1、设一组权值集合W={2,3,4,5,6},则由该权值集合构造的哈夫曼树中带权路径长度之和为()。 45
如图:

因为9大于5、6,所以5、6变成最小,因此将5、6放于右边。
2、折半查找有序表(4,6,10,12,20,30,50,70,88,100)。若查找表中元素58,则它将依次与表中哪些元素比较大小,查找结果失败()
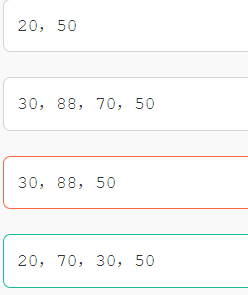
middle=(low+high)/2,因此应选用20作为中间值
58>20,因此选择右边,右边中间值为70,70>58,选择左边。
30>20,因此选择右边,查找失败。
3、字符串”qiniu”根据顺序不同有多少种排列组合的方式? 60
组合方式5!=120种,有重复的i,所以120除以2=60种。
4、在ASC算法team日常开发中,常常面临一些数据结构的抉择,令人纠结。目前大家在策划一个FBI项目(Fast Binary Indexing),其中用到的词汇有6200条,词汇长度在10-15之间,词汇字符是英文字母,区分大小写。请在下面几个数据结构中选择一个使检索速度最快的: 字典树(Trie树,寻找子节点开销:1次运算/每字符)
Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希表高。
5、以下哪些算法可用于遍历网络图? 广度优先,深度优先。
广度优先:广度优先搜索是从图的某个顶点v0出发,在访问v0之后,依次搜索访问v0的各个未被访问过的邻接点w1,w2,…。然后顺序搜索访问w1的各未被访问过的邻接点,w2的各未被访问过的邻接点。
深度优先:假定给定图G的初态是所有顶点均未被访问过,在G中任选一个顶点i作为遍历的初始点,则深度优先搜索递归调用包含以下操作:
(1)访问搜索到的未被访问的邻接点;
(2)将此顶点的visited数组元素值置1;
(3)搜索该顶点的未被访问的邻接点,若该邻接点存在,则从此邻接点开始进行同样的访问和搜索。
注:决策树是机器学习算法、线性规划用于求极值。
6、一个无向图G=(V,E),顶点集合V={1,2,3,4,5,6,7},边集合E={(1,2), (1,3),(2,4), (3,4), (4,5),(4,6), (5,7) , (6,7)},从顶点1出发进行深度优先遍历,可得到的顶点序列是 ( )

深度优先遍历是指从一个节点出发,一个走到其中邻居节点,将该邻居节点标记为已遍历,然后从该节点出发,重复上述步骤,知道遇到节点的出度为0或,节点的邻居都已遍历,再返回到最开始出发的节点,找到其未遍历的另一个邻居节点,重复上面的步骤即可
答案为:1、2、4、6、7、5、3 或 1、2、4、5、7、6、3 或 1、3、4、5、7、6、2