实验目的
1.准确理解MapReduce二次排序的设计原理
2.了解二次排序的适用场景
3.熟练掌握MapReduce二次排序程序代码编写
实验原理
在Map阶段,使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。本实验中使用的是TextInputFormat,他提供的RecordReder会将文本的字节偏移量作为key,这一行的文本作为value。这就是自定义Map的输入是<LongWritable, Text>的原因。然后调用自定义Map的map方法,将一个个<LongWritable, Text>键值对输入给Map的map方法。注意输出应该符合自定义Map中定义的输出<IntPair, IntWritable>。最终是生成一个List<IntPair, IntWritable>。在map阶段的最后,会先调用job.setPartitionerClass对这个List进行分区,每个分区映射到一个reducer。每个分区内又调用job.setSortComparatorClass设置的key比较函数类排序。可以看到,这本身就是一个二次排序。 如果没有通过job.setSortComparatorClass设置key比较函数类,则可以使用key实现的compareTo方法进行排序。 在本实验中,就使用了IntPair实现的compareTo方法。
在Reduce阶段,reducer接收到所有映射到这个reducer的map输出后,也是会调用job.setSortComparatorClass设置的key比较函数类对所有数据对排序。然后开始构造一个key对应的value迭代器。这时就要用到分组,使用job.setGroupingComparatorClass设置的分组函数类。只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器,而这个迭代器的key使用属于同一个组的所有key的第一个key。最后就是进入Reducer的reduce方法,reduce方法的输入是所有的(key和它的value迭代器)。同样注意输入与输出的类型必须与自定义的Reducer中声明的一致。
启动hadoop
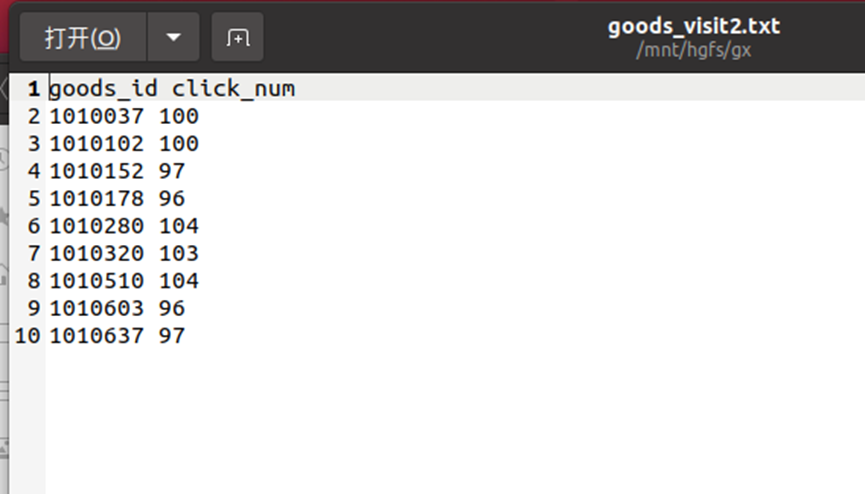
生成文件
创建项目、写入代码
运行结果: