简介
druid是用于创建和管理连接,利用“池”的方式复用连接减少资源开销,和其他数据源一样,也具有连接数控制、连接可靠性测试、连接泄露控制、缓存语句等功能,另外,druid还扩展了监控统计、防御SQL注入等功能。
本文将包含以下内容(因为篇幅较长,可根据需要选择阅读):
druid的使用方法(入门案例、JDNI使用、监控统计、防御SQL注入)druid的配置参数详解druid主要源码分析
其他连接池的内容也可以参考我的其他博客:
源码详解系列(四) ------ DBCP2的使用和分析(包括JNDI和JTA支持)
源码详解系列(五) ------ C3P0的使用和分析(包括JNDI)
使用例子-入门
需求
使用druid连接池获取连接对象,对用户数据进行简单的增删改查(sql脚本项目中已提供)。
工程环境
JDK:1.8.0_231
maven:3.6.1
IDE:eclipse 4.12
mysql-connector-java:8.0.15
mysql:5.7 .28
druid:1.1.20
主要步骤
-
编写
druid.properties,设置数据库连接参数和连接池基本参数等 -
通过
DruidDataSourceFactory加载druid.properties文件,并创建DruidDataSource对象 -
通过
DruidDataSource对象获得Connection对象 -
使用
Connection对象对用户表进行增删改查
创建项目
项目类型Maven Project,打包方式war(其实jar也可以,之所以使用war是为了测试JNDI)。
引入依赖
这里引入日志包,主要为了看看连接池的创建过程,不引入不会有影响的。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.20</version>
</dependency>
<!-- mysql驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<!-- log -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
编写druid.properties
配置文件路径在resources目录下,因为是入门例子,这里仅给出数据库连接参数和连接池基本参数,后面会对所有配置参数进行详细说明。另外,数据库sql脚本也在该目录下。
当然,我们也可以通过启动参数来进行配置(但这种方式可配置参数会少一些)。
#-------------基本属性--------------------------------
url=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#数据源名,当配置多数据源时可以用于区分。注意,1.0.5版本及更早版本不支持配置该项
#默认"DataSource-" + System.identityHashCode(this)
name=zzs001
#如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName
driverClassName=com.mysql.cj.jdbc.Driver
#-------------连接池大小相关参数--------------------------------
#初始化时建立物理连接的个数
#默认为0
initialSize=0
#最大连接池数量
#默认为8
maxActive=8
#最小空闲连接数量
#默认为0
minIdle=0
#已过期
#maxIdle
#获取连接时最大等待时间,单位毫秒。
#配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
#默认-1,表示无限等待
maxWait=-1
获取连接池和获取连接
项目中编写了JDBCUtil来初始化连接池、获取连接、管理事务和释放资源等,具体参见项目源码。
路径:cn.zzs.druid
Properties properties = new Properties();
InputStream in = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties");
properties.load(in);
DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);
编写测试类
这里以保存用户为例,路径在test目录下的cn.zzs.druid。
@Test
public void save() throws SQLException {
// 创建sql
String sql = "insert into demo_user values(null,?,?,?,?,?)";
Connection connection = null;
PreparedStatement statement = null;
try {
// 获得连接
connection = JDBCUtils.getConnection();
// 开启事务设置非自动提交
connection.setAutoCommit(false);
// 获得Statement对象
statement = connection.prepareStatement(sql);
// 设置参数
statement.setString(1, "zzf003");
statement.setInt(2, 18);
statement.setDate(3, new Date(System.currentTimeMillis()));
statement.setDate(4, new Date(System.currentTimeMillis()));
statement.setBoolean(5, false);
// 执行
statement.executeUpdate();
// 提交事务
connection.commit();
} finally {
// 释放资源
JDBCUtils.release(connection, statement, null);
}
}
使用例子-通过JNDI获取数据源
需求
本文测试使用JNDI获取DruidDataSource对象,选择使用tomcat 9.0.21作容器。
如果之前没有接触过JNDI,并不会影响下面例子的理解,其实可以理解为像spring的bean配置和获取。
引入依赖
本文在入门例子的基础上增加以下依赖,因为是web项目,所以打包方式为war:
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.servlet.jsp</groupId>
<artifactId>javax.servlet.jsp-api</artifactId>
<version>2.2.1</version>
<scope>provided</scope>
</dependency>
编写context.xml
在webapp文件下创建目录META-INF,并创建context.xml文件。这里面的每个resource节点都是我们配置的对象,类似于spring的bean节点。其中jdbc/druid-test可以看成是这个bean的id。
注意,这里获取的数据源对象是单例的,如果希望多例,可以设置singleton="false"。
<?xml version="1.0" encoding="UTF-8"?>
<Context>
<Resource
name="jdbc/druid-test"
factory="com.alibaba.druid.pool.DruidDataSourceFactory"
auth="Container"
type="javax.sql.DataSource"
maxActive="15"
initialSize="3"
minIdle="3"
maxWait="10000"
url="jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true"
username="root"
password="root"
filters="mergeStat,log4j"
validationQuery="select 1 from dual"
/>
</Context>
编写web.xml
在web-app节点下配置资源引用,每个resource-ref指向了我们配置好的对象。
<!-- JNDI数据源 -->
<resource-ref>
<res-ref-name>jdbc/druid-test</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
编写jsp
因为需要在web环境中使用,如果直接建类写个main方法测试,会一直报错的,目前没找到好的办法。这里就简单地使用jsp来测试吧。
druid提供了DruidDataSourceFactory来支持JNDI。
<body>
<%
String jndiName = "java:comp/env/jdbc/druid-test";
InitialContext ic = new InitialContext();
// 获取JNDI上的ComboPooledDataSource
DataSource ds = (DataSource) ic.lookup(jndiName);
JDBCUtils.setDataSource(ds);
// 创建sql
String sql = "select * from demo_user where deleted = false";
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
// 查询用户
try {
// 获得连接
connection = JDBCUtils.getConnection();
// 获得Statement对象
statement = connection.prepareStatement(sql);
// 执行
resultSet = statement.executeQuery();
// 遍历结果集
while(resultSet.next()) {
String name = resultSet.getString(2);
int age = resultSet.getInt(3);
System.err.println("用户名:" + name + ",年龄:" + age);
}
} catch(SQLException e) {
System.err.println("查询用户异常");
} finally {
// 释放资源
JDBCUtils.release(connection, statement, resultSet);
}
%>
</body>
测试结果
打包项目在tomcat9上运行,访问 http://localhost:8080/druid-demo/testJNDI.jsp ,控制台打印如下内容:
用户名:zzs001,年龄:18
用户名:zzs002,年龄:18
用户名:zzs003,年龄:25
用户名:zzf001,年龄:26
用户名:zzf002,年龄:17
用户名:zzf003,年龄:18
使用例子-开启监控统计
在以上例子基础上修改。
配置StatFilter
打开监控统计功能
druid的监控统计功能是通过filter-chain扩展实现,如果你要打开监控统计功能,配置StatFilter,如下:
filters=stat
stat是com.alibaba.druid.filter.stat.StatFilter的别名,别名映射配置信息保存在druid-xxx.jar!/META-INF/druid-filter.properties。
SQL合并配置
当你程序中存在没有参数化的sql执行时,sql统计的效果会不好。比如:
select * from t where id = 1
select * from t where id = 2
select * from t where id = 3
在统计中,显示为3条sql,这不是我们希望要的效果。StatFilter提供合并的功能,能够将这3个SQL合并为如下的SQL:
select * from t where id = ?
可以配置StatFilter的mergeSql属性来解决:
#用于设置filter的属性
#多个参数用";"隔开
connectionProperties=druid.stat.mergeSql=true
StatFilter支持一种简化配置方式,和上面的配置等同的。如下:
filters=mergeStat
mergeStat是的MergeStatFilter缩写,我们看MergeStatFilter的实现:
public class MergeStatFilter extends StatFilter {
public MergeStatFilter() {
super.setMergeSql(true);
}
}
从实现代码来看,仅仅是一个mergeSql的缺省值。
慢SQL记录
StatFilter属性slowSqlMillis用来配置SQL慢的标准,执行时间超过slowSqlMillis的就是慢。slowSqlMillis的缺省值为3000,也就是3秒。
connectionProperties=druid.stat.logSlowSql=true;druid.stat.slowSqlMillis=5000
在上面的配置中,slowSqlMillis被修改为5秒,并且通过日志输出执行慢的SQL。
合并多个DruidDataSource的监控数据
缺省多个DruidDataSource的监控数据是各自独立的,在druid-0.2.17版本之后,支持配置公用监控数据,配置参数为useGlobalDataSourceStat。例如:
connectionProperties=druid.useGlobalDataSourceStat=true
配置StatViewServlet
druid内置提供了一个StatViewServlet用于展示Druid的统计信息。
这个StatViewServlet的用途包括:
- 提供监控信息展示的html页面
- 提供监控信息的JSON API
注意:使用StatViewServlet,建议使用druid 0.2.6以上版本。
配置web.xml
StatViewServlet是一个标准的javax.servlet.http.HttpServlet,需要配置在你web应用中的WEB-INF/web.xml中。
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
根据配置中的url-pattern来访问内置监控页面,如果是上面的配置,内置监控页面的首页是/druid/index.html
例如:
http://localhost:8080/druid-demo/druid/index.html
配置监控页面访问密码
需要配置Servlet的 loginUsername 和 loginPassword这两个初始参数。
示例如下:
<!-- 配置 Druid 监控信息显示页面 -->
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<!-- 允许清空统计数据 -->
<param-name>resetEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 用户名 -->
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<!-- 密码 -->
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
配置allow和deny
StatViewSerlvet展示出来的监控信息比较敏感,是系统运行的内部情况,如果你需要做访问控制,可以配置allow和deny这两个参数。比如:
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<param-name>allow</param-name>
<param-value>128.242.127.1/24,128.242.128.1</param-value>
</init-param>
<init-param>
<param-name>deny</param-name>
<param-value>128.242.127.4</param-value>
</init-param>
</servlet>
判断规则:
deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。- 如果
allow没有配置或者为空,则允许所有访问
配置resetEnable
在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,会导致所有计数器清零,重新计数。你可以通过配置参数关闭它。
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<init-param>
<param-name>resetEnable</param-name>
<param-value>false</param-value>
</init-param>
</servlet>
配置WebStatFilter
WebStatFilter用于采集web-jdbc关联监控的数据。经常需要排除一些不必要的url,比如.js,/jslib/等等。配置在init-param中。比如:
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
测试
启动程度,访问http://localhost:8080/druid-demo/druid/index.html,登录后可见以下页面,通过该页面我们可以查看数据源配置参数、进行SQL统计和监控,等等:
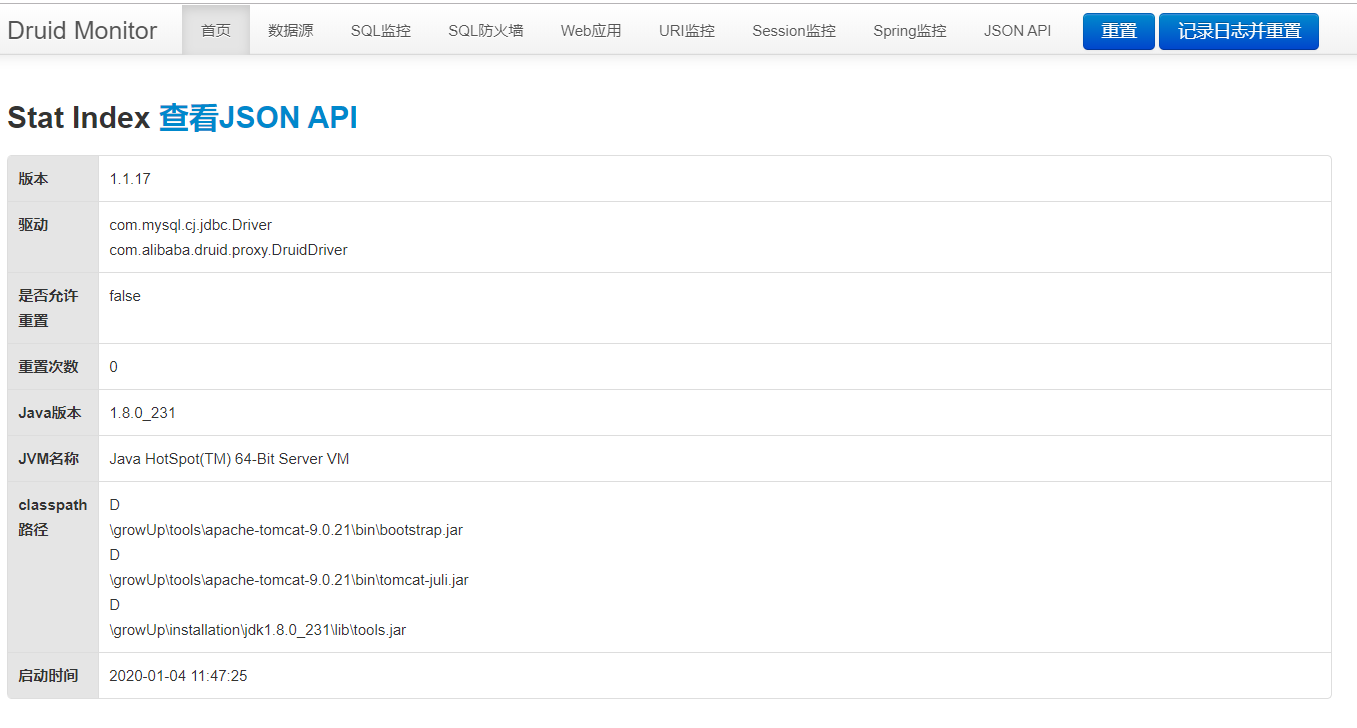
使用例子-防御SQL注入
开启WallFilter
WallFilter用于对SQL进行拦截,通过以下配置开启:
#过滤器
filters=wall,stat
注意,这种配置拦截检测的时间不在StatFilter统计的SQL执行时间内。 如果希望StatFilter统计的SQL执行时间内,则使用如下配置
#过滤器
filters=stat,wall
WallConfig详细说明
WallFilter常用参数如下,可以通过connectionProperties属性进行配置:
| 参数 | 缺省值 | 描述 |
|---|---|---|
| wall.logViolation | false | 对被认为是攻击的SQL进行LOG.error输出 |
| wall.throwException | true | 对被认为是攻击的SQL抛出SQLException |
| wall.updateAllow | true | 是否允许执行UPDATE语句 |
| wall.deleteAllow | true | 是否允许执行DELETE语句 |
| wall.insertAllow | true | 是否允许执行INSERT语句 |
| wall.selelctAllow | true | 否允许执行SELECT语句 |
| wall.multiStatementAllow | false | 是否允许一次执行多条语句,缺省关闭 |
| wall.selectLimit | -1 | 配置最大返回行数,如果select语句没有指定最大返回行数,会自动修改selct添加返回限制 |
| wall.updateWhereNoneCheck | false | 检查UPDATE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险 |
| wall.deleteWhereNoneCheck | false | 检查DELETE语句是否无where条件,这是有风险的,但不是SQL注入类型的风险 |
使用例子-日志记录JDBC执行的SQL
开启日志记录
druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。这些Filter都是Filter-Chain扩展机制中的Filter,所以配置方式可以参考这里:
#过滤器
filters=log4j
在druid-xxx.jar!/META-INF/druid-filter.properties文件中描述了这四种Filter的别名:
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter
druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter
druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter
druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter
druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter
他们的别名分别是log4j、log4j2、slf4j、commonlogging和commonLogging。其中commonlogging和commonLogging只是大小写不同。
配置输出日志
缺省输入的日志信息全面,但是内容比较多,有时候我们需要定制化配置日志输出。
connectionProperties=druid.log.rs=false
相关参数如下,更多参数请参考com.alibaba.druid.filter.logging.LogFilter:
| 参数 | 说明 | properties参数 |
|---|---|---|
| connectionLogEnabled | 所有连接相关的日志 | druid.log.conn |
| statementLogEnabled | 所有Statement相关的日志 | druid.log.stmt |
| resultSetLogEnabled | 所有ResultSe相关的日志 | druid.log.rs |
| statementExecutableSqlLogEnable | 所有Statement执行语句相关的日志 | druid.log.stmt.executableSql |
log4j.properties配置
如果你使用log4j,可以通过log4j.properties文件配置日志输出选项,例如:
log4j.logger.druid.sql=warn,stdout
log4j.logger.druid.sql.DataSource=warn,stdout
log4j.logger.druid.sql.Connection=warn,stdout
log4j.logger.druid.sql.Statement=warn,stdout
log4j.logger.druid.sql.ResultSet=warn,stdout
输出可执行的SQL
参数配置方式
connectionProperties=druid.log.stmt.executableSql=true
配置文件详解
配置druid的参数的n种方式
使用druid,同一个参数,我们可以采用多种方式进行配置,举个例子:maxActive(最大连接池参数)的配置:
方式一(系统属性)
系统属性一般在启动参数中设置。通过方式一来配置连接池参数的还是比较少见。
-Ddruid.maxActive=8
方式二(properties)
这是最常见的一种。
maxActive=8
方式三(properties加前缀)
相比第二种方式,这里只是加了.druid前缀。
druid.maxActive=8
方式四(properties的connectionProperties)
connectionProperties可以用于配置多个属性,不同属性使用";"隔开。
connectionProperties=druid.maxActive=8
方式五(connectProperties)
connectProperties可以在方式一、方式三和方式四中存在,具体配置如下:
# 方式一
-Ddruid.connectProperties=druid.maxActive=8
# 方式三:支持多个属性,不同属性使用";"隔开
druid.connectProperties=druid.maxActive=8
# 方式四
connectionProperties=druid.connectProperties=druid.maxActive=8
这个属性甚至可以这样配(当然应该没人会这么做):
druid.connectProperties=druid.connectProperties=druid.connectProperties=druid.connectProperties=druid.maxActive=8
真的是没完没了,怎么会引入connectProperties这个属性呢?我觉得这是一个十分失败的设计,所以本文仅会讲前面说的四种。
关于druid参数配置的吐槽
前面已经讲到,同一个参数,我们有时可以采用无数种方式来配置。表面上看这样设计十分人性化,可以适应不同人群的使用习惯,但是,在我看来,这样设计非常不利于配置的统一管理,另外,druid的参数配置还存在另一个问题,先看下这个表格(这里包含了druid所有的参数,使用时可以参考):
| 参数分类 | 参数 | 方式一 | 方式二 | 方式三 | 方式四 |
|---|---|---|---|---|---|
| 基本属性 | driverClassName | O | O | O | O |
| password | O | O | O | O | |
| url | O | O | O | O | |
| username | O | O | O | O | |
| 事务相关 | defaultAutoCommit | X | O | X | X |
| defaultReadOnly | X | O | X | X | |
| defaultTransactionIsolation | X | O | X | X | |
| defaultCatalog | X | O | X | X | |
| 连接池大小 | maxActive | O | O | O | O |
| maxIdle | X | O | X | X | |
| minIdle | O | O | O | O | |
| initialSize | O | O | O | O | |
| maxWait | O | O | O | O | |
| 连接检测 | testOnBorrow | O | O | O | O |
| testOnReturn | X | O | X | X | |
| timeBetweenEvictionRunsMillis | O | O | O | O | |
| numTestsPerEvictionRun | X | O | X | X | |
| minEvictableIdleTimeMillis | O | O | O | O | |
| maxEvictableIdleTimeMillis | O | X | O | O | |
| phyTimeoutMillis | O | O | O | O | |
| testWhileIdle | O | O | O | O | |
| validationQuery | O | O | O | O | |
| validationQueryTimeout | X | O | X | X | |
| 连接泄露回收 | removeAbandoned | X | O | X | X |
| removeAbandonedTimeout | X | O | X | X | |
| logAbandoned | X | O | X | X | |
| 缓存语句 | poolPreparedStatements | O | O | O | O |
| maxOpenPreparedStatements | X | O | X | X | |
| maxPoolPreparedStatementPerConnectionSize | O | X | O | O | |
| 其他 | initConnectionSqls | O | O | O | O |
| init | X | O | X | X | |
| asyncInit | O | X | O | O | |
| initVariants | O | X | O | O | |
| initGlobalVariants | O | X | O | O | |
| accessToUnderlyingConnectionAllowed | X | O | X | X | |
| exceptionSorter | X | O | X | X | |
| exception-sorter-class-name | X | O | X | X | |
| name | O | X | O | O | |
| notFullTimeoutRetryCount | O | X | O | O | |
| maxWaitThreadCount | O | X | O | O | |
| failFast | O | X | O | O | |
| phyMaxUseCount | O | X | O | O | |
| keepAlive | O | X | O | O | |
| keepAliveBetweenTimeMillis | O | X | O | O | |
| useUnfairLock | O | X | O | O | |
| killWhenSocketReadTimeout | O | X | O | O | |
| load.spifilter.skip | O | X | O | O | |
| cacheServerConfiguration | X | X | X | O | |
| 过滤器 | filters | O | O | O | O |
| clearFiltersEnable | O | X | O | O | |
| log.conn | O | X | X | O | |
| log.stmt | O | X | X | O | |
| log.rs | O | X | X | O | |
| log.stmt.executableSql | O | X | X | O | |
| timeBetweenLogStatsMillis | O | X | O | O | |
| useGlobalDataSourceStat/useGloalDataSourceStat | O | X | O | O | |
| resetStatEnable | O | X | O | O | |
| stat.sql.MaxSize | O | X | O | O | |
| stat.mergeSql | O | X | X | O | |
| stat.slowSqlMillis | O | X | X | O | |
| stat.logSlowSql | O | X | X | O | |
| stat.loggerName | X | X | X | O | |
| wall.logViolation | O | X | X | O | |
| wall.throwException | O | X | X | O | |
| wall.tenantColumn | O | X | X | O | |
| wall.updateAllow | O | X | X | O | |
| wall.deleteAllow | O | X | X | O | |
| wall.insertAllow | O | X | X | O | |
| wall.selelctAllow | O | X | X | O | |
| wall.multiStatementAllow | O | X | X | O | |
| wall.selectLimit | O | X | X | O | |
| wall.updateCheckColumns | O | X | X | O | |
| wall.updateWhereNoneCheck | O | X | X | O | |
| wall.deleteWhereNoneCheck | O | X | X | O |
一般我们都希望采用一种方式来统一配置这些参数,但是,通过以上表格可知,druid并不存在哪一种方式能配置所有参数,也就是说,你不得不采用两种或两种以上的配置方式。所以,我认为,至少在配置方式这一点上,druid是非常失败的!
通过表格可知,方式二和方式四结合使用,可以覆盖所有参数,所以,本文采用的配置策略为:优先采用方式二配置,配不了再选用方式四。
数据库连接参数
注意,这里在url后面拼接了多个参数用于避免乱码、时区报错问题。 补充下,如果不想加入时区的参数,可以在mysql命令窗口执行如下命令:set global time_zone='+8:00'。
#-------------基本属性--------------------------------
url=jdbc:mysql://localhost:3306/github_demo?useUnicode=true&characterEncoding=utf8&serverTimezone=GMT%2B8&useSSL=true
username=root
password=root
#数据源名,当配置多数据源时可以用于区分。注意,1.0.5版本及更早版本不支持配置该项
#默认"DataSource-" + System.identityHashCode(this)
name=zzs001
#如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName
driverClassName=com.mysql.cj.jdbc.Driver
连接池数据基本参数
这几个参数都比较常用,具体设置多少需根据项目调整。
#-------------连接池大小相关参数--------------------------------
#初始化时建立物理连接的个数
#默认为0
initialSize=0
#最大连接池数量
#默认为8
maxActive=8
#最小空闲连接数量
#默认为0
minIdle=0
#已过期
#maxIdle
#获取连接时最大等待时间,单位毫秒。
#配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。
#默认-1,表示无限等待
maxWait=-1
连接检查参数
针对连接失效的问题,建议开启空闲连接测试,而不建议开启借出测试(从性能考虑),另外,开启连接测试时,必须配置validationQuery。
#-------------连接检测情况--------------------------------
#用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。
#如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
#默认为空
validationQuery=select 1 from dual
#检测连接是否有效的超时时间,单位:秒。
#底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法
#默认-1
validationQueryTimeout=-1
#申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
#默认为false
testOnBorrow=false
#归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。
#默认为false
testOnReturn=false
#申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。
#建议配置为true,不影响性能,并且保证安全性。
#默认为true
testWhileIdle=true
#有两个含义:
#1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。
#2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明
#默认1000*60
timeBetweenEvictionRunsMillis=-1
#不再使用,一个DruidDataSource只支持一个EvictionRun
#numTestsPerEvictionRun=3
#连接保持空闲而不被驱逐的最小时间。
#默认值1000*60*30 = 30分钟
minEvictableIdleTimeMillis=1800000
缓存语句
针对大部分数据库而言,开启缓存语句可以有效提高性能,但是在myslq下建议关闭。
#-------------缓存语句--------------------------------
#是否缓存preparedStatement,也就是PSCache。
#PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭
#默认为false
poolPreparedStatements=false
#PSCache的最大个数。
#要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。
#在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100
#默认为10
maxOpenPreparedStatements=10
事务相关参数
建议保留默认就行。
#-------------事务相关的属性--------------------------------
#连接池创建的连接的默认的auto-commit状态
#默认为空,由驱动决定
defaultAutoCommit=true
#连接池创建的连接的默认的read-only状态。
#默认值为空,由驱动决定
defaultReadOnly=false
#连接池创建的连接的默认的TransactionIsolation状态
#可用值为下列之一:NONE,READ_UNCOMMITTED, READ_COMMITTED, REPEATABLE_READ, SERIALIZABLE
#默认值为空,由驱动决定
defaultTransactionIsolation=REPEATABLE_READ
#连接池创建的连接的默认的数据库名
defaultCatalog=github_demo
连接泄漏回收参数
#-------------连接泄漏回收参数--------------------------------
#当未使用的时间超过removeAbandonedTimeout时,是否视该连接为泄露连接并删除
#默认为false
removeAbandoned=false
#泄露的连接可以被删除的超时值, 单位毫秒
#默认为300*1000
removeAbandonedTimeoutMillis=300*1000
#标记当Statement或连接被泄露时是否打印程序的stack traces日志。
#默认为false
logAbandoned=true
#连接最大存活时间
#默认-1
#phyTimeoutMillis=-1
过滤器
#-------------过滤器--------------------------------
#属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有:
#别名映射配置信息保存在druid-xxx.jar!/META-INF/druid-filter.properties
#监控统计用的filter:stat(mergeStat可以合并sql)
#日志用的filter:log4j
#防御sql注入的filter:wall
filters=log4j,wall,mergeStat
#用于设置filter、exceptionSorter、validConnectionChecker等的属性
#多个参数用";"隔开
connectionProperties=druid.useGlobalDataSourceStat=true;druid.stat.logSlowSql=true;druid.stat.slowSqlMillis=5000
其他
#-------------其他--------------------------------
#控制PoolGuard是否容许获取底层连接
#默认为false
accessToUnderlyingConnectionAllowed=false
#当数据库抛出一些不可恢复的异常时,抛弃连接
#根据dbType自动识别
#exceptionSorter
#exception-sorter-class-name=
#物理连接初始化的时候执行的sql
#initConnectionSqls=
#是否创建数据源时就初始化连接池
init=true
源码分析
看过druid的源码就会发现,相比其他DBCP和C3P0,druid有以下特点:
- 更多地引入了JDK的特性,特别是concurrent包的工具。例如,
CountDownLatch、ReentrantLock、AtomicLongFieldUpdater、Condition等,也就是说,在分析druid源码之前,最好先学习下这些技术; - 在类的设计上一切从简。例如,DBCP和C3P0都有一个池的类,而druid并没有,只用了一个简单的数组,且druid的核心逻辑几乎都堆积在
DruidDataSource里面。另外,在对类或接口的抽象上,个人感觉,druid不是很“面向对象”,有的接口或类的方法很难统一成某种对象的行为,所以,本文不会去关注类的设计,更多地将分析一些重要功能的实现。
注意:考虑篇幅和可读性,以下代码经过删减,仅保留所需部分。
配置参数的加载
前面已经讲过,druid为我们提供了“无数”种方式来配置参数,这里我再补充下不同配置方式的加载顺序(当然,只会涉及到四种方式)。
当我们使用调用DruidDataSourceFactory.createDataSource(Properties)时,会加载配置来给对应的属性赋值,另外,这个过程还会根据配置去创建对应的过滤器。不同配置方式加载时机不同,后者会覆盖已存在的相同参数,如图所示。
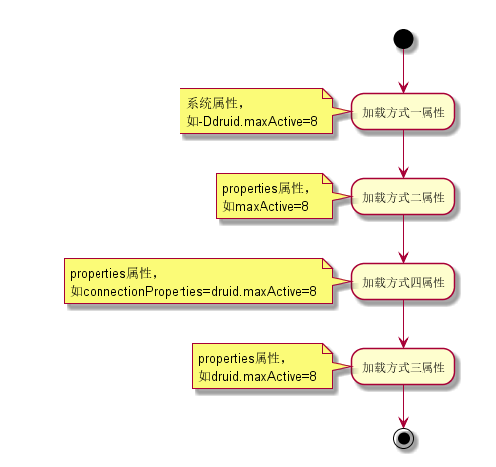
数据源的初始化
了解下DruidDataSource这个类
这里先来介绍下DruidDataSource这个类:
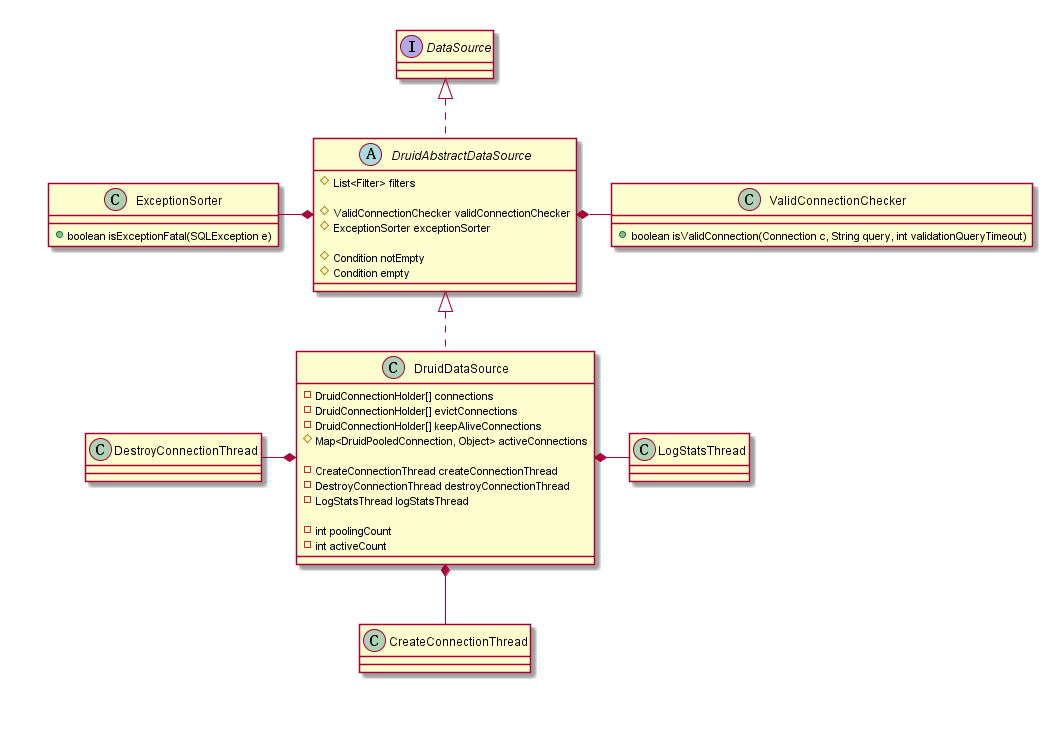
图中我只列出了几个重要的属性,这几个属性没有理解好,后面的源码很难看得进去。
| 类名 | 描述 |
|---|---|
| ExceptionSorter | 用于判断SQLException对象是否致命异常 |
| ValidConnectionChecker | 用于校验指定连接对象是否有效 |
| CreateConnectionThread | DruidDataSource的内部类,用于异步创建连接对象 |
| notEmpty | 调用notEmpty.await()时,当前线程进入等待;当连接创建完成或者回收了连接,会调用notEmpty.signal()时,将等待线程唤醒; |
| empty | 调用empty.await()时,CreateConnectionThread进入等待;调用empty.signal()时,CreateConnectionThread被唤醒,并进入创建连接; |
| DestroyConnectionThread | DruidDataSource的内部类,用于异步检验连接对象,包括校验空闲连接的phyTimeoutMillis、minEvictableIdleTimeMillis,以及校验借出连接的removeAbandonedTimeoutMillis |
| LogStatsThread | DruidDataSource的内部类,用于异步记录统计信息 |
| connections | 用于存放所有连接对象 |
| evictConnections | 用于存放需要丢弃的连接对象 |
| keepAliveConnections | 用于存放需要keepAlive的连接对象 |
| activeConnections | 用于存放需要进行removeAbandoned的连接对象 |
| poolingCount | 空闲连接对象的数量 |
| activeCount | 借出连接对象的数量 |
概括下初始化的过程
DruidDataSource的初始化时机是可选的,当我们设置init=true时,在createDataSource时就会调用DataSource.init()方法进行初始化,否则,只会在getConnection时再进行初始化。数据源初始化主要逻辑在DataSource.init()这个方法,可以概括为以下步骤:
- 加锁
- 初始化
initStackTrace、id、xxIdSeed、dbTyp、driver、dataSourceStat、connections、evictConnections、keepAliveConnections等属性 - 初始化过滤器
- 校验
maxActive、minIdle、initialSize、timeBetweenLogStatsMillis、useGlobalDataSourceStat、maxEvictableIdleTimeMillis、minEvictableIdleTimeMillis、validationQuery等配置是否合法 - 初始化
ExceptionSorter、ValidConnectionChecker、JdbcDataSourceStat - 创建
initialSize数量的连接 - 创建
logStatsThread、createConnectionThread和destroyConnectionThread - 等待
createConnectionThread和destroyConnectionThread线程run后再继续执行 - 注册
MBean,用于支持JMX - 如果设置了
keepAlive,通知createConnectionThread创建连接对象 - 解锁
这个方法差不多200行,考虑篇幅,我删减了部分内容。
加锁和解锁
druid数据源初始化采用的是ReentrantLock,如下:
final ReentrantLock lock = this.lock;
try {
// 加锁
lock.lockInterruptibly();
} catch (InterruptedException e) {
throw new SQLException("interrupt", e);
}
boolean init = false;
try {
// do something
} finally {
inited = true;
// 解锁
lock.unlock();
}
注意,以下步骤均在这个锁的范围内。
初始化属性
这部分内容主要是初始化一些属性,需要注意的一点就是,这里使用了AtomicLongFieldUpdater来进行原子更新,保证写的安全和读的高效,当然,还是cocurrent包的工具。
// 这里使用了AtomicLongFieldUpdater来进行原子更新,保证了写的安全和读的高效
this.id = DruidDriver.createDataSourceId();
if (this.id > 1) {
long delta = (this.id - 1) * 100000;
this.connectionIdSeedUpdater.addAndGet(this, delta);
this.statementIdSeedUpdater.addAndGet(this, delta);
this.resultSetIdSeedUpdater.addAndGet(this, delta);
this.transactionIdSeedUpdater.addAndGet(this, delta);
}
// 设置url
if (this.jdbcUrl != null) {
this.jdbcUrl = this.jdbcUrl.trim();
// 针对druid自定义的一种url格式,进行解析
// jdbc:wrap-jdbc:开头,可设置driver、name、jmx等
initFromWrapDriverUrl();
}
// 根据url前缀,确定dbType
if (this.dbType == null || this.dbType.length() == 0) {
this.dbType = JdbcUtils.getDbType(jdbcUrl, null);
}
// cacheServerConfiguration,暂时不知道这个参数干嘛用的
if (JdbcConstants.MYSQL.equals(this.dbType)
|| JdbcConstants.MARIADB.equals(this.dbType)
|| JdbcConstants.ALIYUN_ADS.equals(this.dbType)) {
boolean cacheServerConfigurationSet = false;
if (this.connectProperties.containsKey("cacheServerConfiguration")) {
cacheServerConfigurationSet = true;
} else if (this.jdbcUrl.indexOf("cacheServerConfiguration") != -1) {
cacheServerConfigurationSet = true;
}
if (cacheServerConfigurationSet) {
this.connectProperties.put("cacheServerConfiguration", "true");
}
}
// 设置驱动类
if (this.driverClass != null) {
this.driverClass = driverClass.trim();
}
// 如果我们没有配置driverClass
if (this.driver == null) {
// 根据url识别对应的driverClass
if (this.driverClass == null || this.driverClass.isEmpty()) {
this.driverClass = JdbcUtils.getDriverClassName(this.jdbcUrl);
}
// MockDriver的情况,这里不讨论
if (MockDriver.class.getName().equals(driverClass)) {
driver = MockDriver.instance;
} else {
if (jdbcUrl == null && (driverClass == null || driverClass.length() == 0)) {
throw new SQLException("url not set");
}
// 创建Driver实例,注意,这个过程不需要依赖DriverManager
driver = JdbcUtils.createDriver(driverClassLoader, driverClass);
}
} else {
if (this.driverClass == null) {
this.driverClass = driver.getClass().getName();
}
}
// 用于存放所有连接对象
connections = new DruidConnectionHolder[maxActive];
// 用于存放需要丢弃的连接对象
evictConnections = new DruidConnectionHolder[maxActive];
// 用于存放需要keepAlive的连接对象
keepAliveConnections = new DruidConnectionHolder[maxActive];
初始化过滤器
看到下面的代码会发现,我们还可以通过SPI机制来配置过滤器。
使用SPI配置过滤器时需要注意,对应的类需要加上@AutoLoad注解,另外还需要配置load.spifilter.skip=false,SPI相关内容可参考我的另一篇博客:使用SPI解耦你的实现类。
在这个方法里,主要就是初始化过滤器的一些属性而已。过滤器的部分,本文不会涉及到太多。
// 初始化filters
for (Filter filter : filters) {
filter.init(this);
}
// 采用SPI机制加载过滤器,这部分过滤器除了放入filters,还会放入autoFilters
initFromSPIServiceLoader();
校验配置
这里只是简单的校验,不涉及太多复杂的逻辑。
// 校验maxActive、minIdle、initialSize、timeBetweenLogStatsMillis、useGlobalDataSourceStat、maxEvictableIdleTimeMillis、minEvictableIdleTimeMillis等配置是否合法
// ·······
// 针对oracle和DB2,需要校验validationQuery
initCheck();
// 当开启了testOnBorrow/testOnReturn/testWhileIdle,判断是否设置了validationQuery,没有的话会打印错误信息
validationQueryCheck();
初始化ExceptionSorter、ValidConnectionChecker、JdbcDataSourceStat
这里重点关注ExceptionSorter和ValidConnectionChecker这两个类,这里会根据数据库类型进行选择。其中,ValidConnectionChecker用于对连接进行检测。
// 根据driverClassName初始化ExceptionSorter
initExceptionSorter();
// 根据driverClassName初始化ValidConnectionChecker
initValidConnectionChecker();
// 初始化dataSourceStat
// 如果设置了isUseGlobalDataSourceStat为true,则支持公用监控数据
if (isUseGlobalDataSourceStat()) {
dataSourceStat = JdbcDataSourceStat.getGlobal();
if (dataSourceStat == null) {
dataSourceStat = new JdbcDataSourceStat("Global", "Global", this.dbType);
JdbcDataSourceStat.setGlobal(dataSourceStat);
}
if (dataSourceStat.getDbType() == null) {
dataSourceStat.setDbType(this.dbType);
}
} else {
dataSourceStat = new JdbcDataSourceStat(this.name, this.jdbcUrl, this.dbType, this.connectProperties);
}
dataSourceStat.setResetStatEnable(this.resetStatEnable);
创建initialSize数量的连接
这里有两种方式创建连接,一种是异步,一种是同步。但是,根据我们的使用例子,createScheduler为null,所以采用的是同步的方式。
注意,后面的所有代码也是基于createScheduler为null来分析的。
// 创建初始连接数
// 异步创建,createScheduler为null,不进入
if (createScheduler != null && asyncInit) {
for (int i = 0; i < initialSize; ++i) {
submitCreateTask(true);
}
// 同步创建
} else if (!asyncInit) {
// 创建连接的过程后面再讲
while (poolingCount < initialSize) {
PhysicalConnectionInfo pyConnectInfo = createPhysicalConnection();
DruidConnectionHolder holder = new DruidConnectionHolder(this, pyConnectInfo);
connections[poolingCount++] = holder;
}
if (poolingCount > 0) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
}
创建logStatsThread、createConnectionThread和destroyConnectionThread
这里会启动三个线程。
// 启动监控数据记录线程
createAndLogThread();
// 启动连接创建线程
createAndStartCreatorThread();
// 启动连接检测线程
createAndStartDestroyThread();
等待
这里使用了CountDownLatch,保证当createConnectionThread和destroyConnectionThread开始run时再继续执行。
private final CountDownLatch initedLatch = new CountDownLatch(2);
// 线程进入等待,等待CreatorThread和DestroyThread执行
initedLatch.await();
我们进入到DruidDataSource.CreateConnectionThread.run(),可以看到,一执行run方法就会调用countDown。destroyConnectionThread也是一样,这里就不放进来了。
public class CreateConnectionThread extends Thread {
public void run() {
initedLatch.countDown();
// do something
}
}
注册MBean
接下来是注册MBean,会去注册DruidDataSourceStatManager和DruidDataSource,启动我们的程度,通过jconsole就可以看到这两个MBean。JMX相关内容这里就不多扩展了,感兴趣的话可参考我的另一篇博客: 如何使用JMX来管理程序?
// 注册MBean,用于支持JMX
registerMbean();
通知createConnectionThread创建连接对象
前面已经讲过,当我们调用empty.signal(),会去唤醒处于empty.await()状态的CreateConnectionThread。CreateConnectionThread这个线只有在需要创建连接时才运行,否则会一直等待,后面会讲到。
protected Condition empty;
if (keepAlive) {
// 这里会去调用empty.signal(),会去唤醒处于empty.await()状态的CreateConnectionThread
this.emptySignal();
}
连接对象的获取
了解下DruidPooledConnection这个类
用户调用DruidDataSource.getConnection,拿到的对象时DruidPooledConnection,里面封装了DruidConnectionHolder,而这个对象包含了原生的连接对象和我们一开始创建的数据源对象。
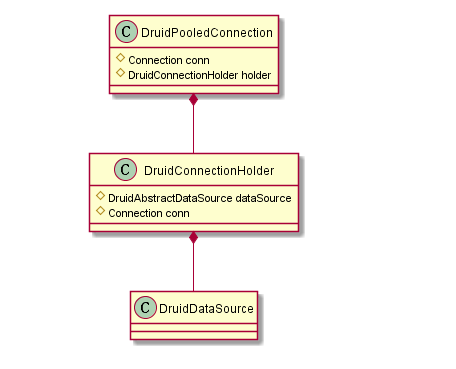
概括下获取连接的过程
连接对象的获取过程可以概括为以下步骤:
- 初始化数据源(如果还没初始化);
- 获得连接对象,如果无可用连接,向
createConnectionThread发送signal创建新连接,此时会进入等待; - 如果设置了
testOnBorrow,进行testOnBorrow检测,否则,如果设置了testWhileIdle,进行testWhileIdle检测; - 如果设置了
removeAbandoned,则会将连接对象放入activeConnections; - 设置
defaultAutoCommit,并返回; - 执行
filterChain。
初始化数据源的前面已经讲过了,这里就直接从第二步开始。
获取连接对象
进入DruidDataSource.getConnectionInternal方法。除了获取连接对象,其他的大部分是校验和计数的内容。
private DruidPooledConnection getConnectionInternal(long maxWait) throws SQLException {
// 校验数据源是否可用
// ······
final long nanos = TimeUnit.MILLISECONDS.toNanos(maxWait);
final int maxWaitThreadCount = this.maxWaitThreadCount;
DruidConnectionHolder holder;
// 加锁
try {
lock.lockInterruptibly();
} catch(InterruptedException e) {
connectErrorCountUpdater.incrementAndGet(this);
throw new SQLException("interrupt", e);
}
try {
// 判断当前等待线程是否超过maxWaitThreadCount
if(maxWaitThreadCount > 0 && notEmptyWaitThreadCount >= maxWaitThreadCount) {
connectErrorCountUpdater.incrementAndGet(this);
throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count " + lock.getQueueLength());
}
// 根据是否设置maxWait选择不同的获取方式,后面选择未设置maxWait的方法来分析
if(maxWait > 0) {
holder = pollLast(nanos);
} else {
holder = takeLast();
}
// activeCount(所有活跃连接数量)+1,并设置峰值
if(holder != null) {
activeCount++;
if(activeCount > activePeak) {
activePeak = activeCount;
activePeakTime = System.currentTimeMillis();
}
}
} catch(InterruptedException e) {
connectErrorCountUpdater.incrementAndGet(this);
throw new SQLException(e.getMessage(), e);
} catch(SQLException e) {
connectErrorCountUpdater.incrementAndGet(this);
throw e;
} finally {
// 解锁
lock.unlock();
}
// 当拿到的对象为空时,抛出异常
if (holder == null) {
// ······
}
// 连接对象的useCount(使用次数)+1
holder.incrementUseCount();
// 包装下后返回
DruidPooledConnection poolalbeConnection = new DruidPooledConnection(holder);
return poolalbeConnection;
}
下面再看下DruidDataSource.takeLast()方法(即没有配置maxWait时调用的方法)。该方法中,当没有空闲连接对象时,会尝试创建连接,此时该线程进入等待(notEmpty.await()),只有连接对象创建完成或池中回收了连接对象(notEmpty.signal()),该线程才会继续执行。
DruidConnectionHolder takeLast() throws InterruptedException, SQLException {
try {
// 如果当前池中无空闲连接,因为没有设置maxWait,会一直循环地去获取
while (poolingCount == 0) {
// 向CreateConnectionThread发送signal,通知创建连接对象
emptySignal(); // send signal to CreateThread create connection
// 快速失败
if (failFast && isFailContinuous()) {
throw new DataSourceNotAvailableException(createError);
}
// notEmptyWaitThreadCount(等待连接对象的线程数)+1,并设置峰值
notEmptyWaitThreadCount++;
if (notEmptyWaitThreadCount > notEmptyWaitThreadPeak) {
notEmptyWaitThreadPeak = notEmptyWaitThreadCount;
}
try {
// 等待连接对象创建完成或池中回收了连接对象
notEmpty.await(); // signal by recycle or creator
} finally {
// notEmptyWaitThreadCount(等待连接对象的线程数)-1
notEmptyWaitThreadCount--;
}
// notEmptyWaitCount(等待次数)+1
notEmptyWaitCount++;
}
} catch (InterruptedException ie) {
// TODO 这里是在notEmpty.await()时抛出的,不知为什么要notEmpty.signal()?
notEmpty.signal(); // propagate to non-interrupted thread
// notEmptySignalCount+1
notEmptySignalCount++;
throw ie;
}
// poolingCount(空闲连接)-1
decrementPoolingCount();
// 获取数组中最后一个连接对象
DruidConnectionHolder last = connections[poolingCount];
connections[poolingCount] = null;
return last;
}
创建连接对象
前面已经讲到,创建连接是采用异步方式,进入到DruidDataSource.CreateConnectionThread.run()。当不需要创建连接时,该线程进入empty.await()状态,此时需要用户线程调用empty.signal()来唤醒。
public void run() {
// 用于唤醒初始化数据源的线程
initedLatch.countDown();
long lastDiscardCount = 0;
// 注意,这里是死循环,当需要创建连接对象时,这个线程会受到signal,否则会一直await
for (;;) {
// 加锁
try {
lock.lockInterruptibly();
} catch (InterruptedException e2) {
break;
}
// 丢弃数量discardCount
long discardCount = DruidDataSource.this.discardCount;
boolean discardChanged = discardCount - lastDiscardCount > 0;
lastDiscardCount = discardCount;
try {
// 这个变量代表了是否有必要新增连接,true代表没必要
boolean emptyWait = true;
if (createError != null
&& poolingCount == 0
&& !discardChanged) {
emptyWait = false;
}
if (emptyWait
&& asyncInit && createCount < initialSize) {
emptyWait = false;
}
if (emptyWait) {
// 必须存在线程等待,才创建连接
if (poolingCount >= notEmptyWaitThreadCount //
&& (!(keepAlive && activeCount + poolingCount < minIdle))
&& !isFailContinuous()
) {
// 等待signal,前面已经讲到,当某线程需要创建连接时,会发送signal给它
empty.await();
}
// 防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
}
} catch (InterruptedException e) {
lastCreateError = e;
lastErrorTimeMillis = System.currentTimeMillis();
break;
} finally {
// 解锁
lock.unlock();
}
PhysicalConnectionInfo connection = null;
try {
// 创建原生的连接对象,并包装
connection = createPhysicalConnection();
} catch (SQLException e) {
//出现SQLException会继续往下走
//······
} catch (RuntimeException e) {
// 出现RuntimeException则重新进入循环体
LOG.error("create connection RuntimeException", e);
setFailContinuous(true);
continue;
} catch (Error e) {
LOG.error("create connection Error", e);
setFailContinuous(true);
break;
}
// 如果为空,重新进入循环体
if (connection == null) {
continue;
}
// 将连接对象包装为DruidConnectionHolder,并放入connections数组中
// 注意,该方法会去调用notEmpty.signal(),即会去唤醒正在等待获取连接的线程
boolean result = put(connection);
}
}
testOnBorrow或testWhileIdle
进入DruidDataSource.getConnectionDirect(long)。该方法会使用到validConnectionChecker来校验连接的有效性。
// 如果开启了testOnBorrow
if (testOnBorrow) {
// 这里会去调用validConnectionChecker的isValidConnection方法来校验,validConnectionChecker不存在的话,则以普通JDBC方式校验
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
Connection realConnection = poolableConnection.conn;
// 丢弃连接,丢弃完会发送signal给CreateConnectionThread来创建连接
discardConnection(realConnection);
continue;
}
} else {
Connection realConnection = poolableConnection.conn;
if (poolableConnection.conn.isClosed()) {
discardConnection(null); // 传入null,避免重复关闭
continue;
}
if (testWhileIdle) {
final DruidConnectionHolder holder = poolableConnection.holder;
// 当前时间
long currentTimeMillis = System.currentTimeMillis();
// 最后活跃时间
long lastActiveTimeMillis = holder.lastActiveTimeMillis;
long lastKeepTimeMillis = holder.lastKeepTimeMillis;
if (lastKeepTimeMillis > lastActiveTimeMillis) {
lastActiveTimeMillis = lastKeepTimeMillis;
}
// 计算连接对象空闲时长
long idleMillis = currentTimeMillis - lastActiveTimeMillis;
long timeBetweenEvictionRunsMillis = this.timeBetweenEvictionRunsMillis;
// 空闲检测周期
if (timeBetweenEvictionRunsMillis <= 0) {
timeBetweenEvictionRunsMillis = DEFAULT_TIME_BETWEEN_EVICTION_RUNS_MILLIS;
}
// 当前连接空闲时长大于空间检测周期时,进入检测
if (idleMillis >= timeBetweenEvictionRunsMillis
|| idleMillis < 0 // unexcepted branch
) {
// 接下来的逻辑和前面testOnBorrow一样的
boolean validate = testConnectionInternal(poolableConnection.holder, poolableConnection.conn);
if (!validate) {
if (LOG.isDebugEnabled()) {
LOG.debug("skip not validate connection.");
}
discardConnection(realConnection);
continue;
}
}
}
}
removeAbandoned
进入DruidDataSource.getConnectionDirect(long),这里不会进行检测,只是将连接对象放入activeConnections,具体泄露连接的检测工作是在DestroyConnectionThread线程中进行。
if (removeAbandoned) {
StackTraceElement[] stackTrace = Thread.currentThread().getStackTrace();
poolableConnection.connectStackTrace = stackTrace;
// 记录连接借出时间
poolableConnection.setConnectedTimeNano();
poolableConnection.traceEnable = true;
activeConnectionLock.lock();
try {
// 放入activeConnections
activeConnections.put(poolableConnection, PRESENT);
} finally {
activeConnectionLock.unlock();
}
}
DestroyConnectionThread线程会根据我们设置的timeBetweenEvictionRunsMillis来进行检验,具体的校验会去运行DestroyTask(DruidDataSource的内部类),这里看下DestroyTask的run方法。
public void run() {
// 检测空闲连接的phyTimeoutMillis、idleMillis是否超过指定要求
shrink(true, keepAlive);
// 这里会去调用DruidDataSource.removeAbandoned()进行检测
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
进入DruidDataSource.removeAbandoned(),当连接对象使用时间超过removeAbandonedTimeoutMillis,则会被丢弃掉。
public int removeAbandoned() {
int removeCount = 0;
long currrentNanos = System.nanoTime();
List<DruidPooledConnection> abandonedList = new ArrayList<DruidPooledConnection>();
// 加锁
activeConnectionLock.lock();
try {
Iterator<DruidPooledConnection> iter = activeConnections.keySet().iterator();
// 遍历借出的连接
for (; iter.hasNext();) {
DruidPooledConnection pooledConnection = iter.next();
if (pooledConnection.isRunning()) {
continue;
}
// 计算连接对象使用时间
long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000);
// 如果超过设置的丢弃超时时间,则加入abandonedList
if (timeMillis >= removeAbandonedTimeoutMillis) {
iter.remove();
pooledConnection.setTraceEnable(false);
abandonedList.add(pooledConnection);
}
}
} finally {
// 解锁
activeConnectionLock.unlock();
}
// 遍历需要丢弃的连接对象
if (abandonedList.size() > 0) {
for (DruidPooledConnection pooledConnection : abandonedList) {
final ReentrantLock lock = pooledConnection.lock;
// 加锁
lock.lock();
try {
// 如果该连接已经失效,则继续循环
if (pooledConnection.isDisable()) {
continue;
}
} finally {
// 解锁
lock.unlock();
}
// 关闭连接
JdbcUtils.close(pooledConnection);
pooledConnection.abandond();
removeAbandonedCount++;
removeCount++;
}
}
return removeCount;
}
执行filterChain
进入DruidDataSource.getConnection。
public DruidPooledConnection getConnection(long maxWaitMillis) throws SQLException {
// 初始化数据源(如果还没初始化)
init();
// 如果设置了过滤器,会先执行每个过滤器的方法
if (filters.size() > 0) {
FilterChainImpl filterChain = new FilterChainImpl(this);
// 这里会去递归调用过滤器的方法
return filterChain.dataSource_connect(this, maxWaitMillis);
} else {
// 如果没有设置过滤器,直接去获取连接对象
return getConnectionDirect(maxWaitMillis);
}
}
进入到FilterChainImpl.dataSource_connect。
public DruidPooledConnection dataSource_connect(DruidDataSource dataSource, long maxWaitMillis) throws SQLException {
// 当指针小于过滤器数量
// pos表示过滤器的索引
if (this.pos < filterSize) {
// 拿到第一个过滤器并调用它的dataSource_getConnection方法
DruidPooledConnection conn = getFilters().get(pos++).dataSource_getConnection(this, dataSource, maxWaitMillis);
return conn;
}
// 当访问到最后一个过滤器时,才会去创建连接
return dataSource.getConnectionDirect(maxWaitMillis);
}
这里以StatFilter.dataSource_getConnection为例。
public DruidPooledConnection dataSource_getConnection(FilterChain chain, DruidDataSource dataSource,
long maxWaitMillis) throws SQLException {
// 这里又回到FilterChainImpl.dataSource_connect方法
DruidPooledConnection conn = chain.dataSource_connect(dataSource, maxWaitMillis);
if (conn != null) {
conn.setConnectedTimeNano();
StatFilterContext.getInstance().pool_connection_open();
}
return conn;
}
以上,druid的源码基本已经分析完,其他部分内容有空再做补充。
参考资料
本文为原创文章,转载请附上原文出处链接:https://www.cnblogs.com/ZhangZiSheng001/p/12175893.html