why 树形结构
- 顺序存储
顺序存储的特点是各个存储单位在逻辑和物理内存上都是相邻的,典型的就是代表就是数组,物理地址相邻因此我们可以通过下标很快的检索出一个元素
我们想往数组中添加一个元素最快的方式就是往它的尾部添加.如果往头部添加元素的话,效率就很低,因为需要将从第一个元素开始依次往后移动一位,这样就能空出第一位的元素,然后才能将我们指定的数据插入到第一个的位置上
- 链式存储
链式存储的特点是,各个节点之间逻辑是相邻的,但是物理存储上不相邻,每一个节点都存放一个指针或者是引用用来指向它的前驱或者后继节点, 因此我们想插入或者删除一个元素时速度就会很块,只需要变动一下指针的指向就行
但是对链表来说查找是很慢的, 因此对任意一个节点来说,他只知道自己的下一个节点或者是上一个节点在哪里,再多的他就不不知道了,因此需要从头结点开始遍历...
- 树
树型存储结构有很多种,比如什么二叉树,满二叉树,红黑树,B树等, 对于树形结构来说,它会相对中和链式存储结构和顺序存储结构的优缺点 (其中二叉排序树最能直接的体会出树中和链式存储和线性存储的特性,可以通过右边的导航先去看看二叉排序树)
树的概述
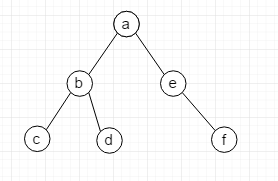
如上图是一个二叉树, 当然树还能有三叉,四叉等等...
- 根节点: 最顶上的节点 即a
层: 根节点在第一层 BE在第二层
高度: 最大的层数
森林: 多个树的组合
权: 节点上的值 如根节点的权是 a
叶子节点: 下层上的节点是上一层的叶子节点
双亲节点: 上层的节点是下层的节点的双亲节点(单个节点又是爸又是妈)
路径: 找到C的路径是 a-b-c
度: 就是直接子节点的个数
普通二叉树
- 什么是二叉树?
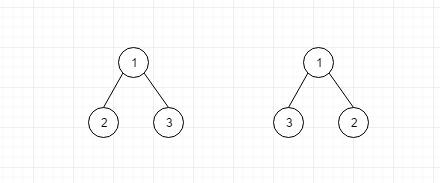
顾名思义就是度最大为2的树就是二叉树.而且对二叉树来说,是严格区分左子树和右子树的,看上图,虽然两个树的根节点都是1,但是他们的左右子树不同,因此他们并不是相同的树
- 什么是满二叉树?
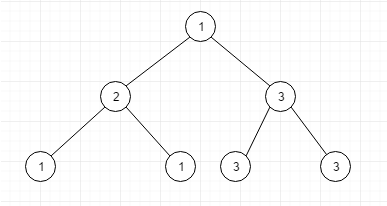
像上图这样,所有的叶子节点都在最后一层,所有的且除了最后一层其他层的节点都有两个子节点
二叉树的全部节点计算公式是 2^n+1 , n是层数
- 什么是完全二叉树?
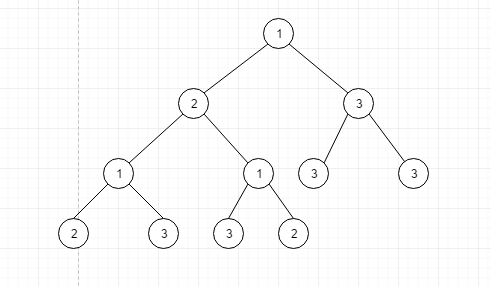
像上图这样, 所有的叶子点都在最后一层或者是倒数第二层, 并且从左往右数是连续的
java&二叉树
- 封装二叉树节点
public class TreeNode {
// 权
private int value;
// 左节点
private TreeNode leftNode;
// 右节点
private TreeNode rightNode;
}
- 封装二叉树
public class BinaryTree {
TreeNode root;
public void setRoot(TreeNode root) {
this.root = root;
}
public TreeNode getRoot() {
return this.getRoot();
}
}
遍历
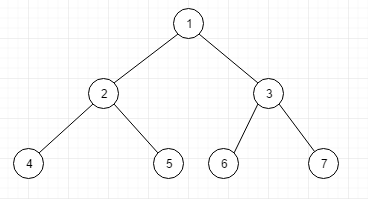
像这样一颗二叉树,通过不同的顺序遍历会得到不同的结果
前中后的顺序说的是root节点的顺序,前序的话就是先遍历父节点, 中序就是左父右 后续就是左右父
- 前序遍历
public void frontShow() {
System.out.println(this.value);
if (leftNode != null)
leftNode.frontShow();
if (rightNode != null)
rightNode.frontShow();
}
- 中序遍历
public void middleShow() {
if (leftNode != null)
leftNode.middleShow();
System.out.println(value);
if (rightNode != null)
rightNode.middleShow();
}
- 后续遍历
public void backShow() {
if (leftNode != null)
leftNode.backShow();
if (rightNode != null)
rightNode.backShow();
System.out.println(value);
}
查找
其实有了上面三种遍历的方式, 查找自然存在三种, 一边遍历一边查找
public TreeNode frontSeach(int num) {
TreeNode node = null;
// 当前节点不为空,返回当前节点
if (num == this.value) {
return this;
} else {
// 查找左节点
if (leftNode != null) {
node = leftNode.frontSeach(num);
}
if (node != null)
return node;
// 查找右节点
if (rightNode != null)
node = rightNode.frontSeach(num);
}
return node;
}
删除节点
删除节点也是, 不考虑特别复杂的情况, 删除节点就有两种情况, 第一种要删除的节点就是根节点, 那么让根节点=null就ok, 第二种情况要删除的节点不是根节点,就处理它的左右节点, 左右节点还不是需要删除的元素的话那么就得递归循环这个过程
// 先判断是否是根节点,在调用如下方法
public void deleteNode(int i) {
TreeNode parent = this;
// 处理左树
if (parent.leftNode!=null&&parent.leftNode.value==i){
parent.leftNode=null;
return;
}
// 处理左树
if (parent.rightNode!=null&&parent.rightNode.value==i){
parent.rightNode=null;
return;
}
// 递归-重置父节点
parent=leftNode;
if (parent!=null)
parent.deleteNode(i);
// 递归-重置父节点
parent=rightNode;
if (parent!=null)
parent.deleteNode(i);
}
顺序存储二叉树
文章一开始刚说了, 顺序存储的数据结构的典型代表就是数组, 就像这样
[1,2,3,4,5,6,7]
什么是顺序存储的二叉树呢? 其实就是将上面的数组看成了一颗树,就像下图这样
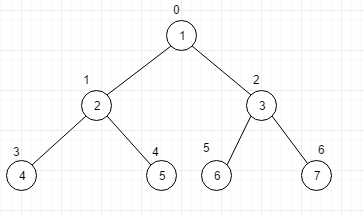
数组转换成二叉树是有规律的, 这个规律就体现在他们的 下标的关联上, 比如我们想找2节点的左子节点的下标就是 2*n -1 = 3 , 于是我们从数组中下标为3的位置取出4来
-
第n个元素的左子节点是 2n-1
-
第n个元素的右子节点是 2n-2
-
第n个元素的父节点是 (n-1)/2
-
遍历顺序存储的二叉树
public void frontShow(int start){
if (data==null||data.length==0){
return;
}
// 遍历当前节点
System.out.println(data[start]);
// 遍历左树
if (2*start+1<data.length)
frontShow(2*start+1);
// 遍历右树
if (2*start+2<data.length)
frontShow(2*start+2);
}
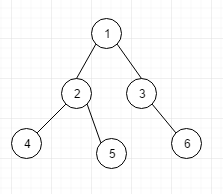
线索二叉树
假设我们有下面的二叉树, 然后我们可以使用中序遍历它, 中序遍历的结果是 4,2,5,1,3,6 但是很快我们就发现了两个问题, 啥问题呢?
-
问题1: 虽然可以正确的遍历出 4,2,5,1,3,6 , 但是当我们遍历到2时, 我们是不知道2的前一个是谁的,(哪怕我们刚才遍历到了它的前一个节点就是4)
-
问题2: node4,5,6,3的左右节点的引用存在空闲的情况
针对这个现状做出了改进就是线索化二叉树, 它可以充分利用各个节点中剩余的node这个现状...线索化后如下图
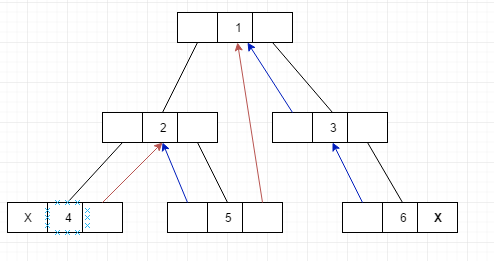
- 如果这个节点的右节点为空,我们就让它让它指向自己的后继节点, 例如上图的红线
- 如何节点的左节点为空, 就让这个空闲的节点指向它的前驱节点,例如上图的蓝色线
这样的话, 就实现了任意获取出一个节点我们都能直接的得知它的前驱节点后后继节点到底是谁
java&中序化二叉树;
思路: 按照原来中序遍历树的思路,对树进行中序遍历,一路递归到4这个节点, 检查到它的左节点为空,就将他的左节点指向它的前驱节点, 可是4本来就是最前的节点,故4这个节点的左节点自然指向了null
然后看它的右节点也为空,于是将他的右节点指向它的后继节点, 可是这时依然没获取到2节点的引用怎么办呢? 于是先找个变量将4节点临时存起来, 再往后递归,等递归到2节点时,取出临时变量的4节点, 4节点.setRightNode(2节点)
然后重复这个过程
// 临时保存上一个节点
private TreeNode preNode;
// 中序线索化二叉树
void threadNode(TreeNode node) {
if (node == null)
return;
// 处理左边
threadNode(node.getLeftNode());
// 左节点为空,说明没有左子节点, 让这个空出的左节点指向它的上一个节点
if (node.getLeftNode() == null) {
// 指向上一个节点
node.setLeftNode(preNode);
// 标识节点的类型
node.setLeftType(1);
}
// 处理前驱节点的右指针
// 比如现在遍历到了1, 1的上一个节点是5, 5的右边空着了, 于是让5的有节点指向1
if (preNode != null && preNode.getRightNode() == null) {
preNode.setRightNode(node);
preNode.setRightType(1);
}
// 每次递归调用一次这个方法就更新前驱节点
preNode = node;
// 处理右边
threadNode(node.getRightNode());
}
遍历二叉树
public void threadIterator() {
TreeNode node = root;
while (node != null) {
// 循环找
while (node.getLeftType() == 0)
node = node.getLeftNode();
// 打印当前节点
System.out.println(node.getValue());
// 如果当前的节点的右type=1说明它有指针指向自己的前一个节点
// 比如现在位置是4, 通过下面的代码可以让node=2
while (node.getRightType() == 1) {
node = node.getRightNode();
System.out.println(node.getValue());
}
// 替换遍历的节点, 可以让 node从2指向 5, 或者从3指向1
node = node.getRightNode();
}
}
赫夫曼树(最优二叉树)
定义: 什么是赫夫曼树
赫夫曼树又称为最优二叉树
定义: 在N个带权的叶子节点的所组成的所有二叉树中,如果你能找出那个带权路径最小的二叉树,他就是赫夫曼树
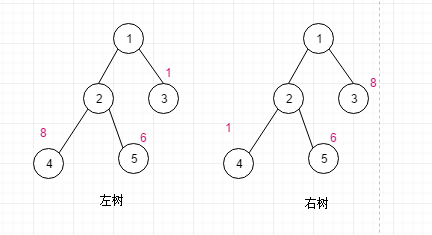
一说起来赫夫曼树,其实我们可以只关心它的叶子节点, 权, 路径这三个要素
- 什么是叶子节点的带权路径?
所谓权,其实就是节点的值, 比如上图中node4的权是8 , node5的权是6 ,node3的权是1, 而且我们只关心叶子节点的权
啥是带权路径呢? 比如上图中 node4的带权路径是 1-2-4
- 树的带权路径长度(weight path length) 简称 WPL
其实就是这个树所有的叶子节点的带权路径长度之和,
计算左树的WPL =2*8+2*6+1*1 = 29
计算左树的WPL =2*1+2*6+1*8 = 22
总结: 权值越大的节点,离根节点越近的节点是最优二叉树
实战: 将数组转换为赫夫曼树
- 思路:

假设我们现在已经有了数组 [3,5,7,8,11,14,23,29], 如何将这个数组转换成赫夫曼树呢?
取出这里最小的node3 和 倒数第二小的node5 ,构建成新的树, 新树的根节点是 node3,5的权值之和, 将构建完成的树放回到原数组中
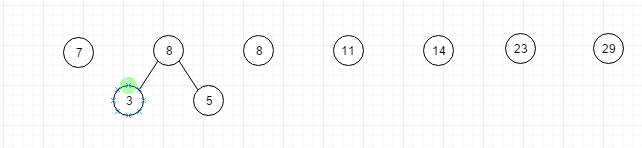
重复这个过程, 将最小的node7,node8取出,构建新树, 同样新树的权重就是 node7,8的权重之和, 再将构建完成的树放回到原数组中
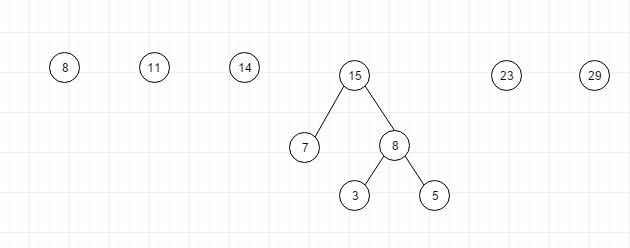
如此往复,最终得到的树就是huffman树
- java实现:
封装TreeNode, 看上面的过程可以看到,需要比较权重的大小,因此重写它的compareTo方法
public class TreeNode implements Comparable{
// 权
private int value;
private TreeNode leftNode;
private TreeNode rightNode;
@Override
public int compareTo(Object o) {
TreeNode node = (TreeNode) o;
return this.value-node.value;
}
构建赫夫曼树, 思路就是上图的过程, 将数组中的各个元素转换成Node. 然后存放在List容器中,每轮构建新树时需要排序, 当集合中仅剩下一个节点,也就是根节点时完成树的构建
// 创建赫夫曼树
private static TreeNode buildHuffmanTree(int[] arr) {
// 创建一个集合,存放将arr转换成的二叉树
ArrayList<TreeNode> list = new ArrayList<>();
for (int i : arr) {
list.add(new TreeNode(i));
}
// 开始循环, 当集合中只剩下一棵树时
while (list.size() > 1) {
// 排序
Collections.sort(list);
// 取出权值最小的数
TreeNode leftNode = list.get(list.size() - 1);
// 取出权值次要小的数
TreeNode rightNode = list.get(list.size() - 2);
// 移除取出的两棵树
list.remove(leftNode);
list.remove(rightNode);
// 创建新的树根节点
TreeNode parentNode = new TreeNode(leftNode.getValue() + rightNode.getValue(), leftNode, rightNode);
// 将新树放到原树的集合中
list.add(parentNode);
}
return list.get(0);
}
实战: 赫夫曼树与数据压缩
通过上面的介绍我们能直观的看出来,赫夫曼树很显眼的特征就是它是各个节点能组成的树中,那颗WPL,带权路径长度最短的树, 利用这条性质常用在数据压缩领域, 即我们将现有的数据构建成一个赫夫曼树, 其中出现次数越多的字符,就越靠近根节点, 经过这样的处理, 就能用最短的方式表示出原有字符
假设我们有这条消息can you can a can as a canner can a can.
数据对计算机来说不过是0-1这样的数字, 我们看看将上面的字符转换成01这样的二进制数它长什么样子
1. 将原字符串的每一个char强转换成 byte == ASCII
99 97 110 32 121 111 117 32 99 97 110 32 97 32 99 97 110 32 97 115 32 97 32 99 97 110 110 101 114 32 99 97 110 32 97 32 99 97 110
2. 将byte toBinaryString 转换成01串如下:
1100011110000111011101000001111001110111111101011
0000011000111100001110111010000011000011000001100
0111100001110111010000011000011110011100000110000
1100000110001111000011101110100000110001111000011
1011101101110110010111100101000001100011110000111
011101000001100001100000110001111000011101110101110
也就是说,如果我们不对其进行压缩时, 它将会转换成上面那一大坨在网络上进行传输
使用赫夫曼进行编码:
思路: 我们将can you can a can as a canner can a can. 中的每一个符号,包括 点 空格,全部封装进TreeNode
TreeNode中属性如下: 包含权重: 也就是字符出现的次数, 包含data: 字符本身
public class TreeNode implements Comparable{
// 存放权重就是字符出现的次数
private int weight;
// 存放英文数值
private Byte data; //
private TreeNode leftNode;
private TreeNode rightNode;
封装完成后, 按照权重的大小倒序排序,各个节点长成这样:
a:11 :11 n:8 c:7 o:1 .:1 y:1 e:1 u:1 s:1 r:1
将赫夫曼树画出来长这样:
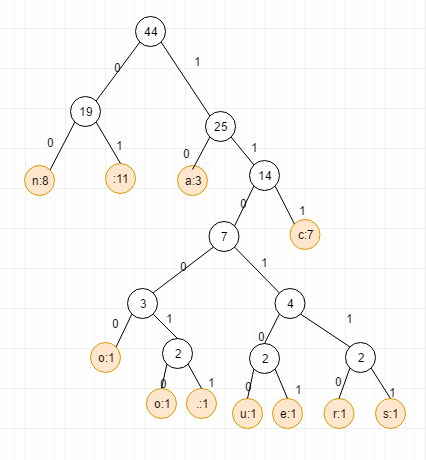
特征,我们让左侧的路径上的值是0, 右边是1. 因此通过这个赫夫曼树其实我们可以得到一张赫夫曼编码表,
比如像下面这样:
n: 00
: 01
a: 10
c: 111
// 每一个字符的编码就是从根节点到它的路径
有了这样编码表, 下一步就是对数据进行编码, 怎么编码呢? 不就是做一下替换吗? 我们现在开始循环遍历一开始的字符串, 挨个取出里面的字符, 比如我们取出第一个字符是c, 拿着c来查询这个表发现,c的编码是111,于是我们将c替换成111, 遍历到第二个字符是a, 拿着a查询表,发现a的值是10, 于是我们将a替换成10, 重复这个过程, 最终我们得到的01串明显比原来短很多
怎么完成解码呢? 解码也不复杂, 前提也是我们得获取到huffman编码表, 使用前缀匹配法, 比如我们现在接收到了
1111000xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
使用前缀就是先取出1 去查查编码表有没有这个数? 有的话就返回对应的字符, 没有的话就用11再去匹配
大家可以看看上面的那颗霍夫曼树, 所有的data都在叶子节点上,所以使用前缀匹配完全可以,绝对不会出现重复的情况
- 使用java实现这个过程
思路概览:
- 将原生的字节数组转化成一个个的TreeNode
- 取出所有的TreeNode封装成赫夫曼树
- 通过赫夫曼树踢去出赫夫曼编码表
- 使用这个编码表进行编码
- 解码
private static byte[] huffmanZip(byte[] bytes) {
// 先统计每个byte出现的次数,放入集合中
List<TreeNode> treeNodes = buildNodes(bytes);
// 创建赫夫曼树
TreeNode node = createHuffmanTree(treeNodes);
// 创建huffman编码表
Map<Byte, String> codes = createHuffmanCodeTable(node);
// 编码, 将每一个byte替换成huffman编码表中的V
byte[] encodeBytes = encodeHuffmanByte(bytes, codes);
// 使用huffman编码进行解码
byte[] decodeBytes = decode(encodeBytes);
return decodeBytes;
}
将原生的byte数组,封装成一个个的TreeNode节点,保存在一个容器中,并且记录下这个节点出现的次数, 因此我们需要将出现次数多的节点靠近根节点
/**
* 将byte转换成node集合
*
* @param bytes
* @return
*/
private static List<TreeNode> buildNodes(byte[] bytes) {
ArrayList<TreeNode> list = new ArrayList<>();
HashMap<Byte, Integer> countMap = new HashMap<>();
// 统计每一个节点的出现的次数
for (byte aByte : bytes) {
Integer integer = countMap.get(aByte);
if (integer == null) {
countMap.put(aByte, 1);
} else {
countMap.put(aByte, integer + 1);
}
}
// 将k-v转化成node
countMap.forEach((k, v) -> {
list.add(new TreeNode(v, k));
});
return list;
}
构建赫夫曼树
/**
* 创建huffman树
*
* @param treeNodes
* @return
*/
private static TreeNode createHuffmanTree(List<TreeNode> treeNodes) {
// 开始循环, 当集合中只剩下一棵树时
while (treeNodes.size() > 1) {
// 排序
Collections.sort(treeNodes);
// 取出权值最小的数
TreeNode leftNode = treeNodes.get(treeNodes.size() - 1);
// 取出权值次要小的数
TreeNode rightNode = treeNodes.get(treeNodes.size() - 2);
// 移除取出的两棵树
treeNodes.remove(leftNode);
treeNodes.remove(rightNode);
// 创建新的树根节点
TreeNode parentNode = new TreeNode(leftNode.getWeight() + rightNode.getWeight(), leftNode, rightNode);
// 将新树放到原树的集合中
treeNodes.add(parentNode);
}
return treeNodes.get(0);
}
从赫夫曼树中提取出编码表, 思路: 下面是完了个递归, 我们规定好左树是0,右边是1, 通过一个SpringBuilder, 每次迭代都记录下原来走过的路径,当判断到它的data不为空时,说明他就是叶子节点,立即保存这个节点曾经走过的路径,保存在哪里呢? 保存在一个map中, Key就是byte value就是走过的路径
static StringBuilder stringBuilder = new StringBuilder();
static Map<Byte, String> huffCode = new HashMap<>();
/**
* 创建huffman便编码表
*
* @param node
* @return
*/
private static Map<Byte, String> createHuffmanCodeTable(TreeNode node) {
if (node == null)
return null;
getCodes(node.getLeftNode(), "0", stringBuilder);
getCodes(node.getRightNode(), "1", stringBuilder);
return huffCode;
}
/**
* 根据node, 获取编码
*
* @param node
* @param code
* @param stringBuilder
*/
private static void getCodes(TreeNode node, String code, StringBuilder stringBuilder) {
StringBuilder sb = new StringBuilder(stringBuilder);
sb.append(code);
// 如果节点的data为空,说明根本不是叶子节点,接着递归
if (node.getData() == null) {
getCodes(node.getLeftNode(), "0", sb);
getCodes(node.getRightNode(), "1", sb);
} else {
// 如果是叶子节点,就记录它的data和路径
huffCode.put(node.getData(), sb.toString());
}
}
根据赫夫曼编码表进行编码:
思路:
举个例子: 比如,原byte数组中的一个需要编码的字节是a
a的ASCII==97
97正常转成二进制的01串就是 0110 0001
但是现在我们有了编码表,就能根据97从编码表中取出编码: 10
换句话说,上面 0110 0001 和 10 地位相同
若干个需要编码的数append在一起,于是我们就有了一个比原来短一些的01串, 但是问题来了,到这里就结束了吗? 我们是将这些01串转换成String, 在getBytes()返回出去吗? 其实不是的,因为我们还需要进行解码,你想想解码不得编码map中往外取值? 取值不得有key? 我们如果在这里将这个01串的byte数组直接返回出去了,再按照什么样的方式将这个byte[]转换成String串呢? ,因为我们要从这个String串中解析出key
然后这里我们进行约定, 将现在得到的01串按照每8位为一组转换成int数, 再将这个int强转成byte, 解码的时候我们就知道了.就按照8位一组进行解码. 解析出来数组再转换成01串,我们就重新拿到了这个编码后的01串,它是个String串
每遇到8个0或者1,就将它强转成Int, 再强转成type, 经过这样的转换可能会出现负数,因此01串的最前面有个符号位,1表示负数
比如说: 如果你打印一下面代码中的encodeByte,你会发现打印的第一个数是-23, 这个-23被保存在新创建的byte数组的第一个位置上, 后续解码时,就从这个byte数组中的第一个位置上获取出这个-23, 将它转换成01二进制串
怎么转换呢? 比如不是-23, 而是-1
真值 1
原码:1,0001
补码: 2^(4+1) +1 = 100000 + (-1) = 1,1111
我们获取到的结果就是1111
/**
* 进行编码
*
* @param bytes
* @param codes
* @return
*/
private static byte[] encodeHuffmanByte(byte[] bytes, Map<Byte, String> codes) {
StringBuilder builder = new StringBuilder();
for (byte aByte : bytes) {
builder.append(codes.get(aByte));
}
// 将这些byte按照每8位一组进行编码
int length = 0;
if (builder.length() % 8 == 0) {
length = builder.length() / 8;
} else {
length = builder.length() / 8 + 1;
}
// 用于存储压缩后的byte
byte[] resultByte = new byte[length];
// 记录新byte的位置
int index = 0;
// 遍历新得到的串
for (int i = 0; i < builder.length(); i += 8) {
String str = null;
if (i + 8 > builder.length()) {
str = builder.substring(i);
} else {
str = builder.substring(i, i + 8);
}
// 将八位的二进制转换成byte
// 这里出现负数了.... 涉及到补码的问题
byte encodeByte = (byte) Integer.parseInt(str, 2);
// 存储起来
resultByte[index] = encodeByte;
index++;
}
return resultByte;
}
解码: 前面我们知道了,约定是按照8位转换成的int 再转换成type[] , 现在按照这个约定,反向转换出我们一开始的01串
/**
* 按照指定的赫夫曼编码表进行解码
*
* @param encodeBytes
* @return
*/
private static byte[] decode(byte[] encodeBytes) {
List<Byte> list = new ArrayList();
StringBuilder builder = new StringBuilder();
for (byte encodeByte : encodeBytes) {
// 判断是否是最后一个,如果是最后一次不用用0补全, 因此最后一位本来就不够8位
boolean flag = encodeByte == encodeBytes[encodeBytes.length - 1];
String s = byteToBitStr(!flag, encodeByte);
builder.append(s);
}
// 调换编码表的k-v
Map<String, Byte> map = new HashMap<>();
huffCode.forEach((k, v) -> {
map.put(v, k);
});
// 处理字符串
for (int i = 0; i < builder.length(); ) {
int count = 1;
boolean flag = true;
Byte b = null;
while (flag){
String key = builder.substring(i,i+count);
b=map.get(key);
if (b==null){
count++;
}else {
flag=false;
}
}
list.add(b);
i+=count;
}
// 将list转数组
byte[] bytes = new byte[list.size()];
int i=0;
for (Byte aByte : list) {
bytes[i]=aByte;
i++;
}
return bytes;
}
/**
* 将byte转换成二进制的String
*
* @param b
* @return
*/
public static String byteToBitStr(boolean flag, byte b) {
/**
* 目标: 全部保留八位.正数前面就补零, 负数前面补1
* 为什么选256呢? 因为我们前面约定好了, 按照8位进行分隔的
* 256的二进制表示是 1 0000 0000
* 假设我们现在是 1
* 计算 1 0000 0000
* 或 0 0000 0001
* ----------------------
* 1 0000 0001
* 结果截取8位就是 0000 0001
*
* 假设我们现在是 -1
* 转换成二进制: 1111 1111 1111 1111 1111 1111 1111 1111
*
* 计算 1 0000 0000
* 或 1111 1111 1111 1111 1111 1111 1111 1111
* ----------------------
* 1 1111 1111
* 结果截取8位就是 1111 1111
*
*
*/
int temp = b;
if (flag) {
temp |= 256;
}
String str = Integer.toBinaryString(temp);
if (flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
二叉排序树
二叉排序树, 又叫二叉搜索树 , BST (Binary Search Tree)
- 线性存储和链式存储的优缺点
比如我们有一个数组 [7,3,10,12,5,1,9]
虽然我们可以直接取出下标为几的元素,但是却不能直接取出值为几的元素, 比如,我们如果想取出值为9的元素的话,就得先去遍历这个数组, 然后挨个看看当前位置的数是不是9 , 就这个例子来说我们得找7次
假设我们手里的数组已经是一个有序数组了 [1,3,5,7,9,11,12]
我们可以通过二分法快速的查找到想要的元素,但是对它依然是数组,如果想往第一个位置上插入元素还是需要把从第一个位置开始的元素,依次往后挪. 才能空出第一个位置,把新值放进去
假设我们将这一行数转换成链式存储, 确实添加, 删除变的异常方便, 但是查找还是慢, 不管是查询谁, 都得从第一个开始往后遍历
- 我们的主角: 二叉搜索树
二叉排序树有如下的特点:
- 对于二叉排序树中的任意一个非叶子节点都要求他的左节点小于自己, 右节点大于自己
- 空树也是二叉排序树
将上面的无序的数组转换成二叉排序树长成下图这样
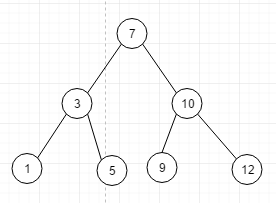
如果我们按照中序遍历的话结果是: 1 3 5 7 9 11 12 , 正好是从小到大完成排序
再看他的特征: 如果我们想查找12 , 很简单 7-10-12 , 如果我们想插入也很简单,它有链表的特性
java&二叉排序树
封装Node和Tree
// tree
public class BinarySortTree {
Node root;
}
// node
public class Node {
private int value;
private Node leftNode;
private Node rightNode;
}
构建一颗二叉排序树, 思路是啥呢? 如果没有根节点的话,直接返回,如果存在根节点, 就调用根节点的方法,将新的node添加到根节点上, 假设我们现在遍历到的节点是NodeA. 新添加的节点是NodeB, 既然想添加就得比较一下NodeA和NodeB的值的大小, 将如果NodeB的值小于NodeA,就添加在NodeA的右边, 反之就添加在NodeA的左边
-----------BinarySortTree.class---------------
/**
* 向二叉排序树中添加节点
*/
public void add(Node node) {
if (root == null) {
root = node;
} else {
root.add(node);
}
}
-------------Node.class------------
/**
* 添加节点
*
* @param node
*/
public void add(Node node) {
if (node == null)
return;
//判断需要添加的节点的值比传递进来的节点的值大还是小
// 添加的节点小于当前节点的值
if (node.value < this.value) {
if (this.leftNode == null) {
this.leftNode = node;
} else {
this.leftNode.add(node);
}
} else {
if (this.rightNode == null) {
this.rightNode = node;
} else {
this.rightNode.add(node);
}
}
}
删除一个节点
删除一节点有如下几种情况, 但是无论是哪种情况,我们都的保存当前节点的父节点, 通过他的父节点对应节点=null实现节点的删除
情况1: 如图
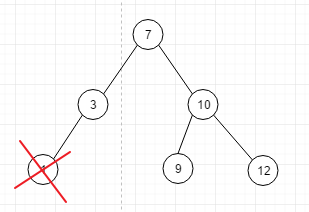
这是最好处理的情况, 就是说需要删除的元素就是单个的子节点
情况2: 如图
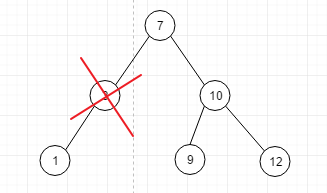
这种情况也不麻烦,比如我们想删除上图中的2号节点, 我们首先保存下node2的父节点 node7, 删除node2时发现node2有一个子节点,于是我们让 node7 的 leftNode = node1
情况3: 如图
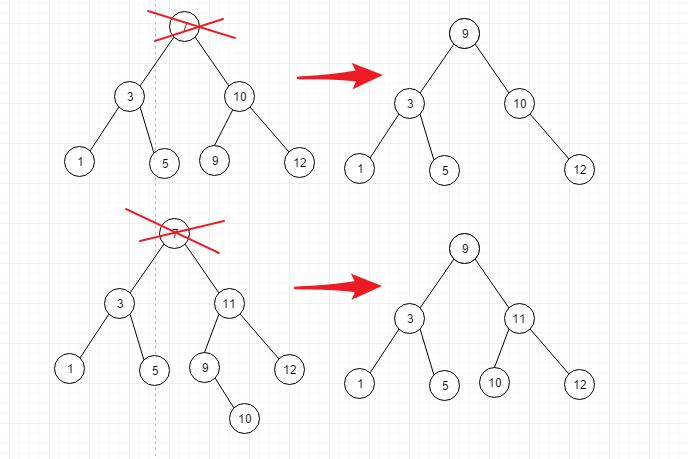
比如我们想删除7, 但是7这个节点还有一个子树 按照中序遍历这个树的顺序是 1,3,5,7,9,11,13, 想删除7的话,其实
- 临时存储node9
- 删除node9
- 用临时存储的node9替换node7
如果node9还有右节点怎么办呢?
- 临时保存node9
- 删除node9
- 让node9的右节点替换node9
- 让临时存储的node9替换node7
/**
* 删除一个节点
*
* @param value
* @return
*/
public void delete(int value) {
if (root == null) {
return;
} else {
// 找到这个节点
Node node = midleSearch(value);
if (node == null)
return;
// 找到他的父节点
Node parentNode = searchParent(value);
// todo 当前节点是叶子节点
if (node.getLeftNode() == null && node.getRightNode() == null) {
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(null);
} else {
parentNode.setRightNode(null);
}
// todo 要删除的节点存在两个子节点
} else if (node.getLeftNode() != null && node.getRightNode() != null) {
// 假设就是删除7
//1. 找到右子树中最小的节点,保存它的值,然后删除他
int minValue = deleteMin(node.getRightNode());
//2.替换被删除的节点值
node.setValue(minValue);
} else { // todo 要删除的节点有一个左子节点或者是右子节点
// 左边有节点
if (node.getLeftNode() != null) {
// 要删除的节点是父节点的左节点
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(node.getLeftNode());
} else {// 要删除的节点是父节点的右节点
parentNode.setRightNode(node.getLeftNode());
}
} else { // 右边有节点
// 要删除的节点是父节点的右节点
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(node.getRightNode());
} else {// 要删除的节点是父节点的右节点
parentNode.setRightNode(node.getRightNode());
}
}
}
}
}
/**
* 删除并保存以当前点为根节点的树的最小值节点
* @param node
* @return
*/
private int deleteMin(Node node) {
// 情况1: 值最小的节点没有右节点
// 情况2: 值最小的节点存在右节点
// 但是下面我们使用delete,原来考虑到了
while(node.getLeftNode()!=null){
node=node.getLeftNode();
}
delete(node.getValue());
return node.getValue();
}
/**
* 搜索父节点
*
* @param value
* @return
*/
public Node searchParent(int value) {
if (root == null) {
return null;
} else {
return root.searchParent(value);
}
}
缺点
二叉排序树其实对节点权是有要求的, 比如我们的数组就是[1,2,3,4] 那么画成平衡二叉树的话长下面这样
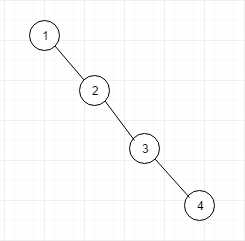
它不仅没有二叉排序树的优点,而且还不如单链表的速度快
AVL树(平衡二叉树)
定义: 什么是平衡二叉树
平衡二叉树的出现就是为了 解决上面二叉排序树[1,2,3,4,5,6]这样成单条链的略势的情况,它要求,每个树的左子树和右子树的高度之差不超过1, 如果不满足这种情况了,马上马对各个节点进行调整,这样做保证了二叉排序树的优势
如何调整
- 情况1: 对于node1来说, 它的左边深度0 , 右边的深度2 , 于是我们将它调整成右边的样子
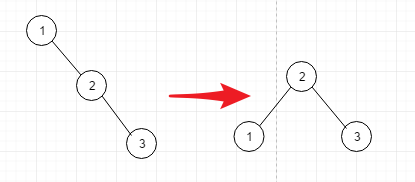
- 情况2: 在1234的情况下, 添加node5,导致node2不平衡, 进行如下的调整
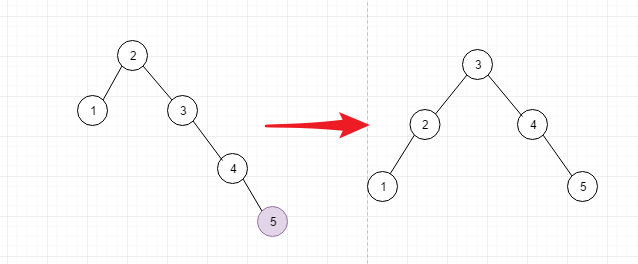
- 情况3: 在12345的基础上添加node6,导致node4不平衡, 对node4进行调整, 其实就和情况1相同了
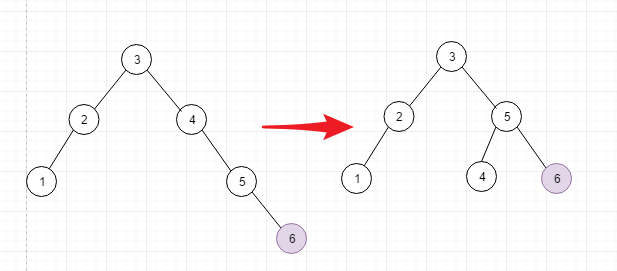
- 情况4: 在1234567的情况下,进行添加8. 打破了node5的平衡, 因此进行旋转
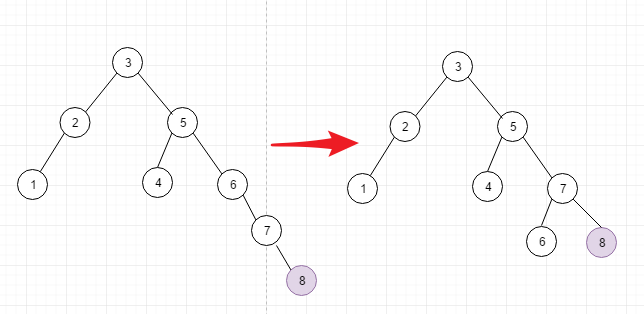
一个通用的旋转规律
看这个典型的有旋转的例子
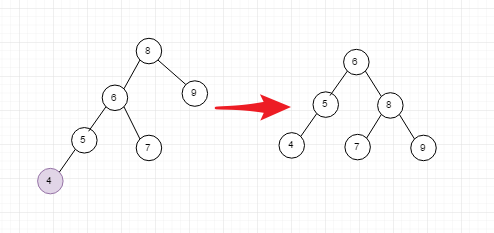
node4的出现,使用node8的平衡被打破, 因此我们需要进行调整, 按照下面的步骤进行调整
下面说的this是根节点node8, 按照下面的步骤在纸上画一画就ok
- 创建新node, 使新node.value = this.value
- 新节点的rightNode = this.rightNode
- 新节点的leftNode = this.leftNode.rightNode
- this.value = this.LeftNode.value
- this.leftNode = this.leftNode .leftNode
- this.leftNode = 新创建的node
**需要注意的情况: **
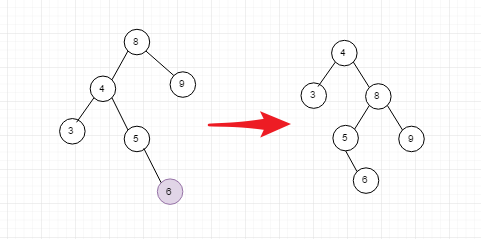
新添加6使得node8不再平衡,但是如果你按照上面的步骤进行旋转的话,会得到右边的结果, 但是右边的结果中对于node4还是不平衡的,因此需要预处理一下
再进行右旋转时,提前进行检验一下,当前节点的左子树是否存在右边比左边高的情况, 如果右边比较高的话,就先将这个子树往左旋转, 再以node8为根,整体往右旋转