- 什么是流?
- 可读流于可写流
- 双工流于转换流
- 背压机制与文件流模拟实现
一、什么是流?
关于流的概念早在1964年就有记录被提出了,简单的说“流”就是控制数据传输过程的程序,比如在那篇记录中有这样的描述:
“在编写代码时,我们应该有一些方法将程序像连接水管一样连接起来 -- 当我们需要获取一些数据时,可以去通过"拧"其他的部分来达到目的。这也应该是IO应有的方式”。
——Doug McIlroy. October 11, 1964
在nodejs中将这种“流”的概念抽象成一个模型,可以实现有序的、可控制大小的、可按需获取的方式实现数据传输,该模型在nodejs中实现的JavaScript层就是tream模块。
1.流的基本模型:

在nodejs中基于流的基本模型又实现了四种基本流类型:
Writable(可写流):可以理解为将数据存储到指定的地方中,例如fs.crateWriteStream()
Readable(可读流):可以理解为将数据从指定的地方取出来,例如fs.crateReadStream()
Duplex(双工流):例如net.Socket
Transform(转换流):例如zlib.crateDeflate()
这个四个流的基本类型在stream模块上都以类的形式作为导出API,我们可以基于这四个基本类型自定义自己的流的具体实现,比如下面通过可读流(Readable)作为示例:
自定义可读流的思考:数据来源、如何获取数据?
数据来源采用一个数组模拟,获取数据的方式流程上stream已经实现了,但具体的获取功能它在内部提供了定义接口,具体功能并没有实现,这就是接下来我们需要实现的部分(假设每次从数组中读取一个数组):
1 //自定义可读流 2 const {Readable} = require('stream'); 3 //模拟数据来源 4 let source = ['a','b','c']; 5 //自定义继承Readable 6 class MyReadable extends Readable{ 7 constructor(source){ 8 super(); 9 this.source = source; 10 } 11 _read(){ 12 let data = this.source.shift() || null; 13 this.push(data); 14 } 15 };
在Readable上有一个read()方法可以获取指定量数据,先不讨论它的具体实现过程,看下面的几个测试结果:
测试一:
//实例化自定义读取流 let myReadable = new MyReadable(source); console.log(myReadable.read(1)); //<Buffer 61> console.log(myReadable.read(1)); //<Buffer 62> console.log(myReadable.read(1)); //<Buffer 63>
测试二:
let myReadable = new MyReadable(source); console.log(myReadable.read()); //<Buffer 61> console.log(myReadable.read(1)); //<Buffer 62> console.log(myReadable.read(1)); //<Buffer 63>
测试三:
//测试三 console.log(myReadable.read(2)); //null console.log(myReadable.read(1)); //<Buffer 61> console.log(myReadable.read(1)); //<Buffer 62>
测试四:
//测试四 console.log(myReadable.read(1)); //<Buffer 61> console.log(myReadable.read(2)); //<null> console.log(myReadable.read(1)); //<Buffer 62>
首先通过打印结果来看,读取流并不是将数组中的元素值直接返回,而返回的是Buffer。这是因为在流内部使用了Buffer作为数据中转容器,通过push传入的数据如果不是Buffer则会使用Buffer.from()转换后再缓存到这个Buffer内。
至于为什么read(size)在前面为什么读出的null,首先要理解size的意思是从缓存内读出指定字节长度的数据,当中转Buffer内没有足够未读的数据就不会返回数据,而是返回null。然后就是要了解Buffer内的数据是什么时候被传入的,当我们每调用一次read()本质上内部就会执行一次_read(),也就是实现向Buffer缓存数据的操作,当Buffer中缓存足够指定读出字节长度时就会成功返回数据,否则就会返回null,比如下面的示例:
console.log(myReadable.read(2)); //null--这次一次向Buffer内存了一个字节,但不够要读的字节长度是2,所以返回null console.log(myReadable.read(2)); //<Buffer 61 62>--这次又向Buffer内存了一个字节,加上次存的字节刚好满足要读的字节长度2,所以成功返回两个字节的数据
通过read()返回数据肯定不是符合流的模式,根据前面前面的基本模型来看,它应该是一种可以自动的将数据源中的数据源源不断的返回,nodejs的流tream底层是通过事件的机制来实现的,所以正确获取数据的方式是通过data、readable事件来获取数据:
myReadable.on('data',(chunk)=>{
console.log(chunk);
});
//打印结果
//<Buffer 61>
//<Buffer 62>
//<Buffer 63>
可读流中data事件获取数据的机制:每一次_read()实现一次数据缓存时,就会触发一次data事件,并将当前_read()缓存到Buffer内的数据全部传递给data事件回调函数作为实参chunk。
可读流readable事件获取数据的机制:该事件会在启动流操作缓存空间写入数据触发一次(也就是_read()执行一次后),然后再是在数据源的数据全部被写入到Buffer后触发一次(但需要注意这个全部写入描述并不准确,因为它是在当_read()向Buffer写入null时触发)。因为任务回调是异步操,当它触发后回调执行时Buffer内的数据量是不确定的,从nodejs流的设计机制来说readable并不是为了获取数据而存在,而仅仅是作为传递流操作的状态信息,但也可以通过这个事件配合read()方法获取数据:
myReadable.on('readable',()=>{
let data = null;
while((data = myReadable.read(1)) !== null){
console.log(data);
}
});
测试在数据源上出现一个null元素对readable事件的影响:
//更新模拟数据来源 let source = ['a','b','c',null,'d','e']; //测试readable事件(还是使用上一个示例的输出代码) <Buffer 61> <Buffer 62> <Buffer 63>
通过输出结果可以看到,在数组中添加的null,'d','e'没有被成功输出,这是因为当push()向Buffer内缓存数据时写入的是null,表示不在为流提供消费数据,类似终止数据源向缓存中提供数据,流操作随之结束。所以,push(null)可以理解为流操作结束的最终阀门,并且无法重启,所以在定义流时push(null)用来表示流的数据源传输数据到达终点。
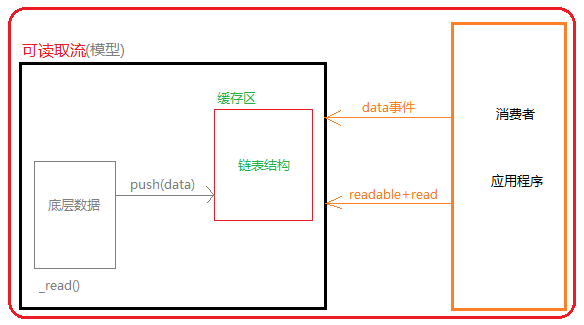
然后就是控制器(阀门的两个操作):
pause()暂停:这个方法会暂停_read()方法向缓存区写数据时触发data事件,也就是说调用这个方法只能中断向消费者输出数据,而不会中断_read()从数据源中读取数据写入缓存区。并且这个方法调用会触发pause事件,既暂停消费数据事件。
resume()启动:这个方法可以重启被pause()暂停的数据消费,重新启动data事件从缓存区读出数据。但需要注意这个方法会触发resume事件,但不是在重启时触发这个事件,而是在表示启动时触发resume事件,关于这个事件的详细内容在下一节解析,这里只需要了解resume()可以重启被pause()暂停的data事件。
1 myReadable.on('data',(chunk)=>{ 2 //消费数据 3 console.log(chunk); 4 if(chunk.toString() === "a"){ 5 console.log("暂停数据消费") 6 myReadable.pause(); 7 } 8 }); 9 myReadable.on("pause",()=>{ 10 //暂停消费数据时触发 11 console.log("重启数据消费"); 12 myReadable.resume(); //重启消费数据 13 }); 14 //测试结果 15 <Buffer 61> 16 暂停数据消费 17 重启数据消费 18 <Buffer 62> 19 <Buffer 63>
通过上面对可读流的简单测试和解析,可以了解到流就是将数据从一个地方源源不断的传输到另一个地方,并且可以通过控制传输单个数据节点的大小来控制传输速度,也可以随时暂停和启动来实现传输的可控性。但关于中转缓存部分没有做任何解析,而这部分直接关系到内存的分配和使用,这也是影响I/O性能的核心部分,接下来逐个解析可读流、可写流、双工流、转换流。
二、可读流与写入流
2.1可写流:
1 //自定义可写流 2 const {Writable} = require('stream'); 3 let buf = Buffer.alloc(10,0,'utf-8'); //数据写入的目的地 4 class MyWritable extends Writable { 5 constructor(options){ 6 super(options); 7 this.buf = buf; 8 this.offset = 0; 9 } 10 _write(chunk, en, done){ 11 setTimeout(()=>{ 12 this.buf.write(chunk.toString(),this.offset); //因为中间缓存写入将数据转换成了Buffer,这里buf接收数据的编码是utf-8,所以又要转换成字符串 13 this.offset++; 14 done(); 15 }); 16 } 17 }; 18 //构造写入流实例 19 let myWritable = new MyWritable({ 20 highWaterMark:1 21 }); 22 //写入数据 23 myWritable.write('a',()=>{ 24 console.log(buf); //<Buffer 61 00 00 00 00 00 00 00 00 00> 25 }); 26 myWritable.write('b',()=>{ 27 console.log(buf); //<Buffer 61 62 00 00 00 00 00 00 00 00> 28 }); 29 myWritable.write('c',()=>{ 30 console.log(buf); //<Buffer 61 62 63 00 00 00 00 00 00 00> 31 });
根可读流一样,在写入数据流中包含数据源(write()写入的数据)、中间缓存、目的地(最后数据存储的地方,示例中用buffer作为这个数据的写入目的地),同样也可以实现源源不断的向数据存储资源中写入数据。
然后就是关于写入流如何控制,这个控制涉及两个方面:一是单次向程序写入的数据量如何控制,二是什么时候应该停止写入数据。
关于写入流的单次写入量可以通过两种方式:
第一种方式可以在write()写入时控制写入数据块的大小,但这不能实现对内存消耗的精准把控,单个数据块写入多少是合适的,写入的频率如何掌控都只能从大概的推测上来实现。
第二种方式是基于流的drain事件配合highwaterMark设置中间缓存大小来实现控制,当使用write()写入数据时,如果当前写入到中间缓存的数据到达highwaterMark设置的最大值就会返回false,这时候就意味着中间缓存空间已经占满,但中间缓存依然还在内部持续的向目标空间写入,如果写入完毕中间缓存清空就会触发drain事件。基于流的这样实现就可以在write()写入返回false时停止写入,等待drain事件触发再写入数据,这样就实现了控制数据写入的启停操作,当然单个数据块大小也可以基于highwaterMark的设置来考虑。
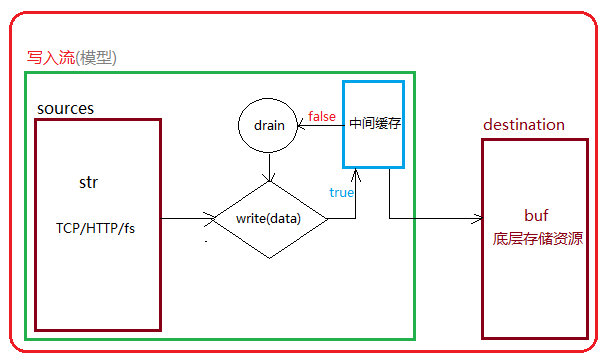
更具前面的解析和流程图再来看下面的具体示例:
1 //自定义可写流(实现可控的数据写入操作) 2 const {Writable} = require('stream'); 3 let buf = Buffer.alloc(10,0,'utf-8'); 4 class MyWritable extends Writable { 5 constructor(options){ 6 super(options); 7 this.buf = buf; 8 this.offset = 0; 9 } 10 _write(chunk, en, done){ 11 setTimeout(()=>{ 12 this.buf.write(chunk.toString(),this.offset); 13 this.offset++; 14 done(); 15 }); 16 } 17 }; 18 19 20 let myWritable = new MyWritable({ 21 highWaterMark:1 22 }); 23 let source = 'abc'.split(""); 24 let flag = true; 25 let num = 0; 26 27 function fun(){ 28 while(flag && num < source.length){ 29 flag = myWritable.write('a',()=>{ 30 console.log(buf); 31 }); 32 num ++; 33 } 34 } 35 36 myWritable.on('drain',()=>{ 37 console.log("drain 执行了"); //表示中间缓存数据已经完全写入到目的地,可以重启数据写入操作 38 flag = true; 39 fun(); 40 }); 41 fun();
最后介绍一下关于写入流的其他方法、事件、配置属性:
//方法、实例化配置 write():实现数据写入操作。 cork():该方法用于强制所有写入数据缓存在中间缓存中,只有调用uncork()、end()方法后才会重新启动向目的地写入数据 uncork():重新启动向目的地写入数据,用于关闭之前cork()的操作。 end():表示不在写入数据,但这个方法依然还可以像write()方法一样写入最后一个数据块。这个方法执行后,当中间缓存的数据全部写入到目的地后触发finish事件。 destroy():销毁流,用于强制关闭流操作。如果此时中间缓存还有数据没写入到目的地也不会再写入,并且会报ERR_STREAM_DESTROYED错误。 new Writable([options]):实例话可写流,这里重点来关注options参数,该参数的属性可以用来定制流的具体操作,同等与继承stream.Writable然后在构造内定义具体操作,比如前面示例中定义_write()方法,也可通过这个参数的_write挂载实现,但这里重点来关注一些配置属性: --highWaterMark:设置中间缓存的容量,默认16KB --decodeStrings:用于设置write()向中间缓存写入字符串时是否使用write的编码转换成Buffer,默认为true,这时候_write()接收到的chunk就是Buffer,除String类型以外其他类型不会被转换;如果设置为false,_write()接收到的chunk还是字符串。 --defaultEncoding:指定默认编码格式,如果write()没有指定编码就会使用该默认编码,默认utf8。 --objectMode:是否支持写入字符串、Buffer、Uint8Array以外的JavaScript值,即使为true也不能支持null值。 --emitClose:被销毁后是否触发close事件,默认为true,即销毁流会触发close事件。 --autoDestroy:在结束流操作(即end()指定)以后是否自动使用destroy()销毁流,默认为true。 //事件 dirin:当被写满的中间缓存重新被清空后触发该事件,但第一次write写入之前也会触发这个事件。 finish:在调用end()方法之后,并且所有数据都刷新到底层系统之后触发该事件 colose:当流及其任何底层资源已关闭时,触发该事件,意味者所有流操作结束(如果写入流使用emitClose创建,则始终触发该事件) error:在写入或管道数据时发生错误会触发该事件 pipe:当可读流上调用pipe方法将此写入流添加到其目标集时,触发该事件 unpipe:当可读流通过unpipe()取消该写入流的源流,触发该事件,也就是从可读流的目标集合中删除这个目标时触发事件
2.2可读流:
可读流的两种模式:流动模式、暂停模式。
--流动模式:基于data事件实现的不中断式的提供数据,数据从源到中间缓存,再到数据读出到消费层不做任何控制处理,数据源源不断流向消费层。
--暂停模式:基于pause事件实现可中断式的提供数据模式,数据流中间采用pause()暂停/pause事件/resume()重启控制可读流,数据传输过程中根据需要可控的往消费层传输。
可读流的三种状态:readableFlowing-->null(不提供数据状态)、false(暂停提供数据状态)、true(持续提供数据状态)。
--不提供数据状态:通过绑定data事件、pipe()、resume()、readableFlowing=true,可以使可读流开始主动触发数据读出事件。
--暂停提供数据状态:该状态由pause()、readableFlowing=false、unpipe()触发,该状态只阻止中间缓存向数据消费层提供数据,并不停止数据源向中间缓存写入数据。
--持续提供数据状态:即由data事件、pipe()、resume()、readableFlowing=true实现数据持续流向消费层,该状态下流持续通过data事件、read()向消费层提供数据。
关于可读流在第一节中有详细的示例,这里就不重复了,下面介绍一下可读流相关事件、方法、配置属性:
//方法 destroy():销毁流,用于强制关闭流操作。如果此时中间缓存区有未向外读出的数据也不会再读出了。 isPaused():用于判断当前流是否处于暂停状态,返回boolean值。 pause():用于暂停当前流操作,但不会暂停底层向中间缓存区写入数据。 pipe():管道,该方法用于将可写流绑定到当前的可读流上, read():用于向外读取指定大小数据块的方法,一般用于暂停模式,不建议与流动模式的data事件读取数据混合使用。 resume():重启当前流操作,用于重启被pause()暂停的流操作。 setEncoding():用于设置读取数据的编码操作。 unpipe():用于分离先前使用pipe()绑定的可写流。 unshift():将已读取出来的数据推回到中间缓存区中,用于解决已经被消耗的数据重新被其他数据消费者使用。 wrap():用于兼容旧的nodejs可读流,创建使用旧流作为其数据源的Readable流。 readable[Symbol.asyncIterator]():返回<AsyncIterator>以完全消费流,流将以大小等于highWaterMark的读取块往外读取。 iterator():返回<AsyncIterator>消费流。用于实现迭代方式往外提供数据,该方法用于迭代器的方式为用户提供取消流销毁的选项。(16版以上新增) //类上的静态方法(16版以上新增) map(fn):返回<Readable>使用函数fn映射的流(promise) filter(fn):此方法允许过滤流,对于流中每个条目,都会调用fn函数,如果其返回真值,则该条目将被传给结果流。(可以实现promise) new Readable([options):实例化可读流。这里重点来关注options参数,该参数的属性可以用来定制流的具体操作: --highWaterMark:用于配置可读流中间缓存容量,默认16KB。 --encoding:用于配置缓存区中使用指定的编码解码为字符串,默认null。 --objectMode:是否表现为对象流,默认false。如果该配置为false,read(n)返回单个大小为n的Buffer。 --emitClose:被销毁后是否触发close事件,默认true。 --autoDestroy:是否在流操作结束后自动调用destroy()销毁流,默认为true。 --signal:表示可能取消的信号 //事件 close:当流及其任何底层资源已关闭时,触发该事件,意味者流操作结束。如果写入流基于emitClose创建的,则始终触发该事件。也就是当end事件触发后并且缓存区的数据全部读出后触发该事件。 data:当流将数据块移交给消费者时,则触发该事件。也就是当缓存区向外提供数据时通过触发该事件来实现。 end:当流中没有更多数据可供消费,则触发该事件。也就是当read()向缓存区写入null时触发该事件。 error:如果底层流内部故障无法生成数据时,或者当流尝试推送无效数据块时,可能触发该事件。 pause:通过pause()暂停流动模式时,触发该事件,任何可用数据都将保留在内部缓冲区。 readable:当有从流中读取的数据或以到达末尾时,触发该事件。也就是每次向中间缓存区缓存数据后触发该事件,缓存区没有数据触发该事件是为了实现read()向缓存区写入null来触发end事件,实现结束可读流操作。 resume:当调用resume()重启从中间缓存中向外提供数据时触发该事件
三、双工流与转换流
3.1双工流Duplex:
所谓双工流就是在一个流上同时实现可读流和可写流。
//双工流 const {Duplex} = require('stream'); let buf = Buffer.alloc(10,0,'utf-8');//开辟一个内存空间,作为双工流的底层数据存储设备 buf.write("abc");//初识化一些数据 class MyDuplex extends Duplex{ constructor(options){ super(options); this.buf = buf; this.offset = 3; //设置写入偏移到初识化数据的末尾处 this.readStart = 0; //初识化可读流的起始位置 this.readEnd = 1; //初识化可读流的结束位置 } _write(chunk, en, done){ process.nextTick(()=>{ this.buf.write(chunk.toString(),this.offset); this.offset += chunk.length; done(); }); } _read(){ let data = this.readStart > this.buf.length || this.readStart >= this.offset ? null : this.buf.subarray(this.readStart,this.readEnd); this.push(data,'utf-8'); this.readStart ++; this.readEnd ++; } }; let myDuplex = new MyDuplex(); //测试读数据 // myDuplex.on('data',(chunk)=>{ // console.log(chunk); // }); //测试写入再读数据 myDuplex.write("defghijk",()=>{ myDuplex.on('data',(chunk)=>{ console.log(chunk.toString()); }); });
双工流的特点就是sources、destination共用一个资源,虽然它底层依然管理两个中间缓存(读取流的中间缓存区、写入流的中间缓存区),但它不能两个操作同时进行,因为任意一个写入流还是读取流关闭后就不能重启,而且中途有写有读那就不是流模式了,违背了流源源不断的往一个方向传输数据的原则。所以双工流本质上就是实现读写流两个操作各消费一次,也就是说要么执行完读再执行写,要么执行完写再执行读。
最典型的双工流具体功能实现,在nodejs中就是TCP套字节socket的接收与响应数据操作,程序先将网络资源全部读出然后再将响应数据全部写入,
3.2转换流Transform:
转换流是在双工流的基础上实现的,基于先执行写入流,再执行读取流的方式,实现将写入的数据在内部做一些转换,再将转换过的数据通过读取流的data事件响应回来。
转换流不会单独执行数据读出,而是必须先执行写入操作,才会触发data事件将转换后的数据传输出来。
1 const {Transform} = require('stream'); 2 let buf = Buffer.alloc(10,0,'utf-8'); 3 class MyTransform extends Transform{ 4 constructor(options){ 5 super(options); 6 this.buf = buf; 7 this.offset = 0; //初识化写入流的ishi位置 8 } 9 _transform(chunk, en, cb){ 10 let str = chunk.toString().toUpperCase(); 11 process.nextTick(()=>{ 12 this.buf.write(str,this.offset); 13 this.offset += chunk.length; 14 }); 15 this.push(str); 16 cb(); 17 } 18 } 19 20 let myTransform = new MyTransform(); 21 myTransform.on('data',(chunk)=>{ 22 console.log(chunk.toString()); //ABCDEFG 23 }); 24 myTransform.write('abcdefg');
基于转换流,nodejs內置实现了压缩流(zlib)和加密流(crypto)。
四、背压机制与文件流模拟实现
4.1背压机制:
在很多业务中都有这样的需求,先从一个地方读出一些数据,然后再将这些数据写入到另一个地方,典型的操作就是文件拷贝。由于数据读取速度远远大于数据写入速度,这就可能导致读出到缓存中的数据超过设置缓存限制的最大值,从而造成内存溢出报错、垃圾回收器(GC)频繁调用、导致其他进程变慢,为了解决这种需求可能存在的潜在风险提出了一种解决方案,这个解决方案就是背压机制。
背压机制的原理:
基于流的I/O操作背压机制,在nodejs的实现中就是可读流的pipe(),其内部同时管理两个流模型:可读流、可写流,可读流的目的地(destination)是可写流的数据源(sources);可读流有自己的数据源(sources),可写流有自己的流目的地(destination)。在这两个流模型中都有自己独立的中间缓存区,当可读流的读取速度大于可写流的写入速度时,可读流会先将来不及写入目的地(destination)的数据缓存到可写流的中间缓存空间中,当可读流的中间缓存空间也写满以后就会通知可读流暂停向可写流提供数据,这时候可读流就会将自身从自己的数据源中读出的数据写到可读流自己的中间缓存空间中。
当可写流将自己中间缓存中的数据全部写入到自己的目的地以后,可写流又开始通知可读流向自己提供数据。如果这个过程中可读流自身的中间缓存空间都写满了,可读流还没等到可写流通知向它提供数据,这时候可读流会停止从自己的数据源中读取数据的操作,直到等到可写流通知向它提供数据,可读流将自身中间缓存中的数据读出传输给可写流,直到可读流将自身中间缓存中的数据全部清空然后,然后可读流再开始从自己的数据源中读取数据提供给可写流。
循环以上操作,直到数据传输完成,这就是流操作的背压机制。上面的描述看起会比较复杂,下面提供一个简单的流程图:
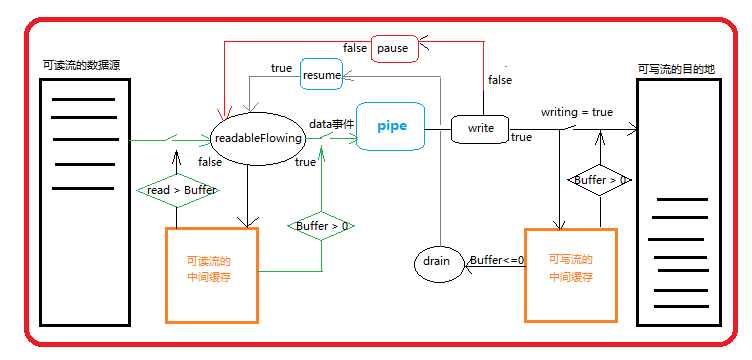
下面是基于EventEmitter和 fs.read/fs.write模拟实现的文件流源码:


1 //自定义文件读取流readFile.js 2 const fs = require('fs'); 3 const EventEmitter = require('events').EventEmitter; 4 const {Queue} = require('./linked.js'); 5 6 class MyFileReadStream extends EventEmitter { 7 constructor(path, optons={}){ 8 super(); 9 this.path = path; //绑定要读取的文件 10 this.flags = optons.flags || 'r'; //文件件操作模式:读取模式 11 this.mode = optons.mode || 438; //文件操作权限 12 this.autoClose = optons.autoClose || true; //是否关闭(销毁)当前文件 13 this.start = optons.start || 0; //开始读取的位置 14 this.end = optons.end; //结束读取的位置 15 this.highWaterMark = optons.highWaterMark || 64 * 1024; //可读流最大可缓存的字节数 16 17 this.readOffset = 0; //从什么位置读出 18 this.cache = new Queue(); //用于缓存数据的队列 19 this.readableFlowing = null; //当前流的状态:null(不提供数据状态)、true(持续输出数据)、false(暂停输出数据) 20 21 this.open(); 22 this.on('newListener',(type)=>{ //当在MyFileReadStream实例上添加监听事件时触发该事件,并将当前监听事件的名称传递给回调 23 if(type === 'data'){ 24 this.read(); 25 } 26 }); 27 } 28 open(){ 29 //原生open方法打开指定位置上的文件 30 fs.open(this.path, this.flags, this.mode, (err, fd)=>{ 31 if(err){ 32 this.emit('error', err); 33 } 34 this.fd = fd; 35 this.readableFlowing = true; //当文件正常打开时将流的状态置为持续数据数据的状态 36 this.emit('open',fd); 37 }); 38 } 39 read(){ 40 //负责将要读取的数据通过data事件输出 41 if(typeof this.fd !== 'number'){ 42 //当第一次触发事件 43 return this.once('open',this.read); //在通过open事件获取到文件标识符后,重新调用数据读取操作 44 } 45 if(!this.readableFlowing){ //当流处于暂停模式时,需要通过resume()重启流 46 return ; 47 } 48 if(this.cache.size > 0){ //如果可读流的中间缓存中有数据,就从中间缓存中拿数据通过data事件响应出去 49 this.emit("data",this.cache.deQueue()); 50 return this.read(); 51 } 52 //实现数据读取操作: 53 let buf = Buffer.alloc(this.highWaterMark); 54 let howMuchToRead ; 55 if(this.end){ 56 howMuchToRead = Math.min(this.end - this.readOffset + 1, this.highWaterMark); 57 }else{ 58 howMuchToRead = this.highWaterMark; 59 } 60 //调用原生文件读取方法fs.read获取数据 61 fs.read(this.fd, buf, 0, howMuchToRead, this.readOffset,(err,readBytes)=>{ 62 if(readBytes){ 63 this.readOffset += readBytes; 64 //这里需要判断是否通过data事件输出数据,还是将数据缓存到中间缓存中 65 if(this.readableFlowing){ 66 //当流处于数据持续输出状态,直接将数据通过data事件输出,并继续调用read()读取数据 67 this.emit('data',buf.slice(0,readBytes)); 68 this.read(); 69 }else{ 70 //当流处于数据暂停输出状态,将数据缓存到中间缓存(即缓存队列) 71 this.cache.enQueue(buf.slice(0,readBytes)); 72 } 73 }else{ 74 //当没有数据可读时触发end事件,并关闭文件标识符 75 this.emit('end'); 76 this.close(); 77 } 78 }); 79 } 80 close(){ 81 //关闭文件流操作 82 fs.close(this.fd,()=>{ 83 this.autoClose= false; //表示文件已被关闭 84 this.emit('close'); 85 }); 86 } 87 pause(){ 88 //暂停流操作 89 this.readableFlowing = false; 90 } 91 resume(){ 92 //重启流操作 93 this.readableFlowing = true; 94 this.read(); 95 } 96 pipe(ws){ 97 this.on('data',(data)=>{ 98 let flag = ws.write(data); 99 if(!flag){ 100 this.pause(); 101 } 102 }); 103 this.on("end",()=>{ 104 ws.end(); 105 }); 106 this.on("close",()=>{ 107 console.log("文件读取完成,正常关闭"); 108 }); 109 ws.on('drain',()=>{ 110 this.resume(); 111 }); 112 } 113 } 114 115 module.exports = MyFileReadStream;
1 //自定文件写入流writeFile.js 2 const fs = require('fs'); 3 const {EventEmitter} = require('events'); 4 const {Queue} = require('./linked.js'); 5 6 class MyFileWriteStream extends EventEmitter{ 7 constructor(path,options={}){ 8 super(); 9 this.path = path; 10 this.flags = options.flags || 'w'; 11 this.mode = options.mode || 438; 12 this.autoClose = options.autoClose || true; 13 this.start = options.start || 0; 14 this.encoding = options.encoding || 'utf8'; 15 this.highWaterMark = options.highWaterMark || 16*1024; 16 17 this.writeoffset = this.start; //从什么位置写入 18 this.writing = false; //是否正在写入 19 this.writLen = 0; //当前MyWriteStream实例要写入的字节长度,也就在当的写入操作中间缓存上有多少个字节的数据 20 this.needDrain = false; //中间缓存是否排空了,如果排空了就触发drain事件 21 this.cache = new Queue(); 22 this.upstream = false; //上游状态是否关闭。比如由上可读流通过pipe传输到当前可写流上的数据已经到达末尾,可读流读取的文件要关闭被打开的文件时,通过可写流的end()通知可写流它已经关闭 23 24 this.open(); 25 }; 26 open(){ 27 //原生fs.open 28 fs.open(this.path, this.flags, (err, fd)=>{ 29 if(err){ 30 this.emit('error', err); 31 } 32 //正常打开文件 33 this.fd = fd; 34 this.emit('open', fd); 35 }); 36 }; 37 //写入操作的对外接口 38 write(chunk, encoding, cb){ 39 if(chunk !== null){ 40 chunk = Buffer.isBuffer(chunk) ? chunk : Buffer.from(chunk); 41 this.writLen += chunk.length; //累计当前要写入的字节数(即表示写入流缓存中的数据字节长度) 42 let flag = this.writLen < this.highWaterMark; //检查缓存中的数据节点长度是否超出流的最大缓存空间。flag为tuer时表示缓存没有超出,反之则超出了 43 this.needDrain = !flag; 44 if(this.writing){ 45 //当前正在执行写入,即将内容缓存到队列 46 this.cache.enQueue({ 47 chunk:chunk, 48 encoding:encoding, 49 cb:cb 50 }); 51 }else{ 52 //当前不是正在写入,即立可以即执行写入操作 53 this._write(chunk,encoding,()=>{ 54 cb && cb(); //执行写入回调 55 //清空排队的内容 56 this._clearBuffer(); 57 }); 58 } 59 return flag; 60 }else{ 61 cb && cb(); 62 //清空排队的内容 63 this._clearBuffer(); 64 } 65 }; 66 //实现写入 67 _write(chunk, encoding, cb){ 68 this.writing = true; //将写入状态置为正在写入 69 if(typeof this.fd !== 'number'){ 70 //第一次写入时,writeFile 对象上没有fd,这事因为_write是同步任务,而this.fd获取文件描述符的逻辑在open()执行后的异步回调上 71 //在open()的异步回调任务中绑定this.fd以后会触发'open'事件,也就是说这个当'open'事件触发时就会fd了 72 //所以在第一次写入时在'open'事件上添加一个一次性的任务,在这个任务内真正的实现写入操作。 73 return this.once('open',()=>{ 74 this._write(chunk, encoding, cb); 75 }); 76 } 77 fs.write(this.fd, chunk, this.start, chunk.length, this.writeoffset,(err,writen)=>{ 78 this.writeoffset += writen; //将写入的字节数累计到写入位置上,为下一次写入提供写入位置定位 79 this.writLen -= writen; //将缓存字节数记录减掉写入的字节数 80 this.writing = false; 81 cb && cb(); 82 }); 83 }; 84 _clearBuffer(){ 85 let data = this.cache.deQueue(); 86 if(data){ 87 //当有数据时持续迭代链表节点中的缓存,从而实现将缓存中的数据写入到磁盘中 88 this._write(data.element.chunk, data.element.encoding, ()=>{ 89 data.element.cb && data.element.cb(); 90 this._clearBuffer(); 91 }); 92 }else{ 93 //当缓存中没有数据 94 if(this.upstream){ //当上游调用可写流的程序已经关闭,说明不会再有数据传入,这时候应该关闭当前的可写流 95 return this.close(); 96 } 97 if(this.needDrain){ 98 this.needDrain = false; 99 this.emit('drain'); 100 } 101 } 102 } 103 end(){ 104 this.write(null); 105 this.upstream = true; 106 } 107 close(){ 108 fs.close(this.fd,()=>{ 109 this.emit("close"); 110 console.log("文件写入完成,正常关闭") 111 }); 112 } 113 } 114 module.exports = MyFileWriteStream;
模拟流操作需要一个实现链表结构的基础队列模块,下面是具体实现源码:
1 //链表结构 2 //node节点 + head + null 3 //head头 -> null 4 //size链表长度 5 //next下一个节点 element 6 //增加、删除、修改、查询、清空 7 8 //构造节点 9 class Node{ 10 constructor(element, next){ 11 this.element = element; 12 this.next = next; 13 } 14 } 15 //构造链表 16 class LinkedList{ 17 constructor(head, size){ 18 this.head = null; 19 this.size = 0; 20 } 21 //获取指定节点 22 _getNode(index){ 23 if(index < 0 || index >= this.size){ 24 throw new Error('cross the border'); //抛出越界错误 25 } 26 let currentNode = this.head; 27 for(let i = 0; i < index; i++){ 28 currentNode = currentNode.next; 29 } 30 return currentNode; 31 } 32 //添加节点:可以在指定的位置添加(即插入节点:传入索引+节点元素两个参数),如果只传入节点元素就默认在链表的末尾添加节点 33 add(index, element){ 34 if(arguments.length === 1){ 35 element = index; 36 index = this.size; //当没有传入插入位置时,将插入位置默认未链表的末尾 37 } 38 if(index < 0 || index > this.size){ 39 throw new Error('cross the border'); //抛出越界错误 40 } 41 if(index === 0){ 42 let head = this.head; 43 this.head = new Node(element,head); 44 }else{ 45 let prevNode = this._getNode(index -1); 46 prevNode.next = new Node(element,prevNode.next); 47 } 48 this.size++; 49 } 50 //删除节点 51 remove(index){ 52 let rmNode = null; //删除的节点 53 if(index === 0){ 54 rmNode = this.head; 55 if(!rmNode){ 56 return undefined; 57 } 58 this.head = rmNode.next; 59 }else{ 60 let prevNode = this._getNode(index-1); 61 rmNode = prevNode.next; 62 prevNode.next = prevNode.next.next; 63 } 64 this.size --; 65 return rmNode; 66 } 67 //修改链表节点 68 set(index,element){ 69 let node = this._getNode(index); 70 node.element = element; 71 } 72 //查询链表节点 73 get(index){ 74 return this._getNode(index); 75 } 76 //清空链表 77 clear(){ 78 this.head = null; 79 this.size = 0; 80 } 81 } 82 83 //构造链表队列 84 class Queue{ 85 constructor(){ 86 this.linkedList = new LinkedList(); 87 } 88 //入队列 89 enQueue(data){ 90 this.linkedList.add(data); 91 } 92 //出队列 93 deQueue(){ 94 return this.linkedList.remove(0); 95 } 96 } 97 98 module.exports = { 99 Node:Node, 100 LinkedList:LinkedList, 101 Queue:Queue 102 };
最后测试代码:
1 const fs = require('fs'); 2 const myFileReadStream = require('./readFile.js'); 3 const myWriteStream = require('./writeFile.js'); 4 5 // const rs = fs.createReadStream('./笔记(副本).txt',{ 6 // highWaterMark:4 7 // }); 8 // const rs = fs.createReadStream('./tst.txt',{ 9 // highWaterMark:1 10 // }); 11 const rs = new myFileReadStream('./笔记(副本).txt',{ 12 highWaterMark:4 13 }); 14 15 // const ws = fs.createWriteStream('./笔记.txt',{ 16 // highWaterMark:12 17 // }); 18 const ws = new myWriteStream('./笔记.txt',{ 19 highWaterMark:12 20 }); 21 rs.pipe(ws);
测试的txt文件可以自己修改,
自定义实现的可读流和可写流可以与node原生的文件流API实现交互,
可以基于注释的测试代码测试:
比如使用fs的createReadStream与自定义的可写流模块实现文件流操作
也可以使用fs的createWriteStream与自定义的可读流模块实现文件流操作