注意力的种类有如下四种:
- 加法注意力, Bahdanau Attention
- 点乘注意力, Luong Attention
- 自注意力, Self-Attention
- 多头点乘注意力, Multi-Head Dot Product Attention(请转至Transformer模型)
1. Bahdanau Attention
Neural Machine Translation by Jointly Learning to Align and Translate, Bahdanau et al, ICLR 2015
总览
2015年发布的论文,首次提出注意力机制,也就是加法注意力,并将其应用在机器翻译领域。
当前工作的不足
目前NMT主流的方法是seq2seq方法,具体采用的是encoder-decoder模型。但是在编解码模型中编码得到的是固定长度的context vector,这是当前seq2seq的瓶颈。
本文提出联合学习对齐和翻译的方法:
- 对齐:在预测每一个target word的时候都去search源句子中一个部分
- 翻译:根据对齐的部分动态生成c,然后基于c和上一个target word生成当前的target word
模型
下图展示了在预测target word (o_t)时从源句子隐藏状态动态生成上下文向量的过程。
首先根据对齐模型(a),给每个源隐藏状态(h_j)生成一个权重系数(e_{tj}):
然后将所有权重系数进行softmax归一化得到各个源隐藏状态的注意力权重:
计算注意力权重和各个源隐藏状态的加权和,得到预测(o_t)的注意力向量:
然后根据注意力向量进行预测:
文章在这里对g进行了解释:g是非线性的,可能是多层的函数。
结论
通过注意力机制,避免了encoder将整个句子的语义信息编码成一个固定长度的上下文向量,并在翻译时将注意力集中到和下一个目标词相关的信息上。在长句子上,此方法的提升尤为突出。
下图展示了注意力机制的可视化:

简单解释下:x和y轴分别表示源句子(英语)和生成的句子(法语),权重系数通过像素的灰度值来刻画,1表示全白,0表示全黑。
文章最后提出,未来的工作是处理一些罕见词。
2. Luong Attention
Effective Approaches to Attention-based Neural Machine Translation, Luong, EMNLP 2015
总览
Luong提出了全局和局部注意力(这里只讨论全局注意力),本文提出了新的权重系数计算方法,大大提高了成绩。
当前工作存在的不足
本文继Bahdanau之后继续研究注意力,在此根据对齐时,覆盖所有范围和部分范围,提出了全局注意力(global attention)和局部注意力(local attention)。
模型
全局注意力和局部注意力的区别是生成注意力向量的方式不同,后续工作都是一样的。
下图展示了全局注意力的完整生成过程:

在这里,权重系数直接根据目标隐藏状态(h_t)和源隐藏状态(overline h_s)计算得到,计算方法有以下几种:
然后将分数进行归一化:
文中没有给出注意力向量的计算过程,可以参考Bahdanau注意力的计算过程,通过加权和得到注意力向量(c_t)
将注意力向量和隐藏状态(h_t)简单拼接,输入到全连接层,得到隐藏状态( ilde h_t):
根据这个隐藏状态即可得到最后的输出:
总结&相比Bahdanau的优势
无论是全局注意力还是局部注意力,Luong都提出了多种权重系数计算方式,最后的实验结果表示:对于全局注意力,dot的方式是最好的;对于局部注意力,general的方式最好。
但是可以看出无论是哪一种计算方式,都不再需要预先计算出(s_{t-1})了,这样就可以实现并行化计算,大大提高了计算速度。
3. Self-Attention
A Structured Self-Attentive Sentence Embedding, Zhouhan Lin et al, ICLR 2017
总览
本文提出使用自注意力机制计算不同注意力系数作用下的句子嵌入(sentence embedding)。
然后将得到的句子嵌入应用到多个NLP任务(author profiling, sentiment classification, textual entailment)中去。
自注意力是注意力机制的一种特例:因为自注意力的源隐藏状态和目标隐藏状态的来源相同。
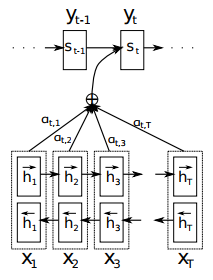
模型
模型的结构如下图所示:

从图中可以看出,如果只考虑一种句子嵌入,双向LSTM的输出为H,那么模型的注意力权重计算如下所示:
上式中,(W_{s_2} in Bbb R^{1 imes d_a}),(W_{s_1}in Bbb R^{d_a imes 2u}),(H in Bbb R^{n imes 2u}),(d_a)是超参数
此时如果考虑多种句子嵌入,那么
此时,(W_{s_2} in Bbb R^{r imes d_a}),那么就得到r套注意力权重,计算其和源隐藏状态加权和就得到多种句子嵌入:
这就是最后的句子嵌入矩阵。