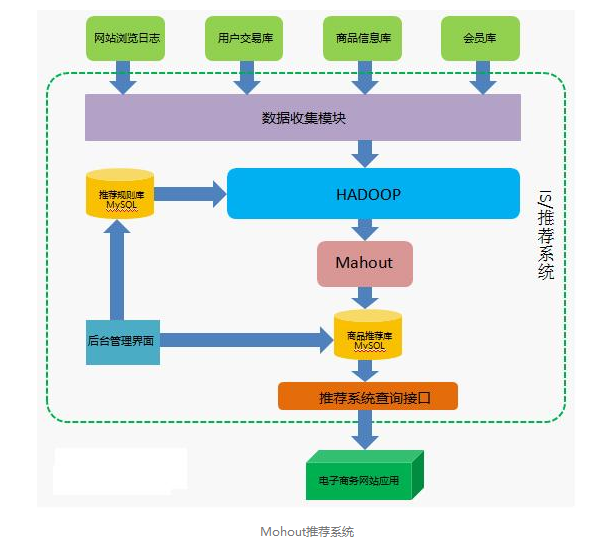
Mahout学习(主要学习内容是Mahout中推荐部分的ItemCF、UserCF、Hadoop集群部署运行)
1、Mahout是什么?
- Mahout是一个算法库,集成了很多算法。
- Apache Mahout 是 Apache Software Foundation(ASF)旗下的一个开源项目,提供一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。
- Mahout项目目前已经有了多个公共发行版本。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。
- 通过使用 Apache Hadoop 库,Mahout 可以有效地扩展到Hadoop集群。
- Mahout 的创始人 Grant Ingersoll 介绍了机器学习的基本概念,并演示了如何使用 Mahout 来实现文档集群、提出建议和组织内容。
2、Mahout是用来干嘛的?
2.1 推荐引擎
服务商或网站会根据你过去的行为为你推荐书籍、电影或文章。
2.2 聚类
Google news使用聚类技术通过标题把新闻文章进行分组,从而按照逻辑线索来显示新闻,而并非给出所有新闻的原始列表。
2.3 分类
雅虎邮箱基于用户以前对正常邮件和垃圾邮件的报告,以及电子邮件自身的特征,来判别到来的消息是否是垃圾邮件。
3、Mahout协同过滤算法
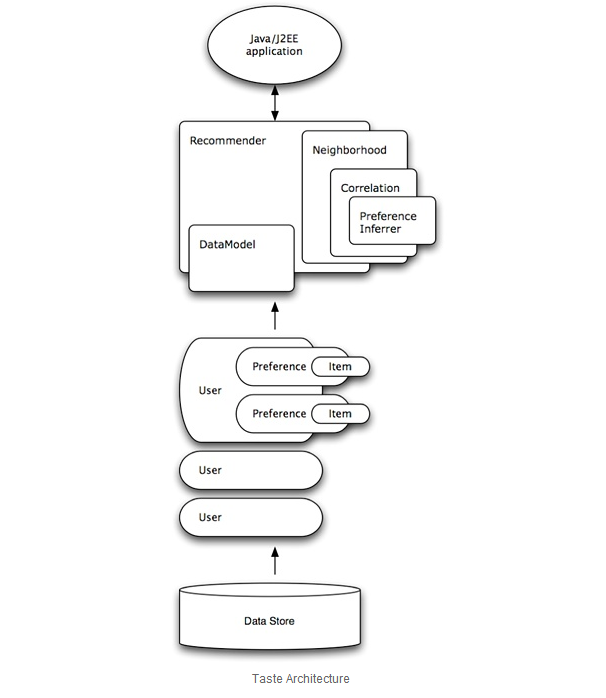
Mahout使用了Taste来提高协同过滤算法的实现,它是一个基于Java实现的可扩展的,高效的推荐引擎。Taste既实现了最基本的基于用户的和基于内容的推荐算法,同时也提供了扩展接口,使用户可以方便的定义和实现自己的推荐算法。同时,Taste不仅仅只适用于Java应用程序,它可以作为内部服务器的一个组件以HTTP和Web Service的形式向外界提供推荐的逻辑。Taste的设计使它能满足企业对推荐引擎在性能、灵活性和可扩展性等方面的要求。
Taste主要包括以下几个接口:
- DataModel 是用户喜好信息的抽象接口,它的具体实现支持从任意类型的数据源抽取用户喜好信息。Taste 默认提供 JDBCDataModel 和 FileDataModel,分别支持从数据库和文件中读取用户的喜好信息。
- UserSimilarity 和 ItemSimilarity 。UserSimilarity 用于定义两个用户间的相似度,它是基于协同过滤的推荐引擎的核心部分,可以用来计算用户的“邻居”,这里我们将与当前用户口味相似的用户称为他的邻居。ItemSimilarity 类似的,计算Item之间的相似度。
- UserNeighborhood 用于基于用户相似度的推荐方法中,推荐的内容是基于找到与当前用户喜好相似的邻居用户的方式产生的。UserNeighborhood 定义了确定邻居用户的方法,具体实现一般是基于 UserSimilarity 计算得到的。
- Recommender 是推荐引擎的抽象接口,Taste 中的核心组件。程序中,为它提供一个 DataModel,它可以计算出对不同用户的推荐内容。实际应用中,主要使用它的实现类 GenericUserBasedRecommender 或者 GenericItemBasedRecommender,分别实现基于用户相似度的推荐引擎或者基于内容的推荐引擎。
- RecommenderEvaluator :评分器。
- RecommenderIRStatsEvaluator :搜集推荐性能相关的指标,包括准确率、召回率等等。
4、Mahout协同过滤算法编程
1、创建maven项目
2、导入mahout依赖
<dependencies>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout</artifactId>
<version>0.11.1</version>
</dependency>
<dependency>
<groupId>org.apache.mahout</groupId>
<artifactId>mahout-examples</artifactId>
<version>0.11.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
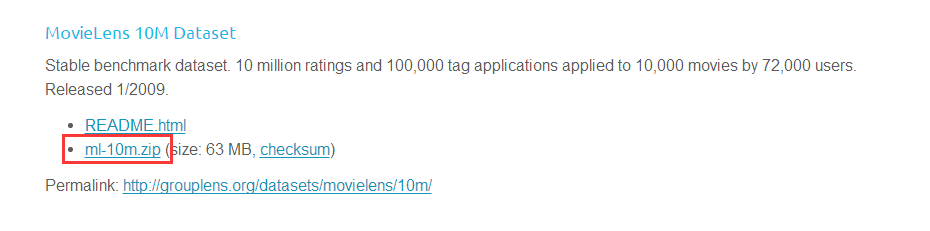
3、下载电影评分数据
下载地址:http://grouplens.org/datasets/movielens/
数据类别:7.2万用户对1万部电影的百万级评价和10万个标签数据

4、基于用户的推荐
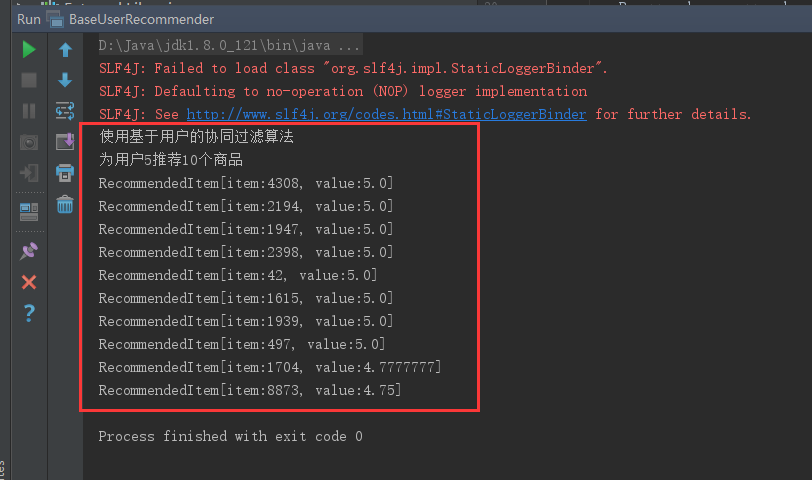
1 package com.ahu.learnmahout; 2 3 import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood; 4 import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender; 5 import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity; 6 import org.apache.mahout.cf.taste.model.DataModel; 7 import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood; 8 import org.apache.mahout.cf.taste.recommender.RecommendedItem; 9 import org.apache.mahout.cf.taste.recommender.Recommender; 10 import org.apache.mahout.cf.taste.similarity.UserSimilarity; 11 import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; 12 13 import java.io.File; 14 import java.util.List; 15 16 /** 17 * Created by ahu_lichang on 2017/6/23. 18 */ 19 public class BaseUserRecommender { 20 public static void main(String[] args) throws Exception { 21 //准备数据 这里是电影评分数据 22 File file = new File("E:\ml-10M100K\ratings.dat"); 23 //将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的 24 DataModel dataModel = new GroupLensDataModel(file); 25 //计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。 26 UserSimilarity similarity = new PearsonCorrelationSimilarity(dataModel); 27 //计算最近邻域,邻居有两种算法,基于固定数量的邻居和基于相似度的邻居,这里使用基于固定数量的邻居 28 UserNeighborhood userNeighborhood = new NearestNUserNeighborhood(100, similarity, dataModel); 29 //构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于用户的协同过滤推荐 30 Recommender recommender = new GenericUserBasedRecommender(dataModel, userNeighborhood, similarity); 31 //给用户ID等于5的用户推荐10部电影 32 List<RecommendedItem> recommendedItemList = recommender.recommend(5, 10); 33 //打印推荐的结果 34 System.out.println("使用基于用户的协同过滤算法"); 35 System.out.println("为用户5推荐10个商品"); 36 for (RecommendedItem recommendedItem : recommendedItemList) { 37 System.out.println(recommendedItem); 38 } 39 } 40 }
运行结果:
5、基于物品的推荐
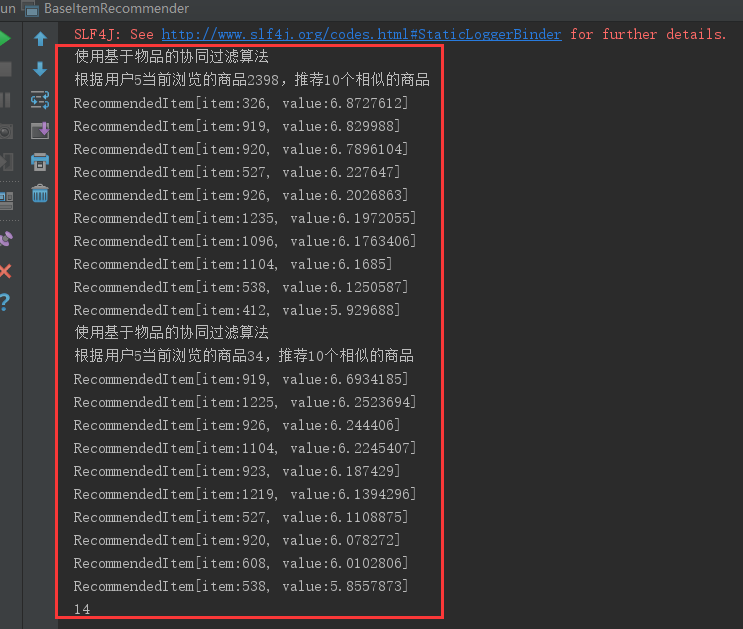
package com.ahu.learnmahout; import org.apache.mahout.cf.taste.impl.recommender.GenericItemBasedRecommender; import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity; import org.apache.mahout.cf.taste.model.DataModel; import org.apache.mahout.cf.taste.recommender.RecommendedItem; import org.apache.mahout.cf.taste.similarity.ItemSimilarity; import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; import java.io.File; import java.util.List; /** * Created by ahu_lichang on 2017/6/24. */ public class BaseItemRecommender { public static void main(String[] args) throws Exception { //准备数据 这里是电影评分数据 File file = new File("E:\ml-10M100K\ratings.dat"); //将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的 DataModel dataModel = new GroupLensDataModel(file); //计算相似度,相似度算法有很多种,欧几里得、皮尔逊等等。 ItemSimilarity itemSimilarity = new PearsonCorrelationSimilarity(dataModel); //构建推荐器,协同过滤推荐有两种,分别是基于用户的和基于物品的,这里使用基于物品的协同过滤推荐 GenericItemBasedRecommender recommender = new GenericItemBasedRecommender(dataModel, itemSimilarity); //给用户ID等于5的用户推荐10个与2398相似的商品 List<RecommendedItem> recommendedItemList = recommender.recommendedBecause(5, 2398, 10); //打印推荐的结果 System.out.println("使用基于物品的协同过滤算法"); System.out.println("根据用户5当前浏览的商品2398,推荐10个相似的商品"); for (RecommendedItem recommendedItem : recommendedItemList) { System.out.println(recommendedItem); } long start = System.currentTimeMillis(); recommendedItemList = recommender.recommendedBecause(5, 34, 10); //打印推荐的结果 System.out.println("使用基于物品的协同过滤算法"); System.out.println("根据用户5当前浏览的商品34,推荐10个相似的商品"); for (RecommendedItem recommendedItem : recommendedItemList) { System.out.println(recommendedItem); } System.out.println(System.currentTimeMillis() -start); } }
运行结果:
6、评估推荐模型
package com.ahu.learnmahout; import org.apache.mahout.cf.taste.common.TasteException; import org.apache.mahout.cf.taste.eval.RecommenderBuilder; import org.apache.mahout.cf.taste.eval.RecommenderEvaluator; import org.apache.mahout.cf.taste.impl.eval.AverageAbsoluteDifferenceRecommenderEvaluator; import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood; import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender; import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity; import org.apache.mahout.cf.taste.model.DataModel; import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood; import org.apache.mahout.cf.taste.recommender.Recommender; import org.apache.mahout.cf.taste.similarity.UserSimilarity; import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; import java.io.File; /** * Created by ahu_lichang on 2017/6/24. */ public class MyEvaluator { public static void main(String[] args) throws Exception { //准备数据 这里是电影评分数据 File file = new File("E:\ml-10M100K\ratings.dat"); //将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的 DataModel dataModel = new GroupLensDataModel(file); //推荐评估,使用均方根 //RecommenderEvaluator evaluator = new RMSRecommenderEvaluator(); //推荐评估,使用平均差值 RecommenderEvaluator evaluator = new AverageAbsoluteDifferenceRecommenderEvaluator(); RecommenderBuilder builder = new RecommenderBuilder() { public Recommender buildRecommender(DataModel dataModel) throws TasteException { UserSimilarity similarity = new PearsonCorrelationSimilarity(dataModel); UserNeighborhood neighborhood = new NearestNUserNeighborhood(2, similarity, dataModel); return new GenericUserBasedRecommender(dataModel, neighborhood, similarity); } }; // 用70%的数据用作训练,剩下的30%用来测试 double score = evaluator.evaluate(builder, null, dataModel, 0.7, 1.0); //最后得出的评估值越小,说明推荐结果越好 System.out.println(score); } }
7、获取推荐的准确率和召回率
package com.ahu.learnmahout; import org.apache.mahout.cf.taste.common.TasteException; import org.apache.mahout.cf.taste.eval.IRStatistics; import org.apache.mahout.cf.taste.eval.RecommenderBuilder; import org.apache.mahout.cf.taste.eval.RecommenderIRStatsEvaluator; import org.apache.mahout.cf.taste.impl.eval.GenericRecommenderIRStatsEvaluator; import org.apache.mahout.cf.taste.impl.neighborhood.NearestNUserNeighborhood; import org.apache.mahout.cf.taste.impl.recommender.GenericUserBasedRecommender; import org.apache.mahout.cf.taste.impl.similarity.PearsonCorrelationSimilarity; import org.apache.mahout.cf.taste.model.DataModel; import org.apache.mahout.cf.taste.neighborhood.UserNeighborhood; import org.apache.mahout.cf.taste.recommender.Recommender; import org.apache.mahout.cf.taste.similarity.UserSimilarity; import org.apache.mahout.cf.taste.similarity.precompute.example.GroupLensDataModel; import java.io.File; /** * Created by ahu_lichang on 2017/6/24. */ public class MyIRStatistics { public static void main(String[] args) throws Exception { //准备数据 这里是电影评分数据 File file = new File("E:\ml-10M100K\ratings.dat"); //将数据加载到内存中,GroupLensDataModel是针对开放电影评论数据的 DataModel dataModel = new GroupLensDataModel(file); RecommenderIRStatsEvaluator statsEvaluator = new GenericRecommenderIRStatsEvaluator(); RecommenderBuilder recommenderBuilder = new RecommenderBuilder() { public Recommender buildRecommender(DataModel model) throws TasteException { UserSimilarity similarity = new PearsonCorrelationSimilarity(model); UserNeighborhood neighborhood = new NearestNUserNeighborhood(4, similarity, model); return new GenericUserBasedRecommender(model, neighborhood, similarity); } }; // 计算推荐4个结果时的查准率和召回率 //使用评估器,并设定评估期的参数 //4表示"precision and recall at 4"即相当于推荐top4,然后在top-4的推荐上计算准确率和召回率 IRStatistics stats = statsEvaluator.evaluate(recommenderBuilder, null, dataModel, null, 4, GenericRecommenderIRStatsEvaluator.CHOOSE_THRESHOLD, 1.0); System.out.println(stats.getPrecision()); System.out.println(stats.getRecall()); } }

5、Mahout运行在Hadoop集群
1、Hadoop 执行脚本
hadoop jar mahout-examples-0.9-job.jar org.apache.mahout.cf.taste.hadoop.item.RecommenderJob --input /sanbox/movie/10M.txt --output /sanbox/movie/r -s SIMILARITY_LOGLIKELIHOOD
参数说明
- --input(path) : 存储用户偏好数据的目录,该目录下可以包含一个或多个存储用户偏好数据的文本文件;
- --output(path) : 结算结果的输出目录
- --numRecommendations (integer) : 为每个用户推荐的item数量,默认为10
- --usersFile (path) : 指定一个包含了一个或多个存储userID的文件路径,仅为该路径下所有文件包含的userID做推荐计算 (该选项可选)
- --itemsFile (path) : 指定一个包含了一个或多个存储itemID的文件路径,仅为该路径下所有文件包含的itemID做推荐计算 (该选项可选)
- --filterFile (path) : 指定一个路径,该路径下的文件包含了[userID,itemID] 值对,userID和itemID用逗号分隔。计算结果将不会为user推荐 [userID,itemID] 值对中包含的item (该选项可选)
- --booleanData (boolean) : 如果输入数据不包含偏好数值,则将该参数设置为true,默认为false
- --maxPrefsPerUser (integer) : 在最后计算推荐结果的阶段,针对每一个user使用的偏好数据的最大数量,默认为10
- --minPrefsPerUser (integer) : 在相似度计算中,忽略所有偏好数据量少于该值的用户,默认为1
- --maxSimilaritiesPerItem (integer) : 针对每个item的相似度最大值,默认为100
- --maxPrefsPerUserInItemSimilarity (integer) : 在item相似度计算阶段,针对每个用户考虑的偏好数据最大数量,默认为1000
- --similarityClassname (classname) : 向量相似度计算类
- outputPathForSimilarityMatrix :SimilarityMatrix输出目录
- --randomSeed :随机种子 -- sequencefileOutput :序列文件输出路径
- --tempDir (path) : 存储临时文件的目录,默认为当前用户的home目录下的temp目录
- --threshold (double) : 忽略相似度低于该阀值的item对
2、 执行结果
上面命令运行完成之后,会在当前用户的hdfs主目录生成temp目录,该目录可由 --tempDir (path) 参数设置.
后期学习补充:
Mahout 是基于Hadoop的机器学习和数据挖掘的一个分布式框架。Mahout用MapReduce实现了部分数据挖掘算法,解决了并行挖掘的问题。
Mahout应用场景: