采样无信息损失;据说效果优于欠采样。
缺点: 数据复制可能带来过拟合。
Tips:
在过采样中还有一类基于聚类的过采样方法,也就是通过聚类分配不同簇中样本的过采样比例进行采样的方法。
1.1.2、Informed Undersampling
Informed Undersampling是结合集成技术的一类欠采样方法。下面简述一下其中的两种。
1.1.2.1、EasyEnsemble
EasyEnsemble是欠采样技术和bagging的集合。
EasyEnsemble中,多次对多数类样本进行随机采样,每次采样得到的样本和少数类样本组合并训练得到一个分类器,然后将多个分类器组合,生成最终决策器。
1.1.2.2、BalanceCascade
BalanceCascade是欠采样技术和类似boosting的结合。
BalanceCascade中:
1、先从多数类中随机采样出一个和少数类数量一样的样本集,训练一个分类器;
2、找出分类器中正确分类的多数类样本,把这样样本从多数类中删除;
3、从剩余的多数类样本中从新采样,重复1-2;
4、满足某个停止条件时,生成最后的分类器。
1.1.3、SMOTE算法
SMOTE算法,Synthetic Minority Oversampling Technique,即合成少数类过采样技术,旨在解决随机过采样带来的过拟合问题。通过原始数据,合成少数类样本,从而完成过采样过程。其核心思想是,通过已知的少数类样本,合成新的少数类样本,而不是简单复制已有的少数类样本。
1.1.3.1、原始SMOTE算法
原始SMOTE算法流程如下:
1、找出每一个少数类样本在少数类样本集(这一点很重要)中的K近邻;
2、基于过采样比,从K近邻中随机找出几个少数类样本;
3、基于以下公式,生成一个样本:
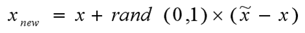
其中,x,x~分别表示一个少数类和其随机选出的近邻。
优缺点:
优点:
缓解了随机过采样带来的过拟合问题。
缺点:
合成的样本可能和多数类样本有重叠(在几何空间上和多数类样本距离比少数类更近,也就是说把原属于多数类的区域,划分为了少数类),降低了算法精度。
Tips:
据做过相关实验的同学说,在处理类似文本挖掘的样本距离可计算的问题时,SMOTE算法对于效果有很好的提升。
1.1.3.2、改进的SMOTE算法
SMOTE的改进算法的出发点主要是解决SMOTE采样的重叠问题。一种典型的改进算法思路是:
1、找出每一个少数类样本在全体样本集(这一点很重要)中的K近邻;
2、若一个少数类样本的K近邻中少数类样本多于多数类,则此样本为安全点;若其少数类样本少于多数类,且不为0,则为危险点;若其近邻中少数类样本为0,则为噪声点;
3、从危险点中,类似SMOTE合成新样本加入训练。
1.2、基于算法的方法
基于算法的方法,也可以说是基于代价矩阵的方法,是通过对不同的误分类赋予不同的权重,算法在优化目标函数的时候,自动地倾向于优化误分类权重大的样本,从而解决数据不平衡问题。
1.2.1、AdsCost算法
AdaCost借鉴了AdaBoost的思想,在Boosting的过程中,通过加大误分类样本的损失,降低正确分类样本的损失,从而进一步提升分类器的效果。
具体地,常规的AdaBoost流程如下:

以上红色字体中标出了样本权重的更新公式,这个公式是以指数损失为目标函数,以前向算法为依据,推导出来的,有良好的理论基础(更多理论分析,请参考:模型集成02-AdaBoost);但是实践表明,对于数据不平衡问题,AdaBoost中的损失函数还不够Aggressive,和传统算法一样,不能很好地处理数据不平衡问题,因此相关的研究提出了比较aggressive的权重更新方式: 每次迭代时,增大误分类样本的损失,降低正确分类样本的损失,从而得到更精确的结果,一个较优的AdaCost的更新公式如下:
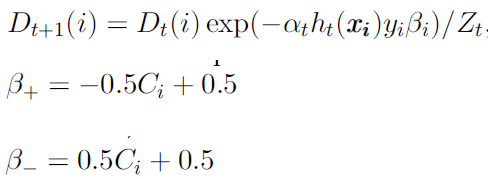
实践表明,AdaCost相对于AdaBoost对于数据不平衡问题更有效。
1.2.2、基于具体算法的方法
AdaCost是基于代价矩阵的通用算法。对于具体的算法,比如决策树、SVM、神经网络,也有特定的优化算法。这一类方法是基于算法的优化,就不深入了。
2、不平衡问题的评价指标
不同的问题,需要不同的评价指标去指导算法的优化。对于分类问题,常见的评价指标都是基于混淆矩阵,从混淆矩又可以衍生出准确率(有的地方又叫查准率,英文Pricision)、召回率(有的地方叫查全率, 英文Recall)、真正率、假负率、PRC曲线、ROC曲线、AUC曲线等概念,帮组分析分类器的性能。对于数据不平衡问题,还有一类指标,就是代价曲线。以下分别描述这些指标(关于评价指标的更多详细信息请参考: ML基础02-模型评估)。
2.1、ROC曲线和AUC
优缺点:
优点:
可以比较好地度量不平衡问题的分类效果。
缺点:
对于数据极度不平衡的问题,ROC曲线和AUC指标会乐观估计算法效果。
2.2、PRC曲线
优缺点:
优点:
对于数据极不平衡问题,PRC曲线比ROC曲线更能有效区分分类器的好坏。
缺点:
PRC曲线会出现锯齿,无法像ROC一样保证单调性。
2.3、代价曲线
如果发现文中有问题,敬请联系作者批评指正,真诚欢迎您的指教,谢谢!
微信: legelsr0808
邮箱: legelsr0808@163.com