作者:张富春(ahfuzhang),转载时请注明作者和引用链接,谢谢!

背景
- VM使用SSTable(Sorted string table)来存储索引中的所有key。
- 各种类型的索引会被序列化到一个[]byte数组中,每一条数据相当于可以用于索引的key.
- key会被顺序追加到一个64KB的inmemoryBlock中。
- 有N个核就会分配N个内存存储桶。例如16核就会是16个桶。
- 每个桶下面有很多个inmemoryBlock,,每个inmemoryBlock最多64KB
- KEY被顺序的追加到最后一个inmemoryBlock;写满64KB就再申请一个。
- 达到512个inmemoryBlock后(也就是数据总量达到32MB),开始对每个inmemoryBlock进行压缩
本文就是解读inmemoryBlock的压缩过程。
压缩之前,会对inmemoryBlock内的所有KEY进行排序。
入口函数
func (ib *inmemoryBlock) marshalData这个函数实现了以下能力:
- 拷贝一个inmemoryBlock数据块的firstItem(也就是排序后的第一条数据)
- 拷贝一个inmemoryBlock数据块的commonPrefix (所有KEY都有的公共前缀)
- 对所有的KEY进行序列化,并做ZSTD压缩
- 记录所有KEY的长度,对长度进行序列化
下面主要讲述KEY的序列化方法。
SSTable中对KEY的压缩存储方法
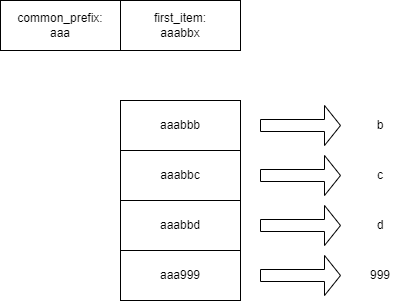
对面对的问题,也可以描述为: 存在N条排好序的字符串,字符串之间存在公共前缀。如何存储才能使得存储空间最优?
我直接说结论:
- 因为所有的字符串计算出了公共前缀,因此每个字符串的公共前缀不需要再存储了。
- 为了便于在块之间索引数据,提前了第一条KEY作为块的索引项。因为第一条数据提取为块的索引,所以数据从第二条开始存储就行了。(连这一点点都要省,所以我采用吝啬来形容)
- 公共前缀是所有KEY的前缀,且公共前缀很可能是空字符串。排序的KEY除了公共前缀外,两两之间还有共同的前缀。因此可以计算出这部分长度,后一个字符串只要存储与前一个字符串前缀以外的内容就行了。
- 两个字符串之间的公共前缀是多长呢?得记录下来。一组长度信息中,前一个值和后一个值可以取异或计算。相当于两个值高位的bit值相同的部分就被置0了,然后就得到了一个较小的值。小的值更容易压缩。
- 对于数值的序列化,这里用了protocol buffers中的一个技巧:用7bit来表示数值的内容,最高位说明后面的一个字节是否也表示长度。这样就可以用变长长度来序列化数值,而不是每个数值都占用固定的长度。
- 最后序列化后的KEY和长度,进行ZSTD压缩。
源码
我对源码进行了详细的注释:
// Preconditions:
// - ib.items must be sorted.
// - updateCommonPrefix must be called. // 序列化数据的函数
func (ib *inmemoryBlock) marshalData(sb *storageBlock, firstItemDst, commonPrefixDst []byte, compressLevel int) ([]byte, []byte, uint32, marshalType) {
if len(ib.items) <= 0 {
logger.Panicf("BUG: inmemoryBlock.marshalData must be called on non-empty blocks only")
}
if uint64(len(ib.items)) >= 1<<32 {
logger.Panicf("BUG: the number of items in the block must be smaller than %d; got %d items", uint64(1<<32), len(ib.items))
}
data := ib.data
firstItem := ib.items[0].Bytes(data)
firstItemDst = append(firstItemDst, firstItem...) // 第一个time series
commonPrefixDst = append(commonPrefixDst, ib.commonPrefix...) // 最大公共前缀
if len(ib.data)-len(ib.commonPrefix)*len(ib.items) < 64 || len(ib.items) < 2 {
// Use plain encoding form small block, since it is cheaper.
ib.marshalDataPlain(sb)
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
bbItems := bbPool.Get()
bItems := bbItems.B[:0] //保存目的 items 数据的内存buffer
bbLens := bbPool.Get()
bLens := bbLens.B[:0] // 保存目的 lens 数据的内存buffer
// Marshal items data.
xs := encoding.GetUint64s(len(ib.items) - 1) //??? 为什么要减1 猜测是firstItem单独存储了,所以就没必要在序列化中的数据再存储一次
defer encoding.PutUint64s(xs) // xs 保存两两比较公共前缀后的 异或后的 前缀值
cpLen := len(ib.commonPrefix) // 公共前缀的长度
prevItem := firstItem[cpLen:]
prevPrefixLen := uint64(0)
for i, it := range ib.items[1:] { //从第二个元素开始遍历
it.Start += uint32(cpLen) //偏移到公共前缀之后的位置
item := it.Bytes(data) //这里得到的[]byte就不包含公共前缀的部分
prefixLen := uint64(commonPrefixLen(prevItem, item)) //计算第N项和N-1项的公共前缀
bItems = append(bItems, item[prefixLen:]...) //仅仅只把差异的部分拷贝到目的buffer. 为了节约存储空间,差异的部分不存储进去。牛逼!
xLen := prefixLen ^ prevPrefixLen //第一次,与0异或,还是等于原值。异或后,两个整数值前面相同的部分都为0了,数值变得更短,能够便于压缩。
prevItem = item //上次的除去公共前缀的item
prevPrefixLen = prefixLen //上次计算得到的公共前缀
xs.A[i] = xLen //异或后的公共前缀值
}
bLens = encoding.MarshalVarUint64s(bLens, xs.A) //对N-1个长度进行序列化
sb.itemsData = encoding.CompressZSTDLevel(sb.itemsData[:0], bItems, compressLevel) //压缩后,写入storageBlock
//先两两去掉公共前缀,然后再ZSTD压缩
bbItems.B = bItems
bbPool.Put(bbItems)
// Marshal lens data.
prevItemLen := uint64(len(firstItem) - cpLen)
for i, it := range ib.items[1:] { //前面记录了两两的相对长度,这里记录完整长度.
itemLen := uint64(int(it.End-it.Start) - cpLen) //todo: 完整长度可以推算出来,应该可以不用记录才对
xLen := itemLen ^ prevItemLen
prevItemLen = itemLen
xs.A[i] = xLen
}
bLens = encoding.MarshalVarUint64s(bLens, xs.A) //长度信息包含两种,相对长度和总长度
sb.lensData = encoding.CompressZSTDLevel(sb.lensData[:0], bLens, compressLevel) //对长度信息序列化,然后压缩
bbLens.B = bLens
bbPool.Put(bbLens)
if float64(len(sb.itemsData)) > 0.9*float64(len(ib.data)-len(ib.commonPrefix)*len(ib.items)) {
// Bad compression rate. It is cheaper to use plain encoding.
ib.marshalDataPlain(sb) //压缩率不高的时候,选择不压缩
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypePlain
}
// Good compression rate.
return firstItemDst, commonPrefixDst, uint32(len(ib.items)), marshalTypeZSTD
}