本文参考:https://blog.csdn.net/wxy941011/article/details/80428470
原因
如果客户端连续不断的向服务端发送数据包时,服务端接收的数据会出现两个数据包粘在一起的情况,这就是TCP协议中经常会遇到的粘包以及拆包的问题。
我们都知道TCP属于传输层的协议,传输层除了有TCP协议外还有UDP协议。
TCP
TCP是基于字节流的,虽然应用层和TCP传输层之间的数据交互是大小不等的数据块,但是TCP把这些数据块仅仅看成一连串无结构的字节流,没有边界;另外从TCP的帧结构也可以看出,在TCP的首部没有表示数据长度的字段(也就是说TCP并不知道发送的单个数据的长度,只要缓冲区空间足够或是缺少,就有可能发生粘包(和下一个数据流黏在一起)或拆包(本数据流被拆分)),基于上面两点,在使用TCP传输数据时,才有粘包或者拆包现象发生的可能。
UDP
那么UDP是否会发生粘包或拆包的现象呢?答案是不会。UDP是基于报文发送的,从UDP的帧结构可以看出,在UDP首部采用了16bit来指示UDP数据报文的长度,因此在应用层能很好的将不同的数据报文区分开,从而避免粘包和拆包的问题。
打个比方
TCP中传输数据字节流就像是在两个人之间传递水,它们通过一个容器(缓冲区)来盛装水,甲连续地向乙传输水,如果有两次的水量刚好可以被容器装进去那就有可能将两次的水(数据字节流)放到同一个容器(缓冲区)中进行传递(粘包),如果不够那么一次的水可能分两次传输(拆包),基本上有三种情况:
容器>=两次水量,两次水量>容器>一次水量,容器<一次水量【要注意每一次的水量可能不一样】
部分原因
-
要发送的数据大于TCP发送缓冲区剩余空间大小,将会发生拆包。
-
待发送数据大于MSS(最大报文长度),TCP在传输前将进行拆包。
-
要发送的数据小于TCP发送缓冲区的大小,TCP将多次写入缓冲区的数据一次发送出去,将会发生粘包。
-
接收数据端的应用层没有及时读取接收缓冲区中的数据,将发生粘包。
原因并不全面,可能会有其他原因,常见的为上述内容
表现形式
现在假设客户端向服务端连续发送了两个数据包,用packet1和packet2来表示,那么服务端收到的数据可以分为三种,
-
第一种情况
接收端正常收到两个数据包,即没有发生拆包和粘包的现象,此种情况不在本文的讨论范围内。
-
第二种情况
接收端只收到一个数据包,由于TCP是不会出现丢包的,所以这一个数据包中包含了发送端发送的两个数据包的信息,这种现象即为粘包。这种情况由于接收端不知道这两个数据包的界限,所以对于接收端来说很难处理。
-
第三种情况
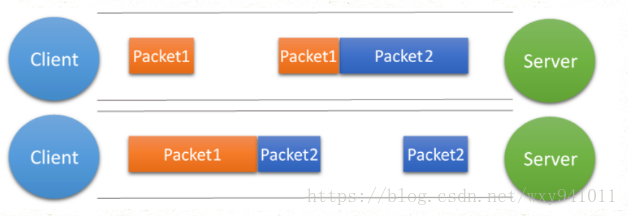
这种情况有两种表现形式,如下图。接收端收到了两个数据包,但是这两个数据包要么是不完整的,要么就是多出来一块,这种情况即发生了拆包和粘包。这两种情况如果不加特殊处理,对于接收端同样是不好处理的。


解决方法
就像上述原因中提到1. TCP是基于字节流的,虽然应用层和TCP传输层之间的数据交互是大小不等的数据块,但是TCP把这些数据块仅仅看成一连串无结构的字节流,没有边界;2. 另外从TCP的帧结构也可以看出,在TCP的首部没有表示数据长度的字段(也就是说TCP并不知道发送的单个数据的长度
因此,解决问题的关键在于如何给每个数据包添加边界信息,基本上有以下三种常见解决办法
-
发送端给每个数据包添加包首部,首部中应该至少包含数据包的长度,这样接收端在接收到数据后,通过读取包首部的长度字段,便知道每一个数据包的实际长度了。【本次项目的解决方法】
-
发送端将每个数据包封装为固定长度(不够的可以通过补0填充),这样接收端每次从接收缓冲区中读取固定长度的数据就自然而然的把每个数据包拆分开来。
-
可以在数据包之间设置边界,如添加特殊符号,这样,接收端通过这个边界就可以将不同的数据包拆分开。
代码
使用第一种方法,写一个构造包的类,包括 包头(数据长度)和包尾(数据)
-
用到的using形式的代码的解释
// 正常情况下 Memory ms = new MemoryStream(); // 各种流操作 ms.Close();// 关闭流 // 使用using using (Memory ms = new MemoryStream()){ // 各种流操作 // 使用完毕自动关闭流 }
-
用到的MemoryStream,内存流对象
new MemoryStream().GetBuffer() 从中返回其中写入的无符号字节数组(就是返回写入这个内存流对象的数据流数据)
-
用到的BinaryWriter,二进制写入
new BinaryWriter.Write(byte[] targetBuffer) 用于写入数据(与上述内存流对象联合使用)
-
用到的Buffer.BlockCopy,拷贝数据流至
参数(源数据流,源数据流偏移,要copy到的字节数组对象,字节流对象偏移,要copy的数据长度)
上面三条的使用流程:
-
建立内存流对象 new MemoryStream()
-
向内存流对象写入数据 new BynaryWriter.Write(data)
-
将写入的数据(原缓冲区内容,即下面代码中的data)拷贝至新建的字节数组(目标缓冲区)
-
关闭流(auto)
构建包
就是将数据构建为一个包——包头(数据长度)+包尾(数据)
class EncodeTool{ // 构造包 包头+包尾 public static byte[] EncodePacket(byte[] data){ using(MemoryStream ms = new MemoryStream()){ using(BinaryWriter bw = new BinaryWriter(ms)){ // 1. 写入包头(数据长度) bw.Write(data.length); // 2. 写入包尾(数据) bw.Write(data); // 3. 拷贝 byte[] targetBuffer = new byte[ms.length]; Buffer.BlockCopy(ms.GetBuffer(),0,targetBuffer,0,(int)ms.Length); // 这里的ms.Length是长整型的,为了匹配形参,强制转换为int类型 return targetBuffer; // 4. 自动关闭流 // 5. 返回构建的数据包 } } } }
解析包
-
用到的ref关键字,在参数前面加ref标明这个参数会在方法中被改变,这里为地址处存储的值的更新,因为数据包(缓冲区)被解析后返回数据,那么原本的数据包就可以情况并接收之后的数据了,所以需要更新
-
用到的 List<>,数据包用List来接收是为了在解析时候的方便,这个在查看代码中使用到的地方就可以理解
-
用到的BinaryReader,与上述内容的BinaryWriter类似,一个是写入,一个是读取
new BynaryReader().ReadInt32(),这个方法表示读取数据流的前四个字节并使流的当前位置提升四个字节(就好比一个队列中被去除了四个字节其他的依次向前移)
// 承接上面EncodeTool类 public static byte[] DecodePacket(ref List<byte> cache) { if (cache.Count < 4) { // cache的数据长度还不到一个int类型数据->包头也不够->没数据 return null; } using(MemoryStream ms = new MemoryStream()) { using (BinaryReader br = new BinaryReader(ms)) { int length = br.ReadInt32();// 刚好对应构建包中的包头部分 // 1. 计算缓冲区剩下的数据字节长度(即数据部分) int remainLength = (int)(ms.Length - ms.Position);// 这里的ms.position自行体会 if (remainLength < length) { // 如果剩下的数据长度小于读取到的数据长度,就说明这个缓冲区内并不存在一个完整的包(也就是数据>缓冲区的情况) return null; } // 至少包括一个完整的包 byte[] data = br.ReadBytes(length);// 读取length长度的数据(即解析的数据包中的数据)并存储至data字节数组 // 2. 更新数据缓存,将被读取的数据移除,继续读取下一个数据包 cache.Clear();// 这里就是为什么本方法形参前需要加ref关键字的原因 int remainLengthAgain = (int)(ms.Length - ms.Position);// 清空之后重新获取剩下的数据长度 cache.AddRange(br.ReadBytes(remainLengthAgain));// 读取处已解析数据包外的数据部分并转移至缓冲区 // 3. 返回解析的数据 return data; } } }