本篇文章将重点讲解HanLP的ViterbiSegment分词器类,而不涉及感知机和条件随机场分词器,也不涉及基于字的分词器。因为这些分词器都不是我们在实践中常用的,而且ViterbiSegment也是作者直接封装到HanLP类中的分词器,作者也推荐使用该分词器,同时文本分类包以及其他一些自然语言处理任务包中的分词器也都间接使用了ViterbiSegment分词器。
今天的文章还会介绍各分词词典文件的使用位置以及作用,相信小伙伴们看了今天的文章应该不会再在github上提出干预自定义不生效的问题了。进入正题,本篇的内容比较多,建议收藏后再细读。
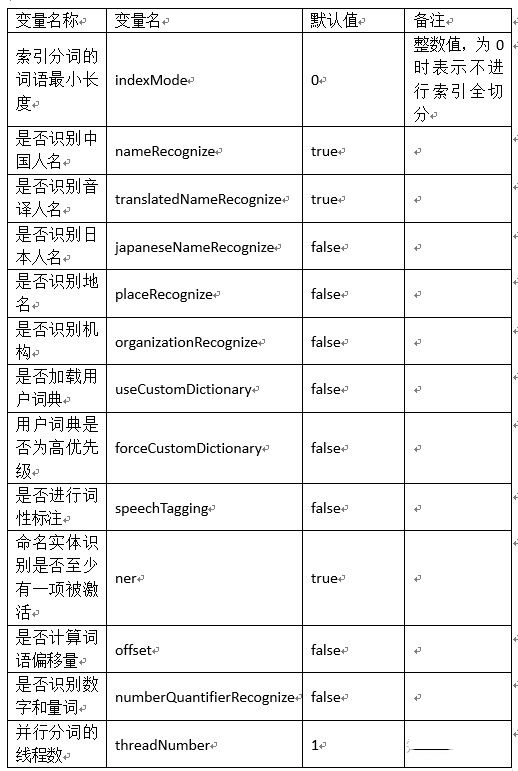
1. 分词器配置变量
分词器的相关配置定义在Config.java类中,这里我们将分词相关的所有配置变量列于下表
这种配置类什么时候实例化呢,不用想肯定是分词开始前就会实例化,拿HanLP类中的ViterbiSegment分词类举例。该类的继承关系用如下图所示:
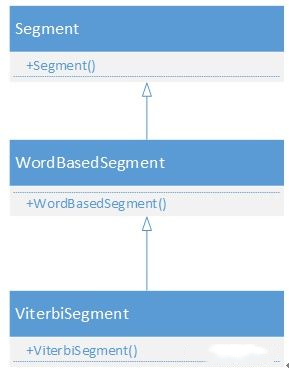
由继承关系图可以看到,只要实例化ViterbiSegment则首先会执行Segment()初始化,在该方法中实例化分词器配置对象config。这些配置变量都是公有变量,因此可以在ViterbiSegment类实例化为对象后直接在外部修改。那么什么时候来使用这些配置变量呢,当然是在分词的时候,具体是哪个类的哪个方法呢,当然是ViterbiSegment类的List<Term> segSentence(char[] sentence)方法。
另外请注意上边的3个类,所有ViterbiSegment的分词方法都集中在这3个类中。
2. 词典的使用条件和先后顺序(也介绍分词流程)
我们知道了词典配置变量使用的位置后,就可以确定每个词典的使用条件了以及每个词典的使用顺序
1. 词语粗分
(1)构建词图
对应方法为void generateWordNet(final WordNet wordNetStorage),在此方法中系统使用CoreNatureDictionary.txt文件切分出所有可能的分词路径。此时如果配置变量useCustomDictionary为true,则将CustomDictionary.txt中的词也考虑进来,说明CustomDictionary.txt优先级会高。另外大家可以看到CoreNatureDictionary.txt实际上也充当了隐马词性标注的发射矩阵,里边某些多词性词也列出了词性序列以及各词性对应的频次。
(2)用户定制词典干预
如果配置变量useCustomDictionary为true,即需要使用CustomDictionary.txt进行干预,则执行下边对应的方法,否则跳过该步骤。用户词典干预根据是否进行全切分有两种不同方法:当配置变量indexMode>0时,即系统处于全切分模式时,对应方法为
List<Vertex> combineByCustomDictionary(List<Vertex> vertexList, DoubleArrayTrie<CoreDictionary.Attribute> dat, final WordNet wordNetAll),
如果indexMode=0,即系统处于普通分词模式,对应方法为
List<Vertex> combineByCustomDictionary(List<Vertex> vertexList, DoubleArrayTrie<CoreDictionary.Attribute> dat)。
从调用的方法我们不难看出,全切分时系统会根据CustomDictionary.txt添加分词路径。而普通切分时,系统会根据CustomDictionary.txt合并路径。这也就是为什么有的时候明明已经在CustomDictionary.txt中添加了新词却不生效的原因,因为一旦根据CoreNatureDictionary.txt构建了词图就不会再有新的路径插到已有分词路径中间,此时就去查找并修改CoreNatureDictionary.txt中的相关字或词吧。
(3)维特比选择最优路径
对应方法为List<Vertex> viterbi(WordNet wordNet),至此就得到了一个粗分的分词结果。需要注意HanLP的Viterbi分词只是用viterbi方法求解最优路径,并不是隐马。
3. 数字识别
如果配置变量numberQuantifierRecognize为true,则在粗分结果的基础上进行数字合并操作,否则直接跳过该步。对应方法为
void mergeNumberQuantifier(List<Vertex> termList, WordNet wordNetAll, Config config)。
4. 实体识别
配置变量ner为true时,则需要进行各种实体的识别,继续向下执行。需要注意该变量受其他实体识别变量影响,只要其他任意实体配置变量为true,则ner就会为true。如果ner为false,则跳过下边各项实体识别继续词性标注环节。
(1)中国人名识别
执行此步,配置变量nameRecognize必须为true。调用方法为
PersonRecognition.recognition(vertexList, wordNetOptimum, wordNetAll)。人名使用隐马,因此有转移矩阵nr.tr.txt和发射矩阵nr.txt。由于HanLP不提供训练语料,我们自己也很难得到有角色标注的语料,因此我们一般只修改nr.txt文件,删除nr.txt.bin文件后生效。
(2)音译人名识别
执行此步,配置变量translatedNameRecognize必须为true。调用方法为
TranslatedPersonRecognition.recognition(vertexList, wordNetOptimum, wordNetAll)。需要注意音译人名的识别没有用隐马,就是匹配分词法。涉及到的词典为nrf.txt,如果用户修改该词典,则需要删除nrf.txt.trie.dat使其生效。
(3)日本人名识别
执行此步,配置变量japaneseNameRecognize必须为true。调用方法为
JapanesePersonRecognition.recognition(vertexList, wordNetOptimum, wordNetAll)。需要注意日本人名的识别没有用隐马,就是匹配分词法。涉及到的词典为nrj.txt,如果用户修改该词典,则需要删除nrj.txt.trie.dat和nrj.txt.value.dat使其生效。
(4)地名识别
执行此步,配置变量placeRecognize必须为true。调用方法为
PlaceRecognition.recognition(vertexList, wordNetOptimum, wordNetAll)。地名使用隐马,因此有转移矩阵ns.tr.txt和发射矩阵ns.txt。由于HanLP不提供训练语料,我们自己也很难得到有角色标注的语料,因此我们一般只修改ns.txt文件,删除ns.txt.bin文件后生效。
(5)机构名识别
执行此步,配置变量organizationRecognize必须为true。调用方法为
OrganizationRecognition.recognition(vertexList, wordNetOptimum, wordNetAll)。注意这里在调用机构名识别之前先进行了一次识别,也就是层叠隐马,而人名和地名的识别就是普通的隐马。机构名的识别使用层叠隐马,涉及的文件有转移矩阵nt.tr.txt和发射矩阵nt.txt。由于HanLP不提供训练语料,我们自己也很难得到有角色标注的语料,因此我们一般只修改nt.txt文件,删除ns.txt.bin文件后生效。机构名的识别需要人名地名识别具有较高准确率。
至此,分词流程已全部介绍了。
还需要注意下边的内容
其他没有在系统中使用的词典有
机构名词典.txt
全国地名大全.txt
人名词典.txt
上海地名.txt
现代汉语补充词库.txt
这些词典是对系统中的词典的更新记录,如果你添加了新的人名、地名、机构名可以在这里添加保存。
另外,如果需要添加人名、地名、机构名可以直接在CoreNatureDictionary.txt中添加,最好是3字以上实体,
如果要去掉错误识别的命名实体可以直接在相应的nr.txt,ns.txt,nt.txt中添加。
3. 多线程分词
HanLP的ViterbiSegment分词器类是支持多线程的,线程数量由配置变量threadNumber决定的,该变量默认为1。HanLP作者说ViterbiSegmet分词效率最高的原因肯定也有ViterbiSegment分词器支持多线程分词这个因素。另外由于ViterbiSegment分词器内部所具有的相关命名实体功能,因此这些命名实体识别的效率也会很高。在哪里实现的多线程分词呢,在Segment类的List<Term> seg(String text)这个方法中实现的,需要注意HanLP的多线程分词指的是一次输入了一个长文本,而不是一次处理多个输入文本。
本文分享自 baiziyu 的专栏,正文内容已经做了部分修改,便于大家阅读,欢迎一起交流学习!