Python open() 函数用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出错误
完整语法:open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
常用的参数有:
file: 必需,文件路径(相对或者绝对路径)
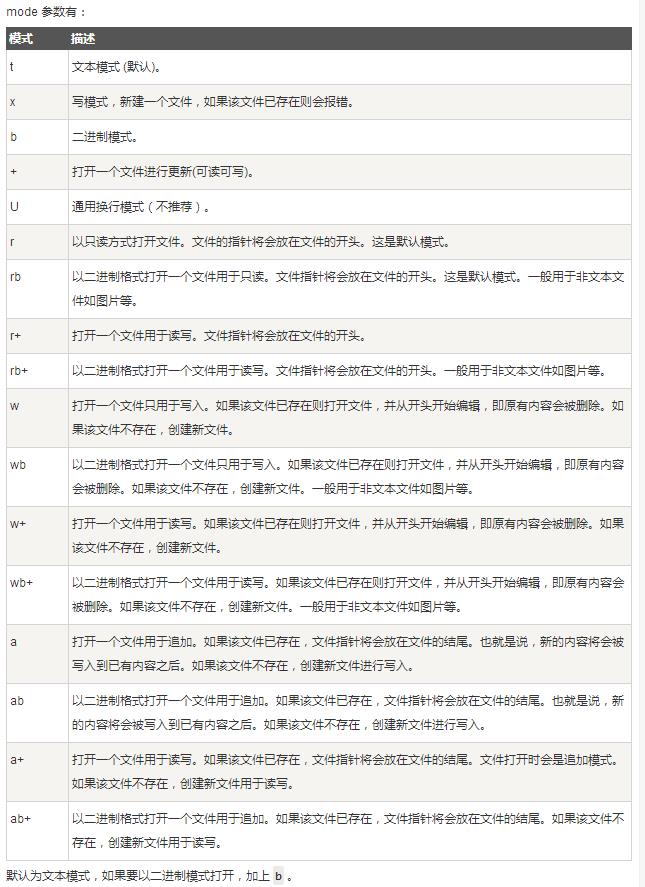
mode: 可选,文件打开模式,参数表见下图(图片来自https://www.runoob.com/python3/python3-func-open.html)
encoding:编码方式,在python3环境下一般设置为utf-8
只读文件:r模式
前提:在工程文件目录下新建一个yesterday.txt文档,并写入以下文字并保存成utf-8格式(不会设置保存格式的清度娘来帮忙)
我爱你中国1,。
我为你自豪2
我爱你中国3
我为你自豪4
我爱你中国5
我为你自豪6
(注意:第一行后面的逗号是半角的,句号是全角的)
设置文件的句柄f,其中参数r可省略
f = open('yesterday.txt', 'r', encoding='utf-8') # 只读不可写(默认)
一次性读取文件内容(文件大的时候不建议使用),返回格式str
print(f.read())
ps:在不关闭文件的前提下,文件读取指针在读取的最后一个字符后面。在上面的语句执行后,指针在文件最后

逐行读取,返回格式str,末尾有 的会多一行空行
f.seek(0) print(f.readline()) print(f.readline()) print(f.readline())

插播:seek() 方法用于移动文件读取指针到指定位置(单位:字节)。
语法 fileObject.seek(offset[, whence])
参数
-
offset -- 开始的偏移量,也就是代表需要移动偏移的字节数,如果是负数表示从倒数第几位开始。
-
whence:可选,默认值为 0。给 offset 定义一个参数,表示要从哪个位置开始偏移;0 代表从文件开头开始算起,1 代表从当前位置开始算起,2 代表从文件末尾算起。
在utf-8中,部分汉字3字节部分4字节,英文/数字1字节,英文标点符号1字节,中文标点3字节, 符号2字节
如果seek()取到的位置是一个汉字中间的,会报错
一次性读取,返回格式列表,会读出 ,可通过strip()去掉
print(f.readlines())

一次性读取n字符(而不是字节),返回类型str
print(f.tell()) f.seek(16) print(f.read(12))

插播:
tell() 方法返回文件的当前位置,即文件指针当前位置(单位:字符)。
语法:fileObject.tell()
从当前位置开始读取12个字符,数字、字母、中英文标点、 均算一个字符
迭代器逐行读取
f.seek(0) for line in f: print(line)

只写文件:w模式或者a模式
w模式:只写不可读;写时不存在则新建,存在则会覆盖原有内容(只要打开这个文件在写入之前,原有内容就被删除了)
a模式:只写不可读;写时不存在则新建,存在则会在末尾追加写入
f =open('my sunshine.txt','w',encoding='utf-8') f.write('《何以笙箫默》') f.write('插曲 ') f.close()

关闭文件后重新打开w模式进行写入,可以发现原来的内容已被删除
f =open('my sunshine.txt','w',encoding='utf-8') f.write('my sunshine ') f.close()

关闭文件后重新打开a模式进行写入,可以发现原有内容保留了,并在末尾追加新内容
f =open('my sunshine.txt','a',encoding='utf-8') f.write('You are my pretty sunshine ' '没你的世界好好坏坏只是无味空白 ' '答应我哪天走失了人海 ' '一定站在最显眼路牌 ' '等着我 一定会来 ') f.write('by 张杰') f.close()

读写操作r+
打开一个文件(上一段程序运行后的结果)可同时进行读、写

f =open('my sunshine.txt','r+',encoding='utf-8')
print(f.readable(),f.writable())#判断是否可读、可写 print(f.readline())#打印出来会多一行空行 print(f.readline()) print(f.readline()) print(f.readline()) print(f.tell())
运行结果表明,读取了前四行后,光标停留在第90个字节处
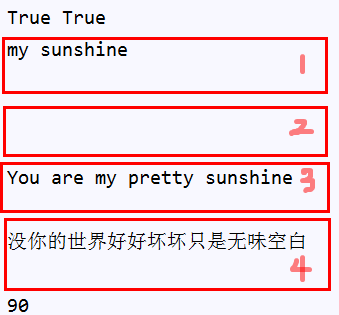
注意:运行写入语句时,会忽略读操作的光标位置,而是在全文末尾会追加内容
f.write(' 翻译:你是我的阳光')#在末尾追加,不覆盖不删除,每次运行都追加,并且光标停留在追加内容的后面
这是运行了两遍的结果:

f.seek(13) f.write('翻译:我的阳光')#使用f.seek()定位光标后,写入的内容会按照位置替换原有内容,并且光标停留在添加的这一句后面 print(f.read())
文档内容:

打印结果:

再次运行单条写入语句
f.write('第二次写入')
会发现第二次写入的位置不在最后而在上一条语句之后,并且也会覆盖原有内容

写读w+
f =open('my sunshine.txt','w+',encoding='utf-8')#若文件存在,打开时已删除原有内容 print(f.readable(),f.writable())#判断是否可读、可写
此时打开这个文件会发现内容全部被清空了,这也是和读写r+ 的唯一区别
运行与r+一样的代码后结果是

追加写读a+
打开文档时不删除原有内容,但是与r+不同的是:光标在原有内容末尾而不是开头

f =open('my sunshine.txt','a+',encoding='utf-8')#打开时不删除原有内容,但是起始光标在末尾 print(f.readable(),f.writable())#判断是否可读、可写 print(f.readline())#因为光标在末尾打印不出来任务东西 print(f.readline()) print(f.readline()) print(f.readline()) print(f.tell()) f.write(' 翻译:你是我的阳光')#在末尾追加,不覆盖不删除,每次运行都追加,并且光标停留在追加内容的后面 f.seek(43)#只对读起作用,写入永远是从后面追加 print(f.readline()) f.write('翻译:我的阳光')#使用f.seek()定位光标后,写入的内容会按照位置替换原有内容,并且光标停留在添加的这一句后面 f.write('第二次写入') f.close()
输出结果:

文档内容:

a+模式中,seek()只对读语句起作用,写语句均是在末尾追加的,并且追加完的光标会在这一句句尾,同时会影响读
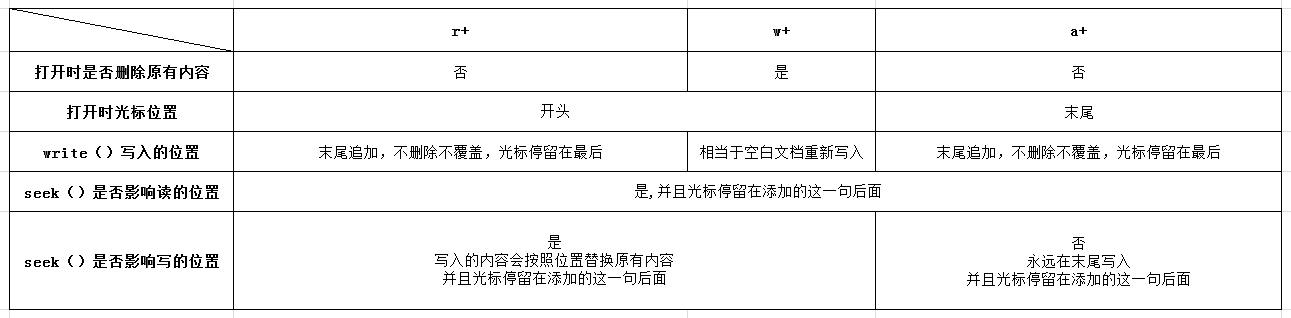
r+、w+、a+ 小结
以上都是文本文件,如果是二进制文件,就都加一个b就行:'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+'
tips
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。
当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。
忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险,当with内的语句全部执行完毕后系统自动关闭文件:
with open('yesterday.txt', 'r') as f: print(f.read())
源代码:
1 #Author:ZM 2 3 4 ''' 5 #只读操作r 6 7 f = open('yesterday.txt', 'r', encoding='utf-8') # 只读(默认),txt文件格式需要设置成utf-8 8 9 print('一次性读取,返回str'.center(50,'-')) 10 print(f.read(),type(f.read()))#type时也会运行一遍f.read() 11 12 print(' ') 13 print('逐行读取,返回str'.center(50,'-')) 14 f.seek(0) 15 print(f.readline()) 16 print(f.readline()) 17 print(f.readline()) 18 19 print(' ') 20 print('一次性读取,返回list'.center(50,'-')) 21 print(f.readlines())#返回列表,会读出 ,可通过strip()去掉 22 23 print(' ') 24 print('一次性读取n字节,返回str'.center(50,'-')) 25 print(f.tell()) 26 #utf-8中,部分汉字3字节部分4字节,英文/数字1字节,英文标点符号1字节,中文标点3字节, 符号2字节 27 #如果seek()取到的位置是一个汉字中间的,会报错 28 f.seek(16) 29 print(f.read(12))#从当前位置开始读取12个字符,数字、字母、中英文标点、 均算一个字符 30 31 print(' ') 32 print('迭代器逐行读取'.center(50,'-')) 33 f.seek(0) 34 for line in f: 35 print(line) 36 37 f.close() 38 ''' 39 40 41 ''' 42 #只写操作w、a 43 f =open('my sunshine.txt','w',encoding='utf-8')#只写不可读;写时不存在则新建,存在则会覆盖原有内容(只要打开这个文件在写入之前,原有内容就被删除了) 44 f.write('《何以笙箫默》') 45 f.write('插曲 ') 46 f.close() 47 48 f =open('my sunshine.txt','w',encoding='utf-8')#只写不可读;写时不存在则新建,存在则会覆盖原有内容(只要打开这个文件在写入之前,原有内容就被删除了) 49 f.write('my sunshine ') 50 51 f.close() 52 53 f =open('my sunshine.txt','a',encoding='utf-8')#只写不可读;写时不存在则新建,存在则会在末尾追加写入 54 f.write('You are my pretty sunshine ' 55 '没你的世界好好坏坏只是无味空白 ' 56 '答应我哪天走失了人海 ' 57 '一定站在最显眼路牌 ' 58 '等着我 一定会来 ') 59 f.write('by 张杰') 60 f.close() 61 ''' 62 63 ''' 64 #读写操作r+ 65 f =open('my sunshine.txt','r+',encoding='utf-8')#打开时不删除原有内容,起始光标在开头 66 67 print(f.readable(),f.writable())#判断是否可读、可写 68 print(f.readline())#打印出来会多一行空行 69 print(f.readline()) 70 print(f.readline()) 71 print(f.readline()) 72 print(f.tell()) 73 74 f.write(' 翻译:你是我的阳光')#在末尾追加,不覆盖不删除,每次运行都追加,并且光标停留在追加内容的后面 75 print(f.read()) 76 77 f.seek(13) 78 f.write('翻译:我的阳光')#使用f.seek()定位光标后,写入的内容会按照位置替换原有内容,并且光标停留在添加的这一句后面 79 f.write('第二次写入') 80 print(f.read()) 81 f.close() 82 83 ''' 84 85 ''' 86 #写读操作w+ 87 88 f =open('my sunshine.txt','w+',encoding='utf-8')#若文件存在,打开时已删除原有内容 89 print(f.readable(),f.writable())#判断是否可读、可写 90 91 f.write('my sunshine ' 92 'You are my pretty sunshine ' 93 '没你的世界好好坏坏只是无味空白 ' 94 '答应我哪天走失了人海 ' 95 '一定站在最显眼路牌 ' 96 '等着我 一定会来 ' 97 'by 张杰') 98 f.seek(0)#将光标从文件末尾移动到开头处 99 print(f.readline())#打印出来会多一行空行 100 print(f.readline()) 101 print(f.readline()) 102 print(f.readline()) 103 print(f.tell()) 104 #print(f.readline()) 105 f.write(' 翻译:你是我的阳光')#在末尾追加,不覆盖不删除,并且光标停留在追加内容的后面;每次运行因为均会清空内容,因此只有这一句话不会反复追加 106 # print(f.read()) 107 f.seek(13) 108 f.write('翻译:我的阳光')#使用f.seek()定位光标后,写入的内容会按照位置替换原有内容,并且光标停留在添加的这一句后面 109 f.write('第二次写入') 110 print(f.read()) 111 112 f.close() 113 ''' 114 115 ''' 116 #写读操作a+ 117 118 f =open('my sunshine.txt','a+',encoding='utf-8')#打开时不删除原有内容,但是起始光标在末尾 119 print(f.readable(),f.writable())#判断是否可读、可写 120 121 print(f.readline())#因为光标在末尾打印不出来任务东西 122 print(f.readline()) 123 print(f.readline()) 124 print(f.readline()) 125 print(f.tell()) 126 127 f.write(' 翻译:你是我的阳光')#在末尾追加,不覆盖不删除,每次运行都追加,并且光标停留在追加内容的后面 128 129 f.seek(43)#只对读起作用,写入永远是从后面追加 130 print(f.readline()) 131 f.write('翻译:我的阳光')#使用f.seek()定位光标后,写入的内容会按照位置替换原有内容,并且光标停留在添加的这一句后面 132 f.write('第二次写入') 133 f.close() 134 135 136 ''' 137 138 139 140 #以上都是文本文件,如果是二进制文件,就都加一个b就行:'rb' 'wb' 'ab' 'rb+' 'wb+' 'ab+' 141 142 143 144 #字符编码 145 ''' 146 要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件: 147 148 f = open('test.txt', 'r', encoding='gbk') 149 150 遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略: 151 152 f = open('test.txt', 'r', encoding='gbk', errors='ignore') 153 ''' 154 f = open('gbk文档的读写.txt',encoding='utf-8') 155 print(f.readline()) 156 157 158 ''' 159 你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险: 160 ''' 161 # with open('yesterday.txt', 'rb') as f: 162 # print(f.read())