本篇做一个没有实用价值的mnist rpc服务,重点记录我在调试整合tensorflow和opencv时遇到的问题;
准备模型
mnist的基础模型结构就使用tensorflow tutorial给的例子,卷积-池化-卷积-池化-全连接-dropout-softmax,然后走常规的优化训练,得到一个错误率2.0%的结果;
然后准备一个单张图片的输入,一个(1, 28, 28, 1)的tensor,输入到模型里,得到一个单条的输出,给它们定好名字;
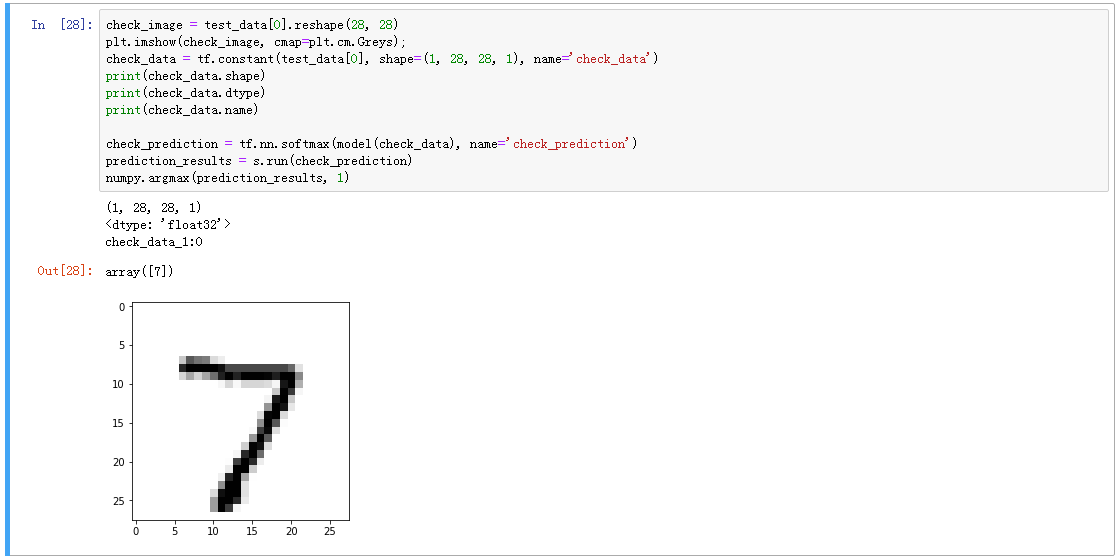
将模型保存下来:

加载模型
用c++写一个thrift rpc server,在handler的实例化阶段加载模型,加载过程与上一篇一致:
bool MNISTRecognizeServletHandler::Init() { // init session Status status = NewSession(SessionOptions(), &session_); if (!status.ok()) { LOG(ERROR) << status.ToString(); return false; } else { session_inited_ = true; } // load graph graph_def_ = new GraphDef(); std::string model_path = FLAGS_model_path; status = ReadBinaryProto(Env::Default(), model_path, graph_def_); if (!status.ok()) { LOG(ERROR) << status.ToString(); return false; } else { graph_loaded_ = true; } // prepare session status = session_->Create(*graph_def_); if (!status.ok()) { LOG(ERROR) << status.ToString(); return false; } else { session_prepared_ = true; } }
识别图片
接下来就可以识别图片了,输入是一个图片内容,输出是识别结果,这里是我耗时最多的部分,主要原因是对opencv不熟悉;
载入图片
std::vector<uint8> vectordata(image_content.begin(), image_content.end()); cv::Mat data_mat(vectordata, true); cv::Mat raw_image(cv::imdecode(data_mat, CV_LOAD_IMAGE_COLOR)); //cv::Mat raw_image(cv::imdecode(data_mat, CV_LOAD_IMAGE_GRAYSCALE));
这里从string将图片数据存入Mat,然后对图片进行解码;
解码时加载彩色图,其实也可以直接加载灰度图,但是因为我计划将一些图片的预处理过程封装成一个函数,所以这里就不加载成灰度图了;
图片预处理
cv::Mat prepared_image; prepare_image(raw_image, prepared_image); void prepare_image(const Mat& img, Mat& prepared_img) { cvtColor(img, prepared_img, CV_BGR2GRAY); resize(prepared_img, prepared_img, Size(INPUT_WIDTH, INPUT_HEIGHT)); prepared_img = 255 - prepared_img; }
预处理主要做了三件事,彩图转灰度图,转换大小,取反色;
这里的取反色浪费了我许多时间,一开始不知道要取反,直接丢进模型里,得到的识别结果非常差,总以为是从Mat往Tensor转换时出了问题,后来把tensorflow做模型训练时的python PIL输入数据和C++ opencv的Mat打印出来一比对,才发现灰度值反了;
Mat转Tensor
这里参考了tensorflow issue 8033的最佳答案,避免一次数据拷贝从而提升图像处理速度,我虽然不关心速度,但是也不想一行行的拷贝数据,所以就参考了这个方案;
Tensor input_image(DT_FLOAT, TensorShape({1, INPUT_WIDTH, INPUT_HEIGHT, 1}));
float *p = input_image.flat<float>().data();
cv::Mat input_mat(INPUT_WIDTH, INPUT_HEIGHT, CV_32FC1, p);
prepared_image.convertTo(input_mat, CV_32FC1);
丢入模型
把输入准备好,再把输出取出来
std::vector<std::pair<string, tensorflow::Tensor>> inputs = { {FLAGS_input_tensor_name, input_image}, }; std::vector<tensorflow::Tensor> outputs; Status status = session_->Run(inputs, {FLAGS_output_tensor_name}, {}, &outputs);
这里的input_tensor_name和output_tensor_name分别对应第一步准备模型时定好的名字;
得到结果
这一步做的有点丑,因为不知道有没有现成的对标numpy.argmax的函数,于是遍历了一遍输出tensor的buffer;
Tensor prediction_tensor = outputs[0]; float *results = prediction_tensor.flat<float>().data(); int ret = -1; int max = 0; for (int i = 0; i < prediction_tensor.NumElements(); i++) { if (results[i] > max) { max = results[i]; ret = i; } }
调用RPC
写一个python thrift client,读入图片内容,然后丢给rpc server
thrift_client = ThriftClient(FLAGS.thrift_ip, FLAGS.thrift_port, MNISTRecognizeServlet) fh = open(FLAGS.image_path) img_buf = fh.read() v = thrift_client.Recognize(img_buf) print v