而人类之所以能够快速学习的关键是人类具备学会学习的能力,能够充分的利用以往的知识经验来指导新任务的学习,因此Meta Learning成为新的攻克的方向。
但是Meta Learning因为具备学会学习的能力,或许也可以学会思考
学会学习最主要的能力是在面对类似的任务时能够利用历史经验,加速网络的训练学习
现在的meta learning方式主要分为一下几类:
基于记忆Memory的方法
基本思路:既然要通过以往的经验来学习,那么是不是可以通过在神经网络上添加Memory来实现呢
基于预测梯度的方法
基本思路:既然Meta Learning的目的是实现快速学习,而快速学习的关键一点是神经网络的梯度下降要准,要快,那么是不是可以让神经网络利用以往的任务学习如何预测梯度,这样面对新的任务,只要梯度预测得准,那么学习得就会更快了?
利用Attention注意力机制的方法
基本思路:人的注意力是可以利用以往的经验来实现提升的,比如我们看一个性感图片,我们会很自然的把注意力集中在关键位置。那么,能不能利用以往的任务来训练一个Attention模型,从而面对新的任务,能够直接关注最重要的部分。
借鉴LSTM的方法
基本思路:LSTM内部的更新非常类似于梯度下降的更新,那么,能否利用LSTM的结构训练出一个神经网络的更新机制,输入当前网络参数,直接输出新的更新参数?
面向RL的Meta Learning方法
基本思路:既然Meta Learning可以用在监督学习,那么增强学习上又可以怎么做呢?能否通过增加一些外部信息的输入比如reward,之前的action来实现?
通过训练一个好的base model的方法,并且同时应用到监督学习和增强学习
基本思路:之前的方法都只能局限在或者监督学习或者增强学习上,能不能搞个更通用的呢?是不是相比finetune学习一个更好的base model就能work?
利用WaveNet的方法
基本思路:WaveNet的网络每次都利用了之前的数据,那么是否可以照搬WaveNet的方式来实现Meta Learning呢?就是充分利用以往的数据呀?
预测Loss的方法
基本思路:要让学习的速度更快,除了更好的梯度,如果有更好的loss,那么学习的速度也会更快,因此,是不是可以构造一个模型利用以往的任务来学习如何预测Loss呢?
现在所了解的两种meta learning 方式:
1.先构建出一个初始化网络,后面在根据新任务的需求微调初始化网络,从而实现加速学习的能力
2.让AI在学习各种任务后形成一个核心的价值网络,从而面对新的任务时,可以利用已有的核心价值网络来加速AI的学习速度!
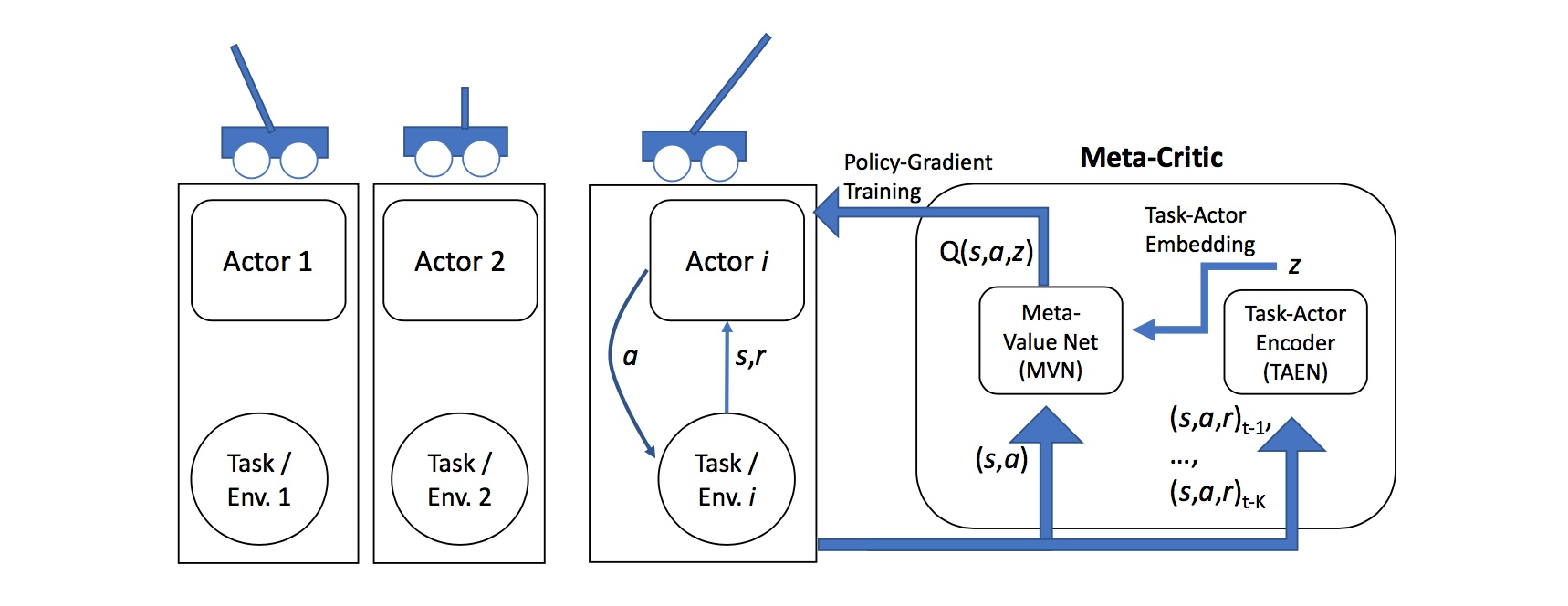
上图为Meta-Critic Network的基本示意图。我们以CartPole这个让杆保持平衡的任务来做分析。在我们这里,杆的长度是任意的,我们希望AI在学习了各种长度的杆的任务后,面对一个新的长度的杆,能够快速学习,掌握让杆保持平衡的诀窍。
怎么做呢?
每一个训练任务我们都构造一个行动网络(Actor Network),但是我们只有一个核心指导网络(Meta-Critic Network),这个网络包含两部分:一个是核心价值网络(Meta Value Network),另一个则是任务行为编码器(Task-Actor Encoder)。
我们用多个任务同时训练这个Meta Critic Network。训练方式可以是常见的Actor-Critic。训练时最关键的就是Task-Actor Encoder,我们输入任务的历史经验(包括状态state,动作action,和回馈reward),然后得到一个任务的表示信息z,将
z和一般价值网络的输入(状态state和动作action)连接起来,输入到Meta Value Network中。
通过这种方式,我们可以训练出一个Meta Critic Network。面对新的任务(也就是杆的长度变化了),我们新建一个行动网络Actor Network,但是却保持Meta Critic Network不变,然后同样使用Actor-Critic方法进行训练。这个时候,效果就出来了,
我们可以学的非常快:
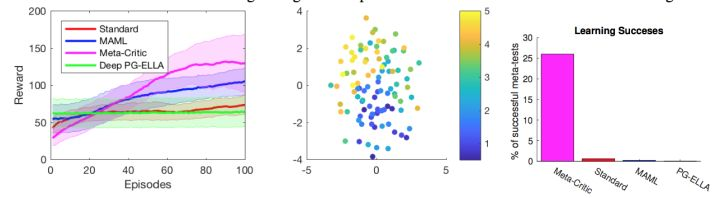
看第一个图的紫色学习曲线,reward的上升速度非常快,standard是完全的Actor-Critic训练,基本就还是平的(一般对于CartPole任务需要训练几千次才能收敛到195的得分通过任务)。然后看右边第三个图,在仅仅玩100个杆训练后,Meta-Critic方法就
能够达到25%通过任务的成功率,而其他方法都还早着呢。实际上paper也没有显示的一个结果是基于Meta Critic Network训练300步可以让任务通过率基本达到100%。这种结果非常的promising!那么我们会关心任务行为编码器(Task-Actor Encoder)学
到了什么?于是我们把不同任务的z提取出来用t-SNE显示如中间那个图所示。然后我们惊讶的发现z的分布和CartPole杆的长度是直接相关的,这意味着任务行为编码器确实可以利用以往的经验来理解一个任务的配置信息。