前言:
最近一直忙着公司项目的事,战友们的留言也没空回复,博客也有段时间没有更新了,年底了就是一个的忙啊~~~(ps:同感的也给个赞吧)
现在前端的就是一直地更新一直有新的东西出来,什么ES2015,ES2016,到现在已经ES2018了,除了ES语法的更新迭代,JavaScript的强大又
延伸到了后台,node.js。只能说学无止境啊,共勉吧~~~
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。 一句话总结了,node.js就是一个运行环境,个人理解就是释放了浏览器环境对JavaScript的束缚,让JavaScript可以做更多的事情。
node.js第一篇:HTTP。
HTTP
超文本传输协议(HTTP)是用于传输褚如HTML的超媒体文档的[应用层协议]。它被设计用于Web浏览器和Web服务器之间的通信,但它也可以用于其他目的。
HTTP遵循经典的[客户端-服务端模型],客户端打开一个连接以发送请求,然后等待它收到服务器端响应。
HTTP是[无状态协议],意味着服务器不会在两个请求直接保留任何数据(状态)。
HTTP概述
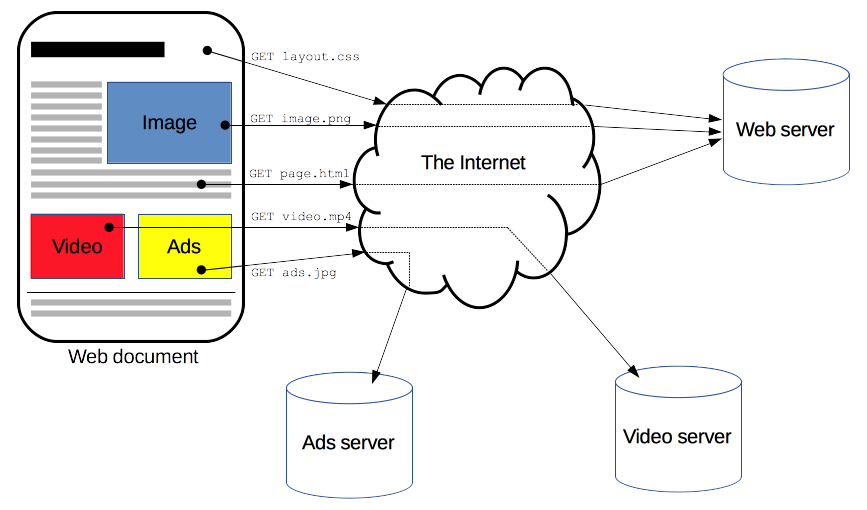
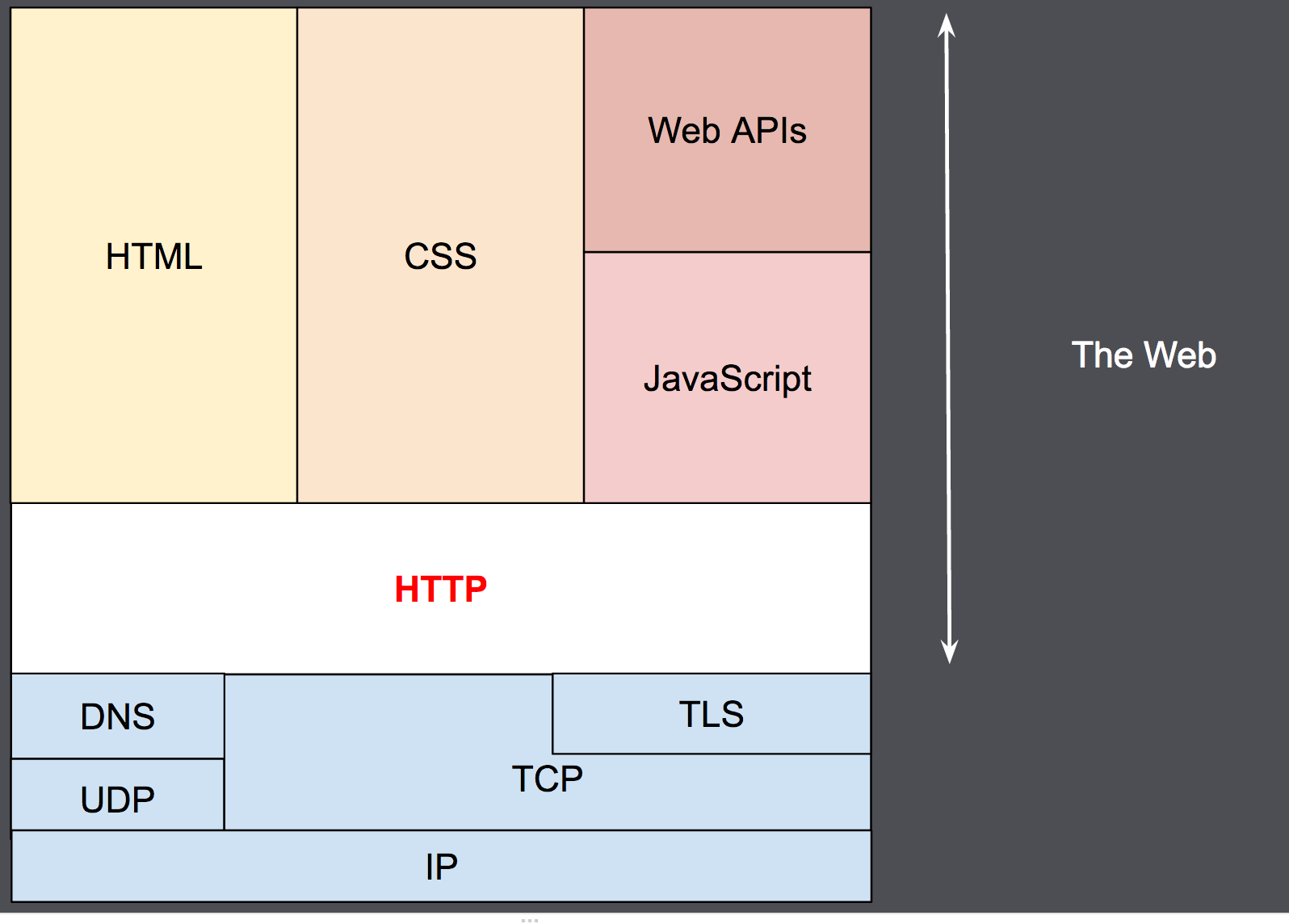
HTTP是应用层的协议,虽然理论上它可以通过任何可靠的传输协议来发送,但是它还是
通过[TCP]或者是[TLS]-加密的TCP连接来发送。
它不仅被用来传输超文本文档,还用来传输图片、视频或者向服务器发送如HTML表单这样的信息。HTTP还可以根据网页需求,仅获取部分Web文档内容更新网页。
HTTP组件系统
HTTP是一个client-server协议:请求通过一个实体(即用户代理)被发出。大多数情况下,这个用户代理都是指浏览器,也可能是一个爬区网页生成维护搜索引擎索引的机器爬虫等。
每一个发送到服务器的请求,都会被服务器处理并返回一个消息(response)。在client和server之间,还有许多的被称为proxies的实体,他们的作用和表现各不相同,比如有些是网关,caches等。

实际上,在一个浏览器和处理请求的服务器之间,还有计算机、路由器、调制解调器等许多实体。由于Web的层次设计,那些在网络层和传输层的细节都被隐藏起来了。
一、客户端:user-agent
user-agent就是任何能够为用户发起行为的工具。但实际上,这个角色通常都是由浏览器来扮演。
要渲染出一个网页,浏览器首先要发送第一个请求来获取页面的HTML文档,再解析文档中的资源信息发送其他请求,获取可执行脚本或css样式来进行页面布局渲染,以及一些其它网页资源(如图片和视频等)。然后,浏览器将这些资源整合在一起,展示出一个完整的文档,也就是网页。
一个网页就是一个超文本文档,有一部分显示的文本可能是链接,启动它(通常是鼠标的点击)就可以获取一个新的网页。网页使得用户可以控制客户端进行网上冲浪。由浏览器来负责发送HTTP请求,呈现HTTP返回消息,让用户能清晰地看到返回的网页内容。
二、Web服务端
在上述通信过程的另一端,是由Web Server来服务并提供客户端所请求的文档。Server只是虚拟意义上的:
它可以是许多共同分担负载(负载均衡)一组服务器组成的计算机集群,也可以是一种复杂的软件,通过向其他计算机发起请求来获取部分或全部资源。
Server不再只是一枚单独的机器,它可以是在同一个机器上装载的众多服务之一。在HTTP/1.1[Host]头部中,它们甚至可以共享同一个IP地址。
三、代理(Proxies)
在浏览器和服务器之间,有许多计算机和其他设备转发了HTTP消息。由于Web栈层次结构的原因,它们大多都出现在传输层、网络层和物理层上,对于HTTP应用层而言就是透明的,虽然它们可能会对应用层性能有重要影响。还有一部分也表现在应用层上,就是代理(Proxies)。代理既可以表现得透明,又可以
不透明(得看请求是否通过它们),代理主要有一下作用:
1.缓存(可以是公开的也可以是私有的,像浏览器的缓存)
2.过滤(像反病毒扫描,家长控制...)
3.负载均衡(让多个服务器服务不同的请求)
4.认证(对不同资源进行权限管理)
5.登陆(允许存储历史信息)
HTTP基本性质
1.HTTP是简单的
2.HTTP是可扩展的
在HTTP/1.0中出现的[HTTP headers]让协议扩展变得非常容易。只要服务端和客户端就新headers达成语义一致,新功能就可以加入进来。
3.HTTP是无状态,有会话的
HTTP是无状态的:在同一个连接中,两个执行成功的请求直接是没有关系的。使用HTTP的头部扩展,HTTP Cookies就可以创建有状态的会话。把Cookies添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
4.HTTP 和连接
一个连接是由传输层来控制的,这基本不属于HTTP的范围。HTTP并不需要其下传输层的协议是面向连接的,只需要它是可靠的,就是说不能丢失消息。
HTTP/1.0曾为每一个请求/响应都打开一个TCP连接,导致了2个缺点:打开一个TCP连接需要多次消息传递,速度很慢。但当多个消息周期性发送时,这样就变得更加高效。
为了减少连接开销,HTTP/1.1引入了流水线和持久连接的概念:下层的TCP连接可以通过[Connection]头部来部分控制。HTTP/2则发展得更远,通过一个连接多个消息的方式来让这个链接始终保持为暖连接。
HTTP 流
当客户端想要和服务端进行信息交互时(服务端是指最终服务器,或者是一个中间代理),过程表现为:
1. 打开一个TCP连接(或重用之前的一个):TCP连接用来发送一条或多条请求,当然也用来接受回应消息。
客户端可能重用一个已经存在的连接,或者也可能重开几个新的TCP连接连向服务端。
2. 发送一个HTTP报文(HTTP请求):HTTP报文(在HTTP/2之前)是语义可读的。在HTTP/2中,这些简单的消息被封装在
了帧中,这使得报文不能被直接读出来,但是报告格式仍是相同的。
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行、请求头部、空行和请求数据四个
部分组成。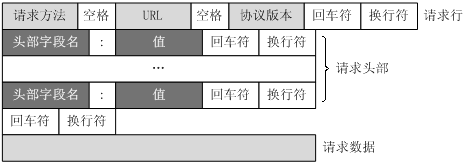
3. 读取服务端返回的报文信息(HTTP响应):状态行、消息报头、空行和响应正文。
content-type:内容类型,一般是指网页中存在的Content-type,用于定义网络问卷的类型和网页的编码,
决定浏览器将以什么形式、什么编码读取这个文件。
4. 关闭连接或者为后续请求重用连接。
当HTTP流水线启动时,后续请求都可以不用等待第一个请求的成功回应就被发送。
起个Demo
通过上述的描述,我猜大家也已经了解了HTTP是干什么的了,说白了就是约定好的一个协议以进行web端和服务器端的正常交互。
以下会通过起一个HTTP服务进行简单的增删改查操作。
启动服务:
通过require HTTP 模块并创建一个服务器实例createServer,并监听端口,则在浏览器端url输入localhost:8200即可
参考api:http://nodejs.cn/api/http.html
const http=require("http");
const server=http.createServer();
server.on("request",(req,res)=>{
res.end("server had created");
});
server.listen(8200);

监听请求和请求方法实现简单的增删改查:
启动服务后,创建个全局变量users数组存储用户,并根据request.method请求方法对请求数据进行增删改查的处理。
参考api:http://nodejs.cn/api/url.html
const http=require("http");
const url=require("url");//用于 URL 处理与解析
const server=http.createServer();
server.listen(8200);
let users=[];
server.on("request",(req,res)=>{
const parseUrl=url.parse(req.url);
if(parseUrl.path.indexOf('/user')===-1){
res.statusCode=403;
res.end(`${res.statusCode} not allowed` );
return;
}
switch(req.method){
case 'GET':
if(parseUrl.path.indexOf('/user/')>-1){
let userName=parseUrl.path.substring(6,parseUrl.path.length);
let user=users.find(u=>u.name===userName);
res.statusCode=200;
res.end(JSON.stringify(users));
}
break;
case 'POST':
req.on("data",(buffer)=>{
const userStr=buffer.toString();
let contentType=req.headers['content-type'];
if(contentType==='application/json'){
let user=JSON.parse(userStr);
users.push(user);
}
res.statusCode=201;
});
req.on("end",()=>{
res.statusCode=200;
res.end(JSON.stringify(users));
});
break;
case 'PATCH':
req.on("data",(buffer)=>{
let userStr=buffer.toString();
let contentType=req.headers['content-type'];
if(contentType==='application/json'){
let update=JSON.parse(userStr);
let user=users.find(u=>u.name===update.name);
console.log(user);
user.address=update.address;
}
res.statusCode=201;
});
req.on("end",()=>{
res.statusCode=200;
res.end(JSON.stringify(users));
});
break;
case 'DELETE':
req.on("data",(buffer)=>{
let contentType=req.headers['content-type'];
if(contentType==='application/json'){
let index=users.find(u=>u.name===buffer.name);
users.splice(index,1);
}
res.statusCode=201;
});
req.on("end",()=>{
res.statusCode=200;
res.end(JSON.stringify(users));
});
break;
}
});
为了方便模拟发送请求,我们可以下载个postman进行http请求的发送。这样我们就完成了简单的基于HTTP请求的对数据的操作了。
书籍推荐
《图解HTTP》、《HTTP权威指南》
参考
MDN:https://developer.mozilla.org/zh-CN/docs/Web/HTTP
菜鸟教程:http://www.runoob.com/http/http-messages.html
Node.js系列第一篇,可能语言组织得没有这么好,觉得有哪些需要改进的希望多多提意见,Node.js系列就是开始记录我入坑node.js的路程的,感兴趣的战友可以持续关注喔。