一直以来总能听到消息队列这个词,今天想要记录一下我的理解,
消息队列(Message Queue):
1、理解定义:首先想起一个内容叫做队列(Queue),这个在我头疼的数据结构中很常见的东西,其实简单来说就是先进先出,而消息队列就是要把传输的数据放在这个队列中。
2、理解作用:
(1)解耦:开发时的解耦就是降低程序之间相互的关联关系,这里也不例外,关联越多,迭代越复杂,当你的关联关系太紧密时,迭代起来就要反复的修改同一个文件,浪费精力还没有什么提高,这个时候就可以使用消息队列了
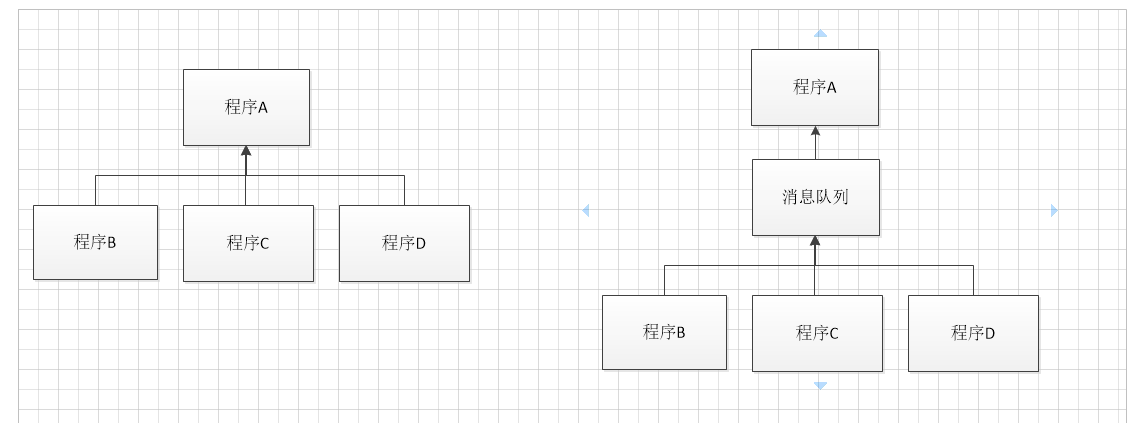
当你从图一到图二的时候你就会发现,不用频繁的改一段代码对程序媛来说,就是一种幸福~
(2)异步: 还拿上图举例,若A,B,C,D 都需50ms ,消息队列也是同样50ms,同步时 不用消息队列就需要50*4=200ms 而异步采用消息队列只需要A+消息队列时间 50+50=100ms 节约时间,
在高并发的情况下,我们如果还有EFG...省下来的时间~~可以喝咖啡了
(3)削峰、限流:这个我认为是最好理解的...每个程序最高只能处理1000个请求,一旦一次进来10000个...图一全部堆积,必将导致崩溃,而图二就不一样了
消息队列相当于一个大房子,请求全部接受了,剩下的程序你自己慢慢处理去吧,大大降低了程序崩溃的风险。
3、理解缺点...
但凡程序都有bug....不要对自己太自信哈哈哈哈...消息队列的bug就是....
(1)高可用:像我这样的菜鸟不太喜欢分布式...总觉得一台性能好的机器啥都能解决...然而...一旦一台系统崩溃,我也就崩溃了
(2)数据丢失:光有消息队列也是有问题的,就算部署了很多台,万一都挂了....啊哈哈哈哈哈....还是停了....数据也就丢了
4、理解用法:(这个理解不好使了,直接用人家的专业术语吧)
- 生产者将数据放到消息队列中,消息队列有数据了,主动叫消费者去拿(俗称push)
- 消费者不断去轮训消息队列,看看有没有新的数据,如果有就消费(俗称pull)
5、针对消息队列衍生了很多中间件,我目前遇到了RabbitMQ和Redis...具体选择哪一个就要针对项目来看了。
这位同学的对比写的很清晰,记录一下~ https://blog.csdn.net/liuzhen12580/article/details/103365453