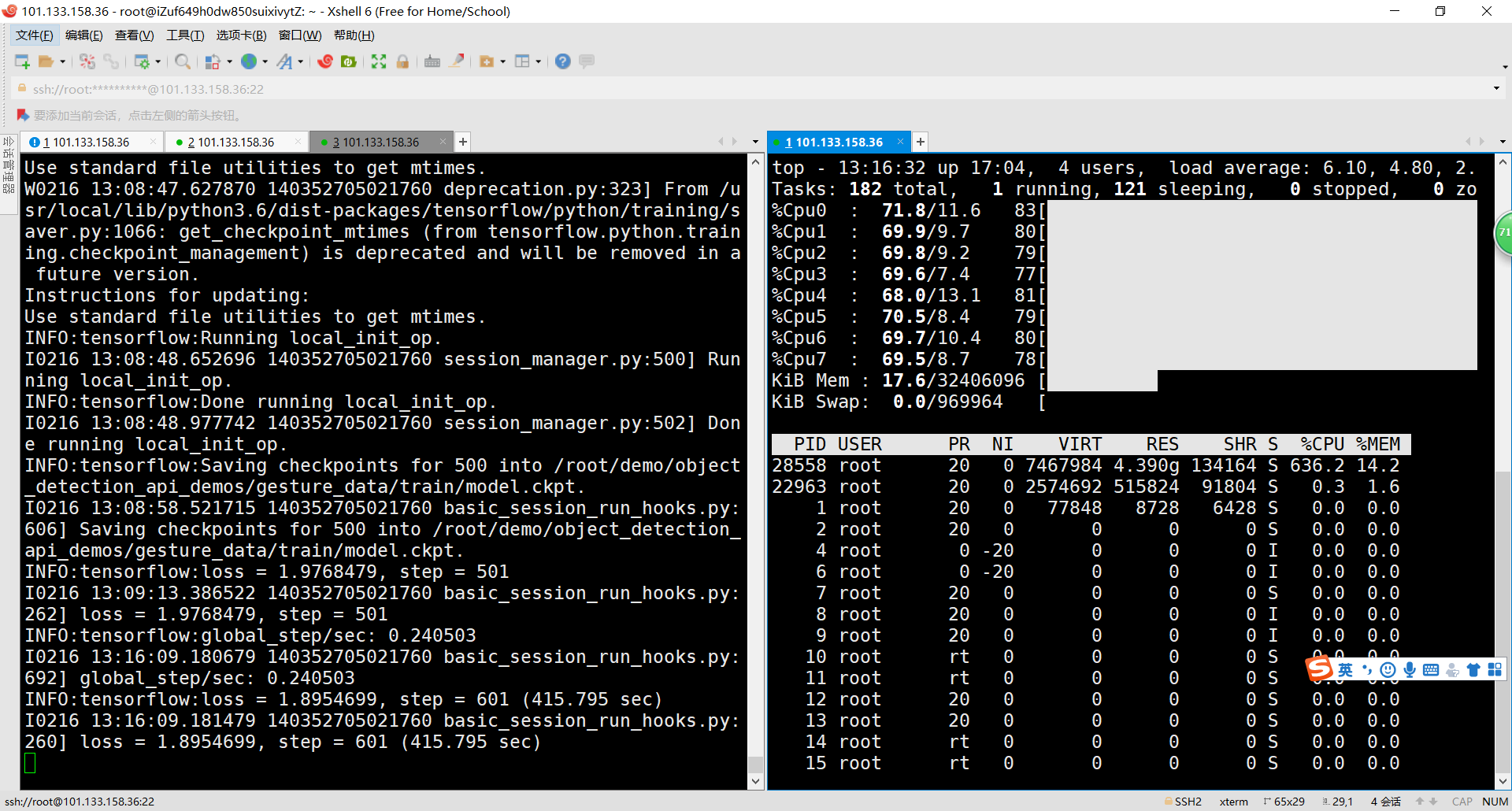
步骤:
- 安装tensorflow object detection api
- 准备数据
- 模型准备
- 图片准备
- 图片数据打标
- 转换为tfrecord格式
- 进行迁移训练
- 导出模型
- 使用模型
安装tensorflow object detection api
git clone https://github.com/tensorflow/models.git
然后根据这个https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md 进行安装
提示:用ubuntu进行安装,用windows环境会出很多问题,通过ubuntu安装会加快速度很多很多。
准备数据
思路是通过opencv拍摄照片,保存到某个具体目录,如下:
import cv2
cap = cv2.VideoCapture(0)
idx = 0
while True:
ret, frame = cap.read()
if ret is True:
cv2.imshow('frame', frame)
if idx % 5 == 0:
cv2.imwrite('/gesture_data/VOC2012/JPEGImages/'+str(idx)+'.jpg', frame)
cv2.waitKey(50)
idx += 1
else:
break
cv2.destroyAllWindows()
保存后是,这种图片(jpg)

模型准备
图片数据打标,labelImg.exe 要自己找下下载,这个步骤由于打标数据比较多,因此比较耗时

转换为tfrecord格式
cd C:Research-Code ensorflowmodels esearch
python3 object_detection/dataset_tools/create_pascal_tf_record.py
--label_map_path=C:/Users/McKay/PycharmProjects/test8/object_detection_api_demos/gesture_data/gesture_label_map.pbtxt
--data_dir=C:/Users/McKay/PycharmProjects/test8/object_detection_api_demos/gesture_data
--year=VOC2012
--set=train
--output_path=C:/Users/McKay/PycharmProjects/test8/object_detection_api_demos/gesture_data/pascal_train_handone.record
--category=hand
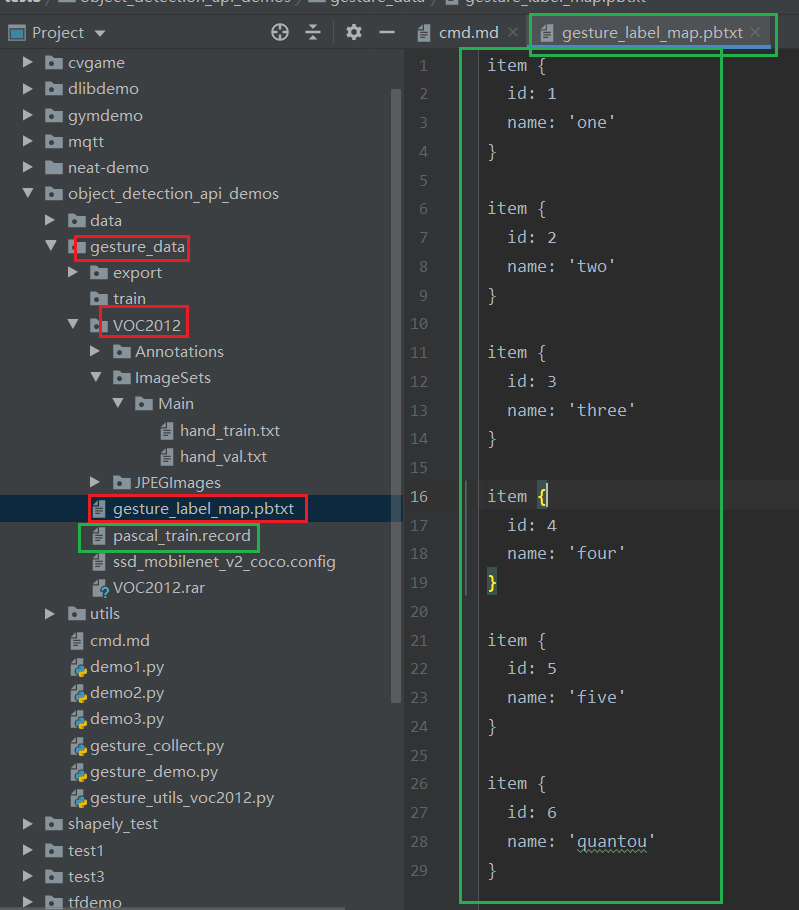
需要修改create_pascal_tf_record.py
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Convert raw PASCAL dataset to TFRecord for object_detection.
Example usage:
python object_detection/dataset_tools/create_pascal_tf_record.py
--data_dir=/home/user/VOCdevkit
--year=VOC2012
--output_path=/home/user/pascal.record
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import hashlib
import io
import logging
import os
from lxml import etree
import PIL.Image
import tensorflow as tf
from object_detection.utils import dataset_util
from object_detection.utils import label_map_util
flags = tf.app.flags
flags.DEFINE_string('data_dir', '', 'Root directory to raw PASCAL VOC dataset.')
flags.DEFINE_string('set', 'train', 'Convert training set, validation set or '
'merged set.')
flags.DEFINE_string('annotations_dir', 'Annotations',
'(Relative) path to annotations directory.')
flags.DEFINE_string('year', 'VOC2007', 'Desired challenge year.')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
flags.DEFINE_string('label_map_path', 'data/pascal_label_map.pbtxt',
'Path to label map proto')
flags.DEFINE_boolean('ignore_difficult_instances', False, 'Whether to ignore '
'difficult instances')
flags.DEFINE_string('category', '', 'category')
FLAGS = flags.FLAGS
SETS = ['train', 'val', 'trainval', 'test']
YEARS = ['VOC2007', 'VOC2012', 'merged']
def dict_to_tf_example(data,
dataset_directory,
label_map_dict,
ignore_difficult_instances=False,
image_subdirectory='JPEGImages'):
"""Convert XML derived dict to tf.Example proto.
Notice that this function normalizes the bounding box coordinates provided
by the raw data.
Args:
data: dict holding PASCAL XML fields for a single image (obtained by
running dataset_util.recursive_parse_xml_to_dict)
dataset_directory: Path to root directory holding PASCAL dataset
label_map_dict: A map from string label names to integers ids.
ignore_difficult_instances: Whether to skip difficult instances in the
dataset (default: False).
image_subdirectory: String specifying subdirectory within the
PASCAL dataset directory holding the actual image data.
Returns:
example: The converted tf.Example.
Raises:
ValueError: if the image pointed to by data['filename'] is not a valid JPEG
"""
img_path = os.path.join(data['folder'], image_subdirectory, data['filename'])
full_path = os.path.join(dataset_directory, img_path)
with tf.gfile.GFile(full_path, 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = PIL.Image.open(encoded_jpg_io)
if image.format != 'JPEG':
raise ValueError('Image format not JPEG')
key = hashlib.sha256(encoded_jpg).hexdigest()
width = int(data['size']['width'])
height = int(data['size']['height'])
xmin = []
ymin = []
xmax = []
ymax = []
classes = []
classes_text = []
truncated = []
poses = []
difficult_obj = []
if 'object' in data:
for obj in data['object']:
difficult = bool(int(obj['difficult']))
if ignore_difficult_instances and difficult:
continue
difficult_obj.append(int(difficult))
xmin.append(float(obj['bndbox']['xmin']) / width)
ymin.append(float(obj['bndbox']['ymin']) / height)
xmax.append(float(obj['bndbox']['xmax']) / width)
ymax.append(float(obj['bndbox']['ymax']) / height)
classes_text.append(obj['name'].encode('utf8'))
classes.append(label_map_dict[obj['name']])
truncated.append(int(obj['truncated']))
poses.append(obj['pose'].encode('utf8'))
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/source_id': dataset_util.bytes_feature(
data['filename'].encode('utf8')),
'image/key/sha256': dataset_util.bytes_feature(key.encode('utf8')),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature('jpeg'.encode('utf8')),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmin),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmax),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymin),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymax),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
'image/object/difficult': dataset_util.int64_list_feature(difficult_obj),
'image/object/truncated': dataset_util.int64_list_feature(truncated),
'image/object/view': dataset_util.bytes_list_feature(poses),
}))
return example
def main(_):
if FLAGS.set not in SETS:
raise ValueError('set must be in : {}'.format(SETS))
if FLAGS.year not in YEARS:
raise ValueError('year must be in : {}'.format(YEARS))
data_dir = FLAGS.data_dir
years = ['VOC2007', 'VOC2012']
if FLAGS.year != 'merged':
years = [FLAGS.year]
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
label_map_dict = label_map_util.get_label_map_dict(FLAGS.label_map_path)
for year in years:
logging.info('Reading from PASCAL %s dataset.', year)
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
FLAGS.category + '_' + FLAGS.set + '.txt')
annotations_dir = os.path.join(data_dir, year, FLAGS.annotations_dir)
examples_list = dataset_util.read_examples_list(examples_path)
for idx, example in enumerate(examples_list):
if idx % 100 == 0:
logging.info('On image %d of %d', idx, len(examples_list))
path = os.path.join(annotations_dir, example + '.xml')
with tf.gfile.GFile(path, 'r') as fid:
xml_str = fid.read()
xml = etree.fromstring(xml_str)
data = dataset_util.recursive_parse_xml_to_dict(xml)['annotation']
tf_example = dict_to_tf_example(data, FLAGS.data_dir, label_map_dict,
FLAGS.ignore_difficult_instances)
writer.write(tf_example.SerializeToString())
writer.close()
if __name__ == '__main__':
tf.app.run()
gesture_label_map.pbtxt是定义了我们的类别:
item { id: 1 name: 'one' } item { id: 2 name: 'two' } item { id: 3 name: 'three' } item { id: 4 name: 'four' } item { id: 5 name: 'five' } item { id: 6 name: 'quantou' }
进行迁移训练
cd /root/models/research python3 object_detection/model_main.py
--pipeline_config_path=/root/demo/object_detection_api_demos/gesture_data/ssd_mobilenet_v2_coco.config
--model_dir=/root/demo/object_detection_api_demos/gesture_data/train
--num_train_steps=1000
--num_eval_steps=15
--alsologtostderr
ssd_mobilenet_v2_coco.config
# SSD with Mobilenet v2 configuration for MSCOCO Dataset.
# Users should configure the fine_tune_checkpoint field in the train config as
# well as the label_map_path and input_path fields in the train_input_reader and
# eval_input_reader. Search for "PATH_TO_BE_CONFIGURED" to find the fields that
# should be configured.
model {
ssd {
num_classes: 6
box_coder {
faster_rcnn_box_coder {
y_scale: 10.0
x_scale: 10.0
height_scale: 5.0
width_scale: 5.0
}
}
matcher {
argmax_matcher {
matched_threshold: 0.5
unmatched_threshold: 0.5
ignore_thresholds: false
negatives_lower_than_unmatched: true
force_match_for_each_row: true
}
}
similarity_calculator {
iou_similarity {
}
}
anchor_generator {
ssd_anchor_generator {
num_layers: 6
min_scale: 0.2
max_scale: 0.95
aspect_ratios: 1.0
aspect_ratios: 2.0
aspect_ratios: 0.5
aspect_ratios: 3.0
aspect_ratios: 0.3333
}
}
image_resizer {
fixed_shape_resizer {
height: 300
300
}
}
box_predictor {
convolutional_box_predictor {
min_depth: 0
max_depth: 0
num_layers_before_predictor: 0
use_dropout: false
dropout_keep_probability: 0.8
kernel_size: 1
box_code_size: 4
apply_sigmoid_to_scores: false
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
}
feature_extractor {
type: 'ssd_mobilenet_v2'
min_depth: 16
depth_multiplier: 1.0
conv_hyperparams {
activation: RELU_6,
regularizer {
l2_regularizer {
weight: 0.00004
}
}
initializer {
truncated_normal_initializer {
stddev: 0.03
mean: 0.0
}
}
batch_norm {
train: true,
scale: true,
center: true,
decay: 0.9997,
epsilon: 0.001,
}
}
}
loss {
classification_loss {
weighted_sigmoid {
}
}
localization_loss {
weighted_smooth_l1 {
}
}
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image: 3
}
classification_weight: 1.0
localization_weight: 1.0
}
normalize_loss_by_num_matches: true
post_processing {
batch_non_max_suppression {
score_threshold: 1e-8
iou_threshold: 0.6
max_detections_per_class: 100
max_total_detections: 100
}
score_converter: SIGMOID
}
}
}
train_config: {
batch_size: 24
optimizer {
rms_prop_optimizer: {
learning_rate: {
exponential_decay_learning_rate {
initial_learning_rate: 0.004
decay_steps: 800720
decay_factor: 0.95
}
}
momentum_optimizer_value: 0.9
decay: 0.9
epsilon: 1.0
}
}
fine_tune_checkpoint: "/root/demo/object_detection_api_demos/data/ssd_mobilenet_v2_coco_2018_03_29/ssd_mobilenet_v2_coco_2018_03_29/model.ckpt"
fine_tune_checkpoint_type: "detection"
# Note: The below line limits the training process to 200K steps, which we
# empirically found to be sufficient enough to train the pets dataset. This
# effectively bypasses the learning rate schedule (the learning rate will
# never decay). Remove the below line to train indefinitely.
num_steps: 200000
data_augmentation_options {
random_horizontal_flip {
}
}
data_augmentation_options {
ssd_random_crop {
}
}
}
train_input_reader: {
tf_record_input_reader {
input_path: "/root/demo/object_detection_api_demos/gesture_data/pascal_train.record"
}
label_map_path: "/root/demo/object_detection_api_demos/gesture_data/gesture_label_map.pbtxt"
}
eval_config: {
num_examples: 8000
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 10
}
eval_input_reader: {
tf_record_input_reader {
input_path: "/root/demo/object_detection_api_demos/gesture_data/pascal_train.record"
}
label_map_path: "/root/demo/object_detection_api_demos/gesture_data/gesture_label_map.pbtxt"
shuffle: false
num_readers: 1
}
导出模型
cd /root/models/research python3 object_detection/export_inference_graph.py
--input_type=image_tensor
--pipeline_config_path=/root/demo/object_detection_api_demos/gesture_data/ssd_mobilenet_v2_coco.config
--trained_checkpoint_prefix=/root/demo/object_detection_api_demos/gesture_data/train/model.ckpt-400
--output_directory=/root/demo/object_detection_api_demos/gesture_data/export
输出训练后的模型export目录:

使用模型,其实就是上面的 frozen_inference_graph.pb 既为训练后的模型
import pathlib import cv2 as cv import numpy as np import os import six.moves.urllib as urllib import sys import tarfile import tensorflow as tf import zipfile from collections import defaultdict from io import StringIO from matplotlib import pyplot as plt from PIL import Image from IPython.display import display from object_detection.utils import ops as utils_ops from object_detection.utils import label_map_util from object_detection.utils import visualization_utils as vis_util # patch tf1 into `utils.ops` utils_ops.tf = tf.compat.v1 # Patch the location of gfile tf.gfile = tf.io.gfile # List of the strings that is used to add correct label for each box. PATH_TO_LABELS = '/root/demo/object_detection_api_demos/gesture_data/gesture_label_map.pbtxt' category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True) PATH_TO_FROZEN_GRAPH = '/root/demo/object_detection_api_demos/gesture_data/export/frozen_inference_graph.pb' detection_graph = tf.Graph() with detection_graph.as_default(): od_graph_def = tf.GraphDef() with tf.gfile.GFile(PATH_TO_FROZEN_GRAPH, 'rb') as fid: serialized_graph = fid.read() od_graph_def.ParseFromString(serialized_graph) tf.import_graph_def(od_graph_def, name='') def run_inference_for_single_image(image, graph): with graph.as_default(): with tf.Session() as sess: # Get handles to input and output tensors ops = tf.get_default_graph().get_operations() all_tensor_names = {output.name for op in ops for output in op.outputs} tensor_dict = {} for key in [ 'num_detections', 'detection_boxes', 'detection_scores', 'detection_classes', 'detection_masks' ]: tensor_name = key + ':0' if tensor_name in all_tensor_names: tensor_dict[key] = tf.get_default_graph().get_tensor_by_name( tensor_name) if 'detection_masks' in tensor_dict: # The following processing is only for single image detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0]) detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0]) # Reframe is required to translate mask from box coordinates to image coordinates and fit the image size. real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32) detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1]) detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1]) detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks( detection_masks, detection_boxes, image.shape[0], image.shape[1]) detection_masks_reframed = tf.cast( tf.greater(detection_masks_reframed, 0.5), tf.uint8) # Follow the convention by adding back the batch dimension tensor_dict['detection_masks'] = tf.expand_dims( detection_masks_reframed, 0) image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0') # Run inference output_dict = sess.run(tensor_dict, feed_dict={image_tensor: np.expand_dims(image, 0)}) # all outputs are float32 numpy arrays, so convert types as appropriate output_dict['num_detections'] = int(output_dict['num_detections'][0]) output_dict['detection_classes'] = output_dict[ 'detection_classes'][0].astype(np.uint8) output_dict['detection_boxes'] = output_dict['detection_boxes'][0] output_dict['detection_scores'] = output_dict['detection_scores'][0] if 'detection_masks' in output_dict: output_dict['detection_masks'] = output_dict['detection_masks'][0] return output_dict image = cv.imread("data/test_images/hand/two.jpg") output_dict = run_inference_for_single_image(image, detection_graph) vis_util.visualize_boxes_and_labels_on_image_array( image, output_dict['detection_boxes'], output_dict['detection_classes'], output_dict['detection_scores'], category_index, instance_masks=output_dict.get('detection_masks'), min_score_thresh=0.5, use_normalized_coordinates=True, line_thickness=4 ) cv.imwrite('data/test_images/hand/two-result.jpg', image) cv.destroyAllWindows()

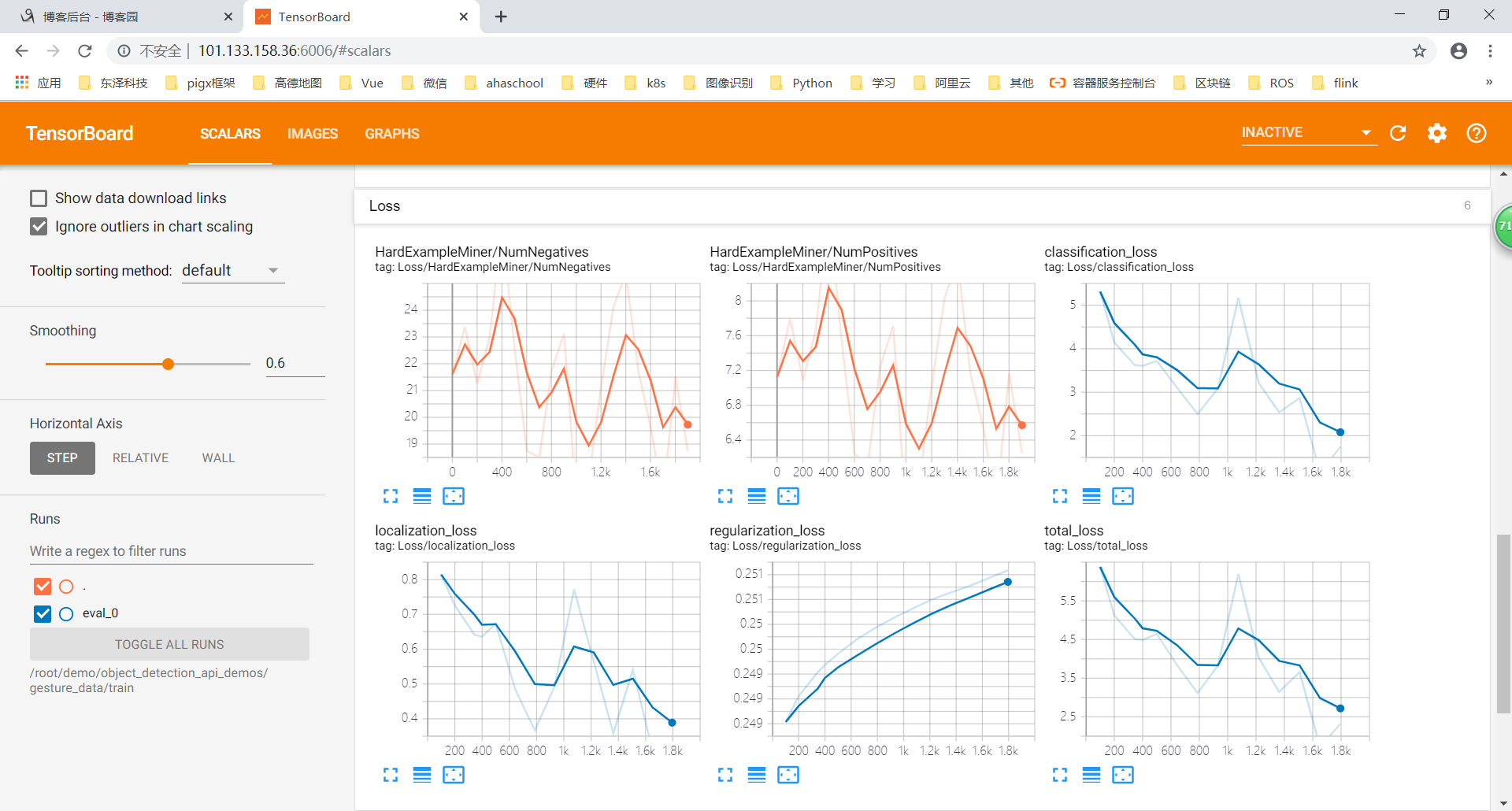

训练中的CPU: