文章的题目转自http://www.cnblogs.com/isLiu/p/7811731.htm
自我感觉可能没有人家厉害,但是自己也不想太过认输。就借用人家的题目来锻炼一下自己吧。本人一样作为大三狗,但是还是有一颗想成为大神的心的。立博为证,持续更新。文中有答案不对欢迎指出。
-----------------------------------以上更新自2018-02-26 23:24:39---------------------------------------
百度第一次
一面
1.AJAX流程
var ajax;
if (window.XMLHttpRequest){
ajax=new XMLHttpRequest();
}
else{
ajax=new ActiveXObject("Microsoft.XMLHTTP");
}
ajax.onreadystatechange=function(){
if (ajax.readyState==4 && ajax.status==200){
document.getElementById("div1").innerHTML=ajax.responseText;
}
}
ajax.open("GET","1.txt",true);
ajax.send();
ajax是一种可以不刷新整体网页,就可以改变网页内部数据的一种技术,大致可以分为四个步骤
1.创建ajax对象,根据不同浏览器创建不同的ajax对象
2.处理响应,也就是请求结束返回的时候给一个方法。
3.打开连接,open内部参数来确定传输方式、请求文件、和是否异步。这里面true代表异步
4.发送请求。
给我感觉就是将js的一个对象处理打包,最后发出去。当然其中还有很多比如状态码之类的。
2.promise简单说一下
所谓的promise我了解的不是很多。es6中的很多东西还没有系统的学习,在我初步的印象里promise是一个es6中用来简便回调函数的东西,项目中代码一旦过多就会导致回调套用回调,最后会将逻辑弄得一团糟,所以es6中就出现了promise用来解决此类问题。promise中我也只是知道有.then和.catch。分别用来处理响应正确,或者错误的时候捕获错误信息。
3.手写一个箭头函数
es6中较为简单的箭头函数
()=>{} 大致是这样的把。。类比之前的
function(){} 传递参数都是在()内部,方法具体在{}。
es6还是了解比较少,有空还得多看看啊。。。
4.链式调用
链式调用在日常使用的时候还是比较多的,比如js中的的链式调用,也就是例如这样
oIn.charAt(0).toUpperCase()----oIn代表一个普通的字符串,将字符串第一个提取出来并且转化为大写字母。js中的链式调用
$(oDiv).show().hide()-----oDiv代表一个普通的div对象,将此div显示出来以后隐藏。jquery中的链式调用
5.简单的观察者模式
观察者模式在我眼里就是说当有一个主体和多个观察者的时候,观察者通过某种方式可以去访问或者观察主体的某些变化,但是观察者自身却是相互独立互不影响的,当然想实现就没有说的这么容易了。
https://www.cnblogs.com/LuckyWinty/p/5796190.html参考
6.let、const
对于let和const,是es6中声明变量新增的俩种方式,其中let是作为一个具有块级作用域声明的变量存在的,之前使用var的时候,只有通过闭包来达到块级作用域的效果,现在可以通过let直接实现。
const给我感觉是类似java中final的一个变量。它定义的时候必须进行初始化赋值,而且在后面不让你再次更改。
7.数组去重
对于数组去重就比较多的方法了。最简单的使用双重for循环来去重。
Array.prototype.de_repeat=function(){
var arr=this;
var rt=[];
for(let i=0;i<arr.length;i++){
for(let j=i+1;j<arr.length;j++){
if(arr[i]===arr[j]){
i=i+1;
j=i;
}
}
rt.push(arr[i]);
console.log(rt,i)
}
return rt;
}
var a=[1,1,2,2,1];
alert(a.de_repeat());
除此之外还可以直接使用数组的splice方法进行重复数据删除。但是比较占用计算资源。
es6中还有一个set的数据结构,好像也可以去重。
function dedupe(array){
return Array.from(new Set(array));
}
alert(dedupe([1,1,2,3,3,1,2,3,22,3,2,1]));
当然还有许多方法。就不一一说了
8.判断数据类型,null怎么判断
在js中判断null的数据类型比较特殊。我们可以使用
var a = null;
if(a!=undefiend&&a!=0&&!a)等等巨麻烦的方法去写。我倒是觉得直接使用===就可以解决了。
9.正则 电话区号+座机号,并给区号加上括号
/^(0[0-9]{2,3})[0-9]{7,8}$/ 这应该是最简单的了吧。当然很多也许没写全。其实就是电话座机的规则了解的有些少。
10.MVC、MVP、MVVM
mvc 代表 m:model模型、v:view视图、controller控制器 一种编程模式,这种mvc大多和java应用的比较多吧?有名的比如springmvc框架 。
mvp mv和mvc一样,p代表着presenter,是一种mvc的进化版之一,它切断了mv之间的联系,将其分开独立开发。
mvvm mv依旧一样,vm代表viewmodel,从前端产生的一个概念,也是mvc的进化版。其实我更感觉他是mvp的进化版。他也是将view和model之间切断。实现了书记的绑定,自动的双向同步减少程序员去写某些例子.准确的说,是将数据给转化成view中能理解的意思展现出来,比如数据中sex表示0为男1为女,那么也就将其转化成展示层能显示的代码。
11.TopK用的什么排序
对于topk问题就是如果有很多的数据,然后提取出来其中最大的或者最小的数据,或几个数据。对此有很多办法,但是我了解的只有使用堆排序,之后不断的提取最大或者最小数。达到解决问题的办法。
12.堆排序的时间复杂度、稳定性,什么是稳定排序
关于堆排序的时间复杂度O(n*logn),是不稳定的排序。
所谓的稳定排序是指如果序列中存在相同的部分,那么在排序之后的序列中,仍按照开始的顺序排列。比如
4,3,1(第一个1),2,1(第二个1)、那么输出的排序结果,如果是不稳定的就是1(第二个),1(第一个),2,3,4、如果是稳定的那么结果就是1(第一个),1(第二个),2,3,4
13.基本有序的数组用什么排序
这个其实是真的不是很了解,上网查阅学习了一下,对于基本有序的数组最好使用插入排序。所谓的基本有序就是指大多数数据都已经有了顺序,只是部分数据有疑问。
插入排序的大概意思就是将一个数组序列分为俩个部分,一个部分为排序完的部分,一各部分为没有排序的部分,每次提取出一个数据对应找到排序完部分的相应位置并放入。找到了一个比较通俗易懂的代码。当然不是js的,而是c的 。
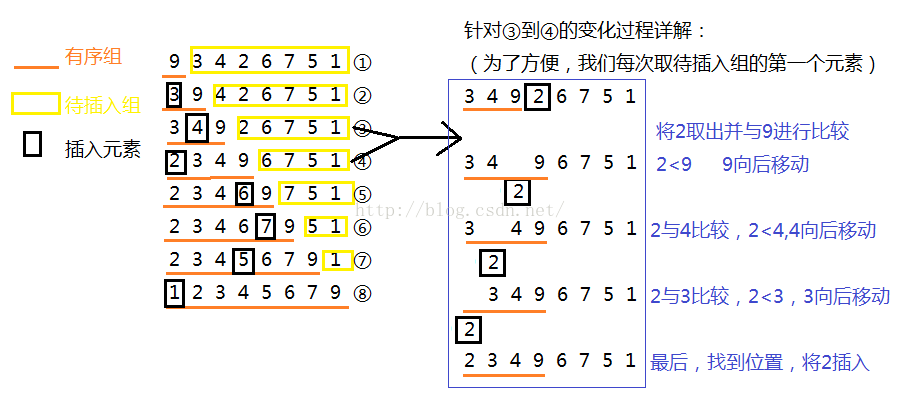
#include<stdio.h>
void InsertionSort(int *num,int n)
{
int i = 0;
int j = 0;
int tmp = 0;
for(i = 1;i<n;i++)
{
tmp = num[i];//从待插入组取出第一个元素。
j = i-1; //i-1即为有序组最后一个元素(与待插入元素相邻)的下标
while(j>=0&&tmp<num[j]) //注意判断条件为两个,j>=0对其进行边界限制。第二个为插入判断条件
{
num[j+1] = num[j];//若不是合适位置,有序组元素向后移动
j--;
}
num[j+1] = tmp;//找到合适位置,将元素插入。
}
}
int main()
{
int i = 0;
int num[8]={9,3,4,2,6,7,5,1};
InsertionSort(num,8);
/*这个函数必须知道元素的个数,所以将元素个数传入。
有心者可以在函数内部用sizeof求出元素个数 */
for(i=0;i<8;i++)
{
printf("%d ",num[i]);
}
return 0;
}
14.冒泡排序时间复杂度,最好的情况的时间复杂度
冒泡排序的时间复杂度是O(n^2),最好情况的时间复杂度是O(n),对此其实就是对算法进行了优化.
var a=[2,3,1,4,5];
function aa () {
// body...
for(var i=0;i<a.length-1;i++){
var b=false;
for(var j=0;j<a.length-1;j++){
if(a[j]>a[j+1]){
var t=0;
t=a[j];
a[j]=a[j+1];
a[j+1]=t;
b=true;
}
}
if(b==false) return;
}
}
aa();
alert(a)
最后发现算法的问题确实比较多,也应该认真的再看一看了。各种算法的复杂度大概如下,建议算法这些东西还不是背的。一样一样去学习理解了就会发现这些东西都很容易记住的。
| 排序法 | 平均时间 | 最差情形 | 稳定度 | 额外空间 | 备注 |
| 冒泡 | O(n2) | O(n2) | 稳定 | O(1) | n小时较好 |
| 交换 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 选择 | O(n2) | O(n2) | 不稳定 | O(1) | n小时较好 |
| 插入 | O(n2) | O(n2) | 稳定 | O(1) | 大部分已排序时较好 |
| 基数 | O(logRB) | O(logRB) | 稳定 | O(n) |
B是真数(0-9), R是基数(个十百) |
| Shell | O(nlogn) | O(ns) 1<s<2 | 不稳定 | O(1) | s是所选分组 |
| 快速 | O(nlogn) | O(n2) | 不稳定 | O(nlogn) | n大时较好 |
| 归并 | O(nlogn) | O(nlogn) | 稳定 | O(1) | n大时较好 |
| 堆 | O(nlogn) | O(nlogn) | 不稳定 | O(1) | n大时较好 |
-----------------------------------以上更新自2018-03-01 19:45:21----------------------------------------
二面
1.三栏布局
对于三栏布局其实就是说将左右布局定死宽度,中间的块可以随时改变大小。
对于此最基础的几种想法分别是。
1.float方式,仅仅需要注意一下,我们所使用的办法中需要将第三个div当做不设置float,依赖float属性的脱离文档流使其达到自适应的效果。
<style> div{ height:200px; } div:nth-child(1){ 300px; float: left; background: red; } div:nth-child(2){ float: right; 300px; background: black; } div:nth-child(3){ background: blue; } </style> <div></div> <div></div> <div></div>
2.使用position定位来达到目的
<style> div{ position: absolute; height:200px; } div:nth-child(1){ 300px; left: 0px; background: red; } div:nth-child(2){ left: 300px; right: 300px; background: black; } div:nth-child(3){ 300px; right: 0px; background: blue; } </style> <div></div> <div></div> <div></div>
3.使用flex布局达到目的
<style> article{ display: flex; } div{ height:200px; } div:nth-child(1){ 300px; background: red; } div:nth-child(2){ flex: 1; background: black; } div:nth-child(3){ 300px; background: blue; } </style> <article> <div></div> <div></div> <div></div> </article>
4.借用table形式,在display处设置属性值为table。另外在内部每个div设置table-cell 代表着将内部元素当做table的th或者td来使用
<style> article{ display: table; 100%; height:200px; } div{ display: table-cell; } div:nth-child(1){ 300px; background: red; } div:nth-child(2){ background: black; } div:nth-child(3){ 300px; background: blue; } </style> <article> <div></div> <div></div> <div></div> </article>
5.可以使用css3诞生的grid。grid其实对于我感觉就是进化版的flexbox。更加完善,功能更加多。但是相应的参数也多了很多。(想更多学习grid就可以到https://www.cnblogs.com/xiaohuochai/p/7083153.html。讲得非常全。)
<style> #page { display: grid; 100%; height: 250px; grid-template-areas: "head head" "nav main" "foot foot"; grid-template-rows: 50px 1fr 30px; grid-template-columns: 150px 1fr; } #page > header { grid-area: head; background-color: #8ca0ff; } #page > nav { grid-area: nav; background-color: #ffa08c; } #page > main { grid-area: main; background-color: #ffff64; } #page > footer { grid-area: foot; background-color: #8cffa0; } </style> <section id="page"> <header>Header</header> <nav>Navigation</nav> <main>Main area</main> <footer>Footer</footer> </section>
以上代码看完链接应该很容易就理解了。
2.position值
对于position值的解释我感觉不是很复杂。首先position具有以下几种属性值,
1.relative,称作为相对定位属性。其相对定位的是其父级元素,也就是说包裹的元素。
2.absolute,被称为绝对定位,其绝对定位的是整体网页的左上角。注意使用这种属性的时候该元素会脱离文档流,可能会影响布局
3.fixed,作为相对浏览器窗口的定位存在,也就是滚动滚动条的时候它不跟随滚动。
4.static,默认值
5.inherit,继承父元素的值。
注:在使用中如果包裹的父元素声明了relative,那么如果子元素声明了absolute,其子元素定位就不再是相对于整体网页的左上角了。而是简单相对父元素进行定位。
3.让元素不可见
达到元素不可见的手段有很多
1.元素使用display:none;---元素不可见,不占据空间,无法触发点击事件,其子孙元素也不可见。
2.元素使用visibility:hidden;---元素不可见,占据空间,可以触发点击事件,其子孙元素可以通过某种方式显示出来。
3.元素使用position:absolute;top:-9999em;---元素不可见,不占据空间,无法点击。
4.元素使用position:relative;top:-9999em;---元素不可见,占据空间,无法点击。
5.元素使用position:absolute;visibility:hidden;---元素不可见,不占据空间,无法点击。
6.元素使用height:0;overflow:hidden;---元素不可见,不占据空间,无法点击。
7.元素使用opacity:0;filter:Alpha(opacity=0);---元素不可见,占据空间,可以点击。
8.元素使用position:absolute;opacity:0;filter:Alpha(opacity=0);---元素不可见,不占据空间,可以点击。
9.元素使用zoom:0.0001或者transform:scale(0)进行缩放。---元素不可见,占据空间,均不可以点击。
10.元素使用position:absolute;辅助9中任意一个。---元素不可见,不占据空间,均不可以点击。
4.数组深浅拷贝、对象深浅拷贝
对于数组和对象的浅度拷贝其实我觉得很简单就是通过for循环将其中的每一个对象都一一复制到新的对象,对于数组的深拷贝和对象的深拷贝曾看过一个帖子大概达到目的的代码,其中心思想就是将把里面的每一个不是基础数据类型的数据进行一一复制,然后到新的对象中。其中判断数据此时数据的类型使用的时object.prototype.tostring.call().slice(8,-1)来判断。
function deepClone(obj) { var result, oClass = isClass(obj); //确定result的类型 if (oClass === "Object") { result = {}; } else if (oClass === "Array") { result = []; } else { return obj; } for (key in obj) { var copy = obj[key]; if (isClass(copy) == "Object") { result[key] = deepClone(copy); //递归调用 } else if (isClass(copy) == "Array") { result[key] = deepClone(copy); } else { result[key] = deepClone[key]; } } return result; } //返回传递给他的任意对象的类 function isClass(o) { if (o === null) return "Null"; if (o === undefined) return "Undefined"; return Object.prototype.toString.call(o).slice(8, -1); } var oPerson = { oName: "rookiebob", oAge: "18", oAddress: { province: "beijing" }, ofavorite: [ "swimming", { reading: "history book" } ], skill: function() { console.log("bob is coding"); } }; //深度克隆一个对象 var oNew = deepClone(oPerson); oNew.ofavorite[1].reading = "picture"; console.log(oNew.ofavorite[1].reading); //picture console.log(oPerson.ofavorite[1].reading); //history book oNew.oAddress.province = "shanghai"; console.log(oNew.oAddress.province); //shanghai console.log(oPerson.oAddress.province); //beijing
5.webpack路由懒加载
对于懒加载,实际上就是指作为一个带有router的项目,对于没有进行访问的部分不进行加载,因为webpack进行最后打包的原则是将所有得代码都打包到最后的文件内部,所以当项目过大会导致访问速度过慢,所以应该进行懒加载。
对于懒加载我再使用vue+webpack中使用过路由的懒加载,一般分为俩个比较重要的部分。
1.首先应该先将其中的代码进行分割。可以使用插件
说一下使用自己带的
require.ensure([], function() {},'one')
此方法能够达到目标最后的代码划分打包。之后还需要在代码中进行一个路由部分的引用。
var vA = r => require.ensure([], () => r(require('../components/v_A.vue')), "chunk11")
之后vA可以直接当做普通的模板文件进行使用
详情写了一个小例子放到了github上面。
6.ES6异步请求数据怎么操作
es6异步请求数据大多可以使用promise。所谓的promise就是一个可以将一个拥有多个回调函数的方法给简便写成一个流式的操作。例子放到github上了---https://github.com/acefeng/demo。
除此之外还可以使用generator等方式。之后再继续加上。
-----------------------------------以上更新自2018-03-07 23:19:52----------------------------------------
三面
1.类似脑筋急转弯
2.类似脑筋急转弯
3.let、const
let和const是es6新鲜出炉的俩种声明数据的方式。以前只有var一种。
let和var的区别主要在于var是一个没有作用域的声明方式。一般来说由于js的内存自动回收机制,导致没有在使用的变量会直接清除。所以如果产生如下的代码的时候需要使用闭包
var a=[]; for(var i=0;i<3;i++){ a[i]=function(){ console.log(i); } } a[0]();//3 a[1]();//3 a[2]();//3
闭包改写。如下
var a=[]; for(var i=0;i<3;i++){ a[i]=function(){ console.log(i); }() } a[0];//0 a[1];//1 a[2];//2
如果使用let声明变量可以达到我们想要的目的 不用再使用闭包了。如下
var a=[]; for(let i=0;i<3;i++){ a[i]=function(){ console.log(i); } } a[0]();//0 a[1]();//1 a[2]();//2
对于const给我的感觉有些类似java中的final修饰。也就是说在代码中const不容许改变原值,并且在声明const变量的时候也需要对其进行初始化,否则也会报错。例如
const a;//声明没有初始化,报错 a=1; const a=1; a=2;//值不可以发生改变,报错
对于js中的var还有一个有意思的东西叫做变量提升。也就是说,js会将其中的变量和函数都进行提升到此时作用域的最顶端。
//此时声明在前,初始化在后 var a; console.log(a); a=1;//undefined //此时声明和初始化都在后 console.log(a); //undefined var a=1; //此时声明和初始化都在前 var a=1; console.log(a);//1 //最能提现变量提升的 a=1; console.log(a);//1 (因为var a=2提升到最上面了) var a=2;
那么let和const就不存在变量提升的说法,使用let声明的变量的时候必须在之前进行声明,否则报错。
console.log(a);//报错 let a=1; console.log(a);//报错 const a=1;
需要强调的一点是let是具有块级作用域的。所以当外部声明和内部声明同名变量的时候注意一下。
var a = 0; function demo () { console.log(a); let a=1; } demo(); //报错。原因是内部被let声明的a占有,所以使用的时候会发生引用错误
4.解构赋值
原题大神问题打错啦。问过大佬才明白这个问题是解构赋值。。。好吧。废话不多说。
对于解构赋值的作用更多的是对es5代码的一个简写。例如
var a=1; var b=2; var c=3; //== var [a,b,c] = [1,2,3]
解构赋值让比较复杂或者几行代码能够实现的代码,可以使用一行就去实现了。
解构赋值更准确地来说我认为应该是模式匹配赋值。。。
var [one,[two,[three]]] = [1,[2,[3]]]; one//1 two//2 three//3 var [,,three] = [1,2,3]; three//3 var [one,...three] = [1,2,3]; one //1 three//[2,3]
当然如果取值数位不够那么他也就不进行解构赋值了。
var [one,two] = [1,2,3] one//1 two//2 var [one,[two],three] = [1,[2,3],4] console.log(one);//1 console.log(two);//2 console.log(three);//4
同样的,对象一样可以进行解构赋值
var { one,two } = {one :'1111',two:'2222'} one//1111 two//2222
但是对象中有一些其他的问题,比如对象赋值不是根据顺序进行赋值,而是对变量名字进行匹配后进行赋值,
var { two,one } = {one :'1111',two:'2222'} one//1111 two//2222 var { on } = {one :'1111',two:'2222'} on//报错
同样的如果名称出错那么赋值都会报错。
名字也可以在赋值过程中进行改变
var { one : two} = {one :'1111'} one//报错 two//1111
除此之外还可以进行默认赋值。
var { one = 1111} = {} one//1111
还有一些对象和数据解构赋值在一起使用的例子。(但是我感觉这种方式超级别扭。)
var {one,two:[t,{three}]} = { one:'1', two:[ '2', { three:'3' } ] }; console.log(one);//1 console.log(t);//2 console.log(three);//3
还有一个需要注意的就是对于已经声明结束的变量要注意使用。外部使用()来扩上,否则浏览器会认为这是一个代码块,而不是解构赋值。
var a; ({a} = {a:1}); console.log(a);//1
5.rest参数
rest参数是es6新加的一个用来替代arguments的参数。例如。
function demo (a,...b) { console.log(a); for(var val of b){ console.log(val) } } demo(1,2,3,4,5);//输出 1,2,3,4,5
注意使用rest的参数的时候,一定是最后一位使用此参数。
除此之外,在es6中还有一个类似rest的写法,扩展运算符(spread)。这种方式是rest的逆运算。
例如
function demo (a,b,c,d,e) { console.log(a); console.log(b); console.log(c); console.log(d); console.log(e); } var arr=[1,2,3,4,5]; demo(...arr);//1,2,3,4,5
当然俩者还可以结合使用
function demo (a,...b) { console.log(a); for(var val of b){ console.log(val) } } var arr=[1,2,3,4,5]; demo(...arr);//输出同上
此时使用了rest参数和spread。
但是spread和rest有不同。spread位置可以不在最后
function demo (...a) { console.log(a); } var arr=[1]; var arr1=[2]; var arr2=[3,4,5]; demo(...arr,arr1,...arr2);//[1, [2], 3, 4, 5]
6.SPA优缺点
SPA即单页面应用。它的优缺点个人也说不上很多。查阅资料大约几种优缺点如下。
优点:
1.前后端进行分离,前端负责view,后端负责model。互相不影响。
2.服务端只需要通过接口提供数据。不需要展示逻辑和页面合成等。
3.现在可以缓存更多的数据,减少服务器的压力。
4.用户体验比较好,速度快,由于很多都是用类似ajax等不用刷新网页的方式加载数据。所以用户体感较好。
5.同一套后端的代码,由于只需要提供数据等,那么就不需要为pc和手机端都写一套代码。
缺点:
1.第一次加载速度过慢。
2.前端复杂度增加,页面复杂度提高。页面逻辑远远复杂过以前的。
3.会出现seo问题。也就是你写的单页面应用很有可能就淹没在众多的同类或者同名站中。
7.MVC、MVVM MVVM为了解决什么问题
mvc(mode(模型)-view(视图)-controller(控制器)),是一种的设计模式,一般来说我们的用户操作等在view层次,之后通过controller进行某些处理,进而进入model中查找更新数据,model中发生改变的时候,view相应的发生改变。view以观察者模式观察model是否发生了改变。具体来说model用来管理数据,view负责显示,c负责业务逻辑管理。
mvvm(前面都一样,vm(viewmodel))
8.箭头函数
箭头函数最最简单的形式就是()=>。但是其中还有一些需要深入讨论的问题。比如。
1.最简单的表示问题,以及返回。
function(){} //== ()=>{} function demo(){} //== var demo = ()=>{} function demo(a){ return a }; //== (可以不再写{}) var demo = (a) => a
2.箭头函数中this指针和普通的函数指针返回不同。
var demo={ method:function(){ console.log(this); }, method1:()=>{ console.log(this) }, mes:function(){ console.log(this) var method2 = ()=>{ console.log(this) } method2(); }, mes1:function(){ console.log(this) var method3 = function(){ console.log(this); } method3(); } } demo.method(); //demo demo.method1(); //window demo.mes(); // demo demo demo.mes1(); //demo window
其实简单来说,不是单纯的箭头函数的this指针不同,而是箭头函数不存在this指针,他的指针是继承而来的。所以不一样。故而它的this指针指向的是他声明部分的this指针。同时,因为它本身不存在this,所以不能够使用call、apply、和bind来改变指针的指向。
9.XSS、CSRF
xss跨站脚本,实际上就是一种html的注入问题,简单来说就是攻击人员以html的某些特殊输入到web后台,进而到数据库的位置,改变某些数据,当别的用户访问的时候就改变了应该显示的某些部分或达到窃取某些数据的目的。
简单的来说,攻击者获取了被攻击者的某些cookie或者权限,将内部的某些敏感数据保存到自己的服务器上,这样就可以达到自己目的,比如恶意增加投票,又或者发信息,等等。
CSRF实际上给我的感觉就是xss的父集,但是xss是csrf实现的路径之一、却不是唯一。
CSRF就是伪造请求,在被攻击者的网站冒充被攻击者进行正常的操作。
我们在大多使用网页登陆某些信息的时候大多其实都是使用的cookie等方式辨识身份。服务端使用session(但是其实session也是基于cookie产生作用的)。也就是说如果我们获取了cookie、再通过某种方式就能达到冒充用户进行用户不知道的某些操作。
也就是说我们需要进行如下几种操作。
1.被攻击者进入网站A,并生成了对应的cookie等信息。
2.在以上条件不消失的时候,访问了具有危险的网站B。
很多时候我们知道了攻击原理也不一定能够完全避免所有的错误。因为对于网络有太多的不确定性。比如上网页不可能只打开一个网页、关闭了浏览器之后,本地的cookie实际上并不一定已经删除了。
当然也不需要过于注重这些事情,因为现在很多东西都有对应的解决办法,比如使用命令秘钥,随机生成字符串,客户端访问的时候服务端生成某种字符串作为秘钥,俩者进行数据传递的时候就对比这种秘钥,然后再确认进行操作。
10.ES5和ES6区别
es5和es6的区别有很多,大致我记下的就有如下。
1.变量的解构赋值
2.字符串、数值、数组、对象、函数等新的方法扩展。
3.let和const
4.set map等数据结构
5.for of
6.promise
7.generator
14.全栈的看法
个人感觉全栈是一个比较有意思的方向吧。个人觉得网上说的全栈低不成高不就应该没有那么夸张,具体的优点还是有很多的,比如在制作某些中小型项目的时候可能几个全栈在一起研讨开发比之前前后端各自去做的时候可能方便很多,毕竟前端不知道后端有什么困难,后端可能也不知道自己的某些代码编写导致前端某些功能写起来麻烦。但是可能对于某些具体的知识肯定也没有那些专职的人员更加专业。也就是说很多时候全栈或许没有google等就没办法活下去了。。。这也是由于知识体系过多导致的。但是我还是蛮喜欢这种职业的,因为我个人喜欢具有一些挑战的,也就是说学习这样的全栈更让我觉得有意思。个人兴趣所致吧。。