源码分析
- Page Layout 分析步骤
二值化
算法: OTSU
调用栈:
main[api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages[api/baseapi.cpp] ->
TessBaseAPI::ProcessPage[api/baseapi.cpp] ->
TessBaseAPI::Recognize[api/baseapi.cpp] ->
TessBaseAPI::FindLines[api/baseapi.cpp] ->
TessBaseAPI::Threshold[api/baseapi.cpp] ->
ImageThresholder::ThresholdToPix[ccmain/thresholder.cpp] ->
ImageThresholder::OtsuThresholdRectToPix [ccmain/thresholder.cpp]
OTSU 是一个全局二值化算法. 如果图片中包含阴影而且阴影不平均,二值化算法效果就会比较差。OCRus利用一个局部的二值化算法,Wolf Jolion, 对包含有阴影的图片也有比较好的二值化结果,以下是一些对比图:(左为原图, 中间为用OTSU算法结果图, 右边为WolfJolion算法结果图):

- 预处理
Remove vertical lines(去除平行线)
This step removes vertical and horizontal lines in the image.
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
Tesseract::SetupPageSegAndDetectOrientation [ccmain/ pagesegmain.cpp]
LineFinder::FindAndRemoveLines [textord/linefind.cpp]
Remove images(去除影像)
This step remove images from the picture.
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
Tesseract::SetupPageSegAndDetectOrientation [ccmain/ pagesegmain.cpp]
ImageFind::FindImages [textord/linefind.cpp]
I never try this function successfully. May be the image needs to satisfy some conditions.
Filter connected component(相关区域)
This step generate all the connected components and filter the noise blobs.
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
Tesseract::SetupPageSegAndDetectOrientation [ccmain/ pagesegmain.cpp] ->
(i) Textord::find_components [textord/tordmain.cpp] ->
{
extract_edges[textord/edgblob.cpp] //extract outlines and assign outlines to blobs
assign_blobs_to_blocks2[textord/edgblob.cpp] //assign normal, noise, rejected blobs to TO_BLOCK_LIST for further filter blobs operations
Textord::filter_blobs[textord/tordmain.cpp] ->
Textord::filter_noise_blobs[textord/tordmain.cpp] //Move small blobs to a separate list
}
(ii) ColumnFinder::SetupAndFilterNoise [textord/colfind.cpp]
This step will generate the intermediate result like this:
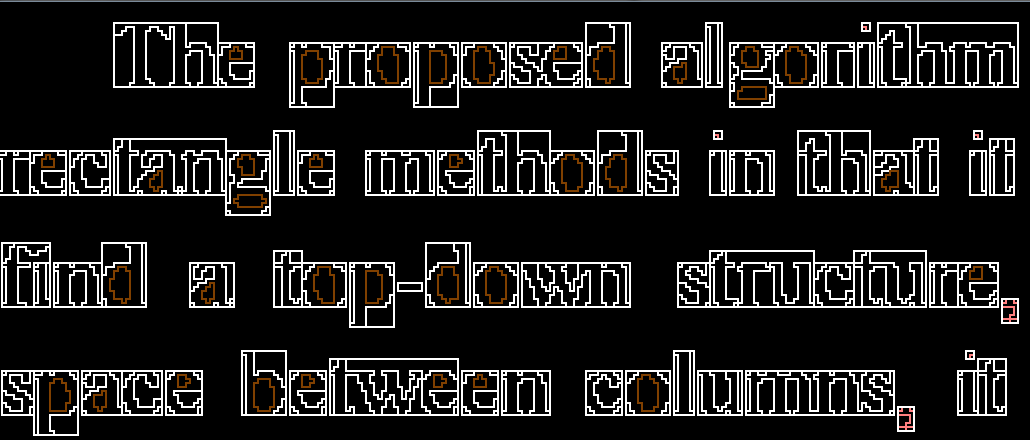
The inner and outer outline of the connected component will be recognized. There will be a box area overlap the connected component. The potential small noise blobs will be marked as pink outlines, such as punctuation and dot in character “i”.
The large blobs will be marked as dark green color:

Finding candidate tab-stop components
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
ColumnFinder::FindBlocks [textord/ colfind.cpp] ->
TabFind::FindInitialTabVectors[textord/tabfind.cpp] ->
TabFind::FindTabBoxes [textord/tabfind.cpp]
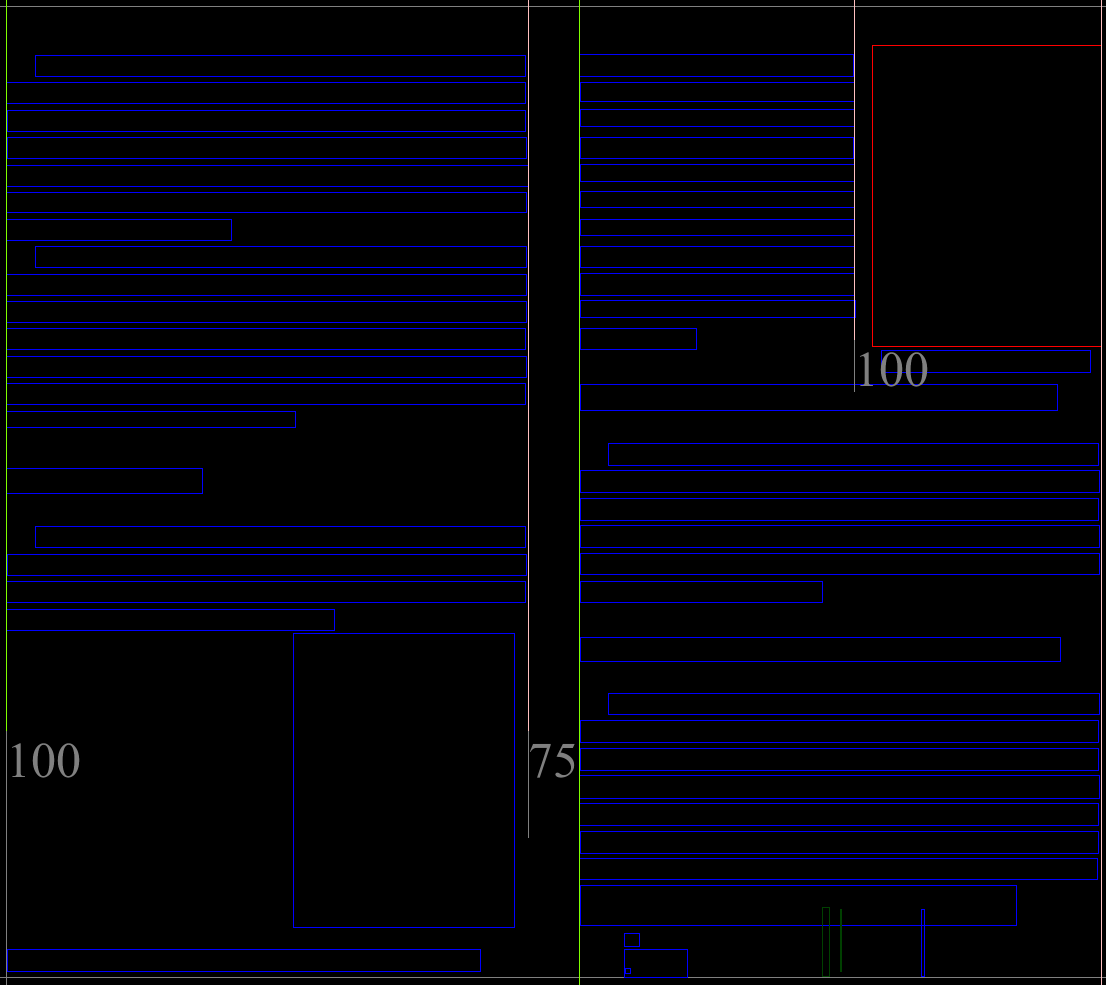
This step finds the initial candidate tab-stop CCs by a radial search starting at every filtered CC from preprocessing. The result will be like this:

Finding the column layout(找出行信息)
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
ColumnFinder::FindBlocks [textord/ colfind.cpp] ->
ColumnFinder::FindBlocks (begin at line 369) [textord/ colfind.cpp]
This step finds the column layout of the page:
Finding the regions(找出字符区域)
调用栈
main [api/tesseractmain.cpp] ->
TessBaseAPI::ProcessPages [api/baseapi.cpp] ->
TessBaseAPI::ProcessPage [api/baseapi.cpp] ->
TessBaseAPI::Recognize [api/baseapi.cpp] ->
TessBaseAPI::FindLines [api/baseapi.cpp] ->
Tesseract::SegmentPage [ccmain/pagesegmain.cpp] ->
Tesseract::AutoPageSeg [ccmain/ pagesegmain.cpp] ->
ColumnFinder::FindBlocks [textord/ colfind.cpp]
This step recognizes the different type of blocks:

接下来的工作
找tab-stops及之后处理步骤的算法还不甚清楚,需要继续了解
识别字符部分还没开始看,这部分应该有涉及机器学习的多种算法,有时间需要继续学习
---------------------
作者:kaelsass
来源:CSDN
原文:https://blog.csdn.net/kaelsass/article/details/46874627
版权声明:本文为博主原创文章,转载请附上博文链接!