阅读笔记 - A Simple Baselline for Multi-Object Tracking (FairMOT)
来源于华中科大的一篇anchor-free结构同时detect和ReID的多目标跟踪方法,(和我们的方法撞车了把我们撞的稀碎。。。欲哭无泪)

1. 摘要
目标检测和ReID近些年了发展较快,也促进了MOT任务的推进,但MOT领域对如何将检测和ReID融合成一个网络的研究相对少的多。检测和ReID放在一个网络中的尝试往往会导致跟踪性能下降,这是因为ReID抽取的特征鉴别力较弱。所以这篇文章主要是研究了导致联合网络性能较差的背后原因,以及对应的解决办法。
文章方法的跟踪速度能到达30FPS, 且跟踪性能不错。
开源代码。github 代码
2. 简介
当前主流的多目标跟踪方法一般将MOT划分成两个子任务:检测和关联。这两子任务近些年都取得长足进步,但分离的操作严重拖累了MOT的推理速度。
一般我们认为MOT分为三部分:检测,特征抽取和数据关联。这里把特征抽取作为了数据关联中的一部分。相当于把ReID认为是一个关联问题。
越来越多的研究开始采用one-shot的单任务学习中将检测和ReID特征抽取一起处理的做法。目标检测和特征抽取其高层任务虽然不同,但底层可以共享基本的特征,通过共享底层结构,能够较显著的降低推理时间。但和two-stage方法相比,其精度一般较差,尤其是IDS较严重,这表明简单的通过共享网络将两个任务融合起来是不可行的。
本文分析认为one-shot方法性能下降的原因有三点:
- anchors dont fit Re-ID. 现在的one-shot方法一般是基于anchor的,这就会带来一个问题:多个不同的anchor会被用来估计同一个目标,导致网络的歧义性,如图1。另外在检测任务中,一般图像下采样较大,这会给reID带来严重的精度损失。


个人认为这个地方论述不够准确,虽然多个anchor会负责同一个目标,但经过检测回归后这些anchor回归的结果还是很相近的,并不会带来歧义性。 虽然我们的方法也采用了anchor-free的思路,但我们的出发点是一个location上对应多个anchor,于是回归可能对应不同目标的多个bbox,但ReID分支一般在该location上仅抽取一个特征向量,于是这个特征向量的标签就会具有歧义性,导致ReID特征鉴别性下降。
-
多层特征融合。 ReID特征需要同时利用到底层细节特征和高层的语义特征,因此针对于不同尺寸的目标,需要从不同的stage抽取特征,所以为了增强特征鉴别性,需要特征的融合。
-
特征的维度。ReID方法所使用的数据集一般都是crop和resize之后的,对于跟踪而言无法使用,所以跟踪能使用的数据相对较少,为了避免模型过拟合,可以使用低维的鉴别特征。
文章的共享贡献点:
- 陈述了目前one-shot的MOT方法背后存在的问题;
- 从其他领域借鉴了一些方法和概念处理这些存在的问题,提供了一个简单却强大的baseline。
3. 方法介绍
本文方法的框架图:

3-1. backbone
基干网络采用的是ResNet-34,然后不同的stage之间采用修改版的Deep Layer Aggregation (DLA)进行融合,最终输出的特征map相对于输入下采用的4倍,而不是原来的32倍,能有效提升检测的精度和特征抽取的精度。
3-2. 目标检测分支
检测分支采用的是基于center的目标检测,包含三个目标头:热图、中心点位置回归、尺寸回归。
热图用于选择哪些位置对应的正样本,可以用来回归检测框,中心点位置回归和尺寸回归其实和传统的bbox回归作用是一样的。
3-3. 特征嵌入分支
通过一个卷积层在每个location上输出128维的特征向量,用于特征匹配。
3-4. 损失函数定义
热图 热图主要是用来确定正负样本。其gt由bbox的中心点位置确定,
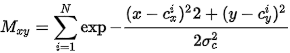
表示heatmap的gt,假设每个检测的可能位置都是以检测中心点为中心的高斯分布,于是
于是采用FocalLoss计算heatmap的回归损失:

其中
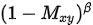 是负样本的重要性加权,显然离中心点越近的点将其作为负样本的置信度越小,于是其在负样本的损失函数中起的作用让其越小。
是负样本的重要性加权,显然离中心点越近的点将其作为负样本的置信度越小,于是其在负样本的损失函数中起的作用让其越小。位置偏差和尺寸回归
简单的采用L1损失函数,值得注意的是这里中心点回归的位置是相对于其取整后的小数部分作为offset。
鉴别损失
和传统的ReID损失相同,直接将匹配问题转化成了分类问题,采用交叉熵损失。
3-5. 在线跟踪
网络推断
由heatmap通过阈值筛选出可能是正样本的位置,在该对应位置中由回归得到的offset和size组装其回归的bbox,然后进行NMS,对于保留的bbox,由其中心点选择回归得到的鉴别特征。
在线bbox关联
标准的MOT流程,采用ReID进行关联,关联失败的采用IOU关联。在关联过程中通过kalman滤波剔除空间不合理的关联。这里提到表观跟踪的策略是在每一帧中通过Correlation filters进行更新。
4. 实验部分
-
数据和JDE中的数据集相同,用了额外的检测和reid数据。度量方法也和JDE中相同,除了MOT的度量系统CLEAR之外,引入了检测精度指标AP和ReID特征鉴别性度量指标 True Positive Rate(TPR).
-
实现细节:DLA-34的变种作为backbone,现在COCO检测数据集上进行了预训练。使用Adam优化器训练了30个epoch(比JDE训练次数少),学习率由
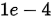 在20和27个epoch上分别降低10倍。 batchisize是12. 采用了旋转、尺度缩放,颜色抖动的数据增强。输入尺寸1088*608. 2张2080上训练了差不多30小时,速度还是挺快的。
在20和27个epoch上分别降低10倍。 batchisize是12. 采用了旋转、尺度缩放,颜色抖动的数据增强。输入尺寸1088*608. 2张2080上训练了差不多30小时,速度还是挺快的。 -
实验组织:
- 将anchor-free的检测头换成anchor-based,其他不变,验证anchor-free的有效性。结论anchor-free能显著增强特征鉴别性。
- 采用不同的下采样步长,发现相同步长下,anchor-free优于anchor-based方法/ 分辨率较高的情形,anchor-based反而性能下降了,作者认为是未对齐的anchors更多导致训练不充分。
- 对比了不同backbone

- 不同的backbone对于不同尺寸目标的检测跟踪对比

实验DLA性能优势主要体现在对于中小物体提取的特征鉴别性更好。 - 不同的特征维度,维度的影响其实不大

- 最后是对SOTA的对比。
这部分没有给出FN的对比,FN对于MOTA一般影响最大。



总结:实验设置部分要紧紧围绕着文章提出的创新点来做,依次证明宣称的创新点是有效的。
5. 总结
提出一个简单有效的one-shot多目标跟踪。所以MOT联合框架设计考虑的要素:anchor-free, 大分辨率,不同stage的特征融合。