Transformer
seq2seq model with “self-attention”
知名代表--bert
一般处理seq2seq容易想到RNN,但RNN的问题是不容易被平行化。于是有人提出用CNN。
如下右图所示,每个黄色三角代表一个filter,每次考虑3个词,从左往右依次遍历就可以从a1到a4 提取出第二层 b1到b4,蓝色三角再从第二层开始提取,第一个蓝色三角考虑b1到b3,其实就已经考虑了a1到a4,相当于读完了整个句子。
每个黄色filter都是可以并行处理的。除了黄色三角filter,还可以有橙色等其他filter,都是可以与黄色filter同时执行。所以CNN处理,不仅可以得到与RNN类似的输出形式,同时也可以更好的并行化。
但CNN处理的问题在于,如果要看很长范围的句子内容,必须叠很高的层。如果第二层就想知道很长句子的内容,那么是做不到的。

Transformer中抛弃了传统的CNN和RNN,整个网络结构由self-Attention和Feed Forward Neural Network组成。
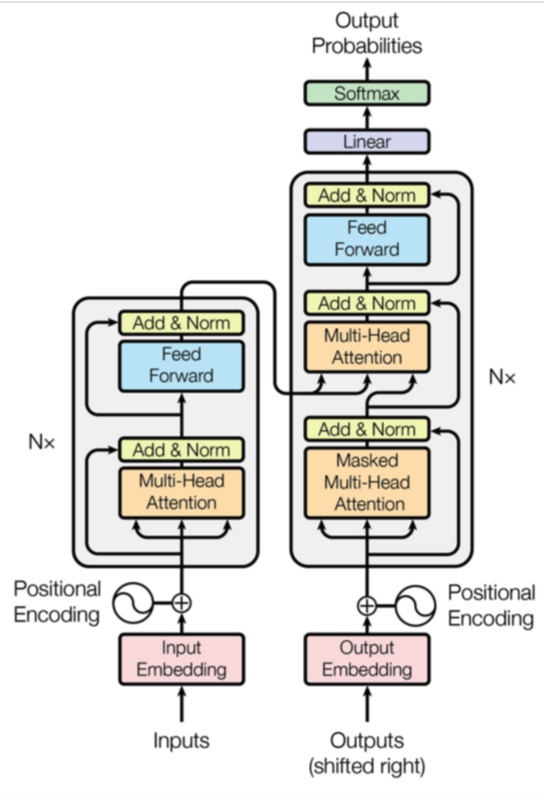
一个基于Transformer可训练的神经网络可通过堆叠Transformer进行搭建。Transformer论文中搭建编码器和解码器各6层,共12层的Encoder-Decoder
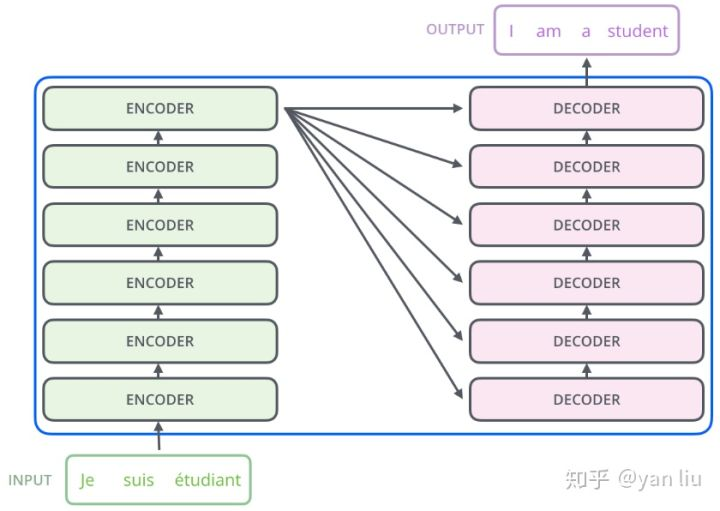
其中Encoder和Decoder的结构如下图所示:
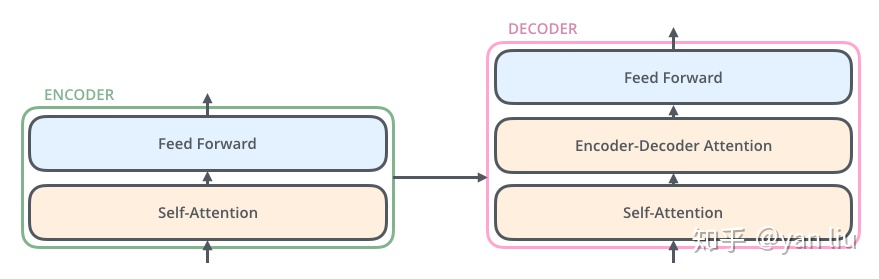
注:在最底层的Encoder中,输入是通过word2vec等词嵌入方法将语料转为的词向量。在其他层中,输入则是上一个Encoder的输出。
这里我们要先介绍一下self-attention是神马
Self-Attention
Self-Attention的输入输出与RNN一样,输入一个sequence,输出一个seqeunce。 特别的地方是与bidirectional RNN(双向)有同样的能力,每个输出都看过整个sequence,序列中任意两个位置的距离都是一个常量。但更特别的是self-attention中每个输出可以同时算出来。
我们可以用self-attention来取代所有RNN能做的事情。
过程如下:
X1 到 X4是input sequence
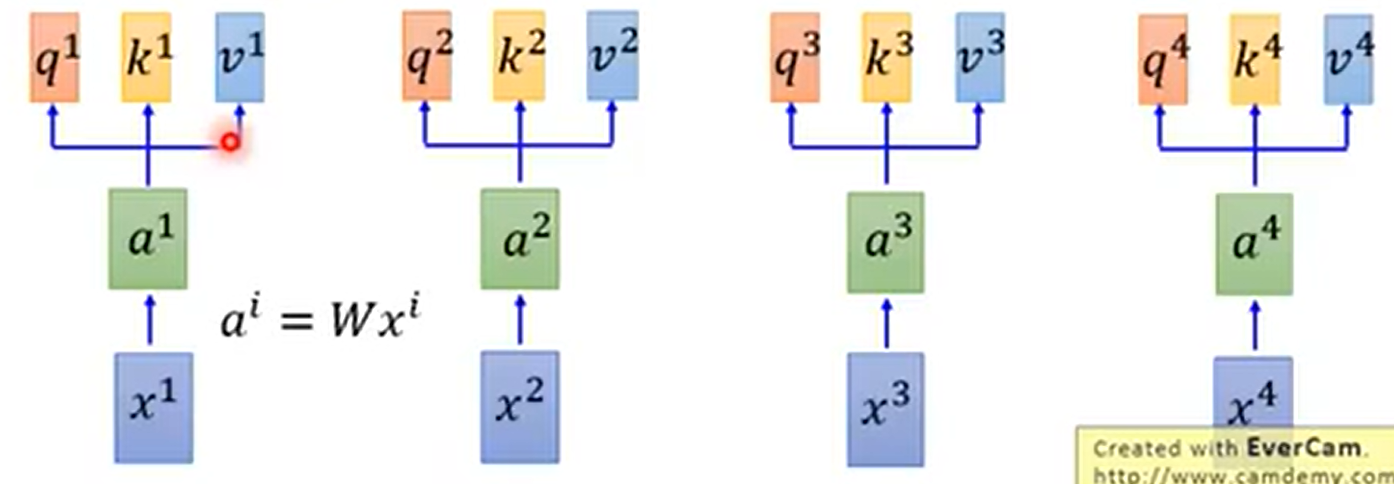
每个input先通过一个embedding,乘以 W ,变为a1 到 a4
把a1 到 a4丢到self-attention layer中,即:
分别乘上三个不同的matrix
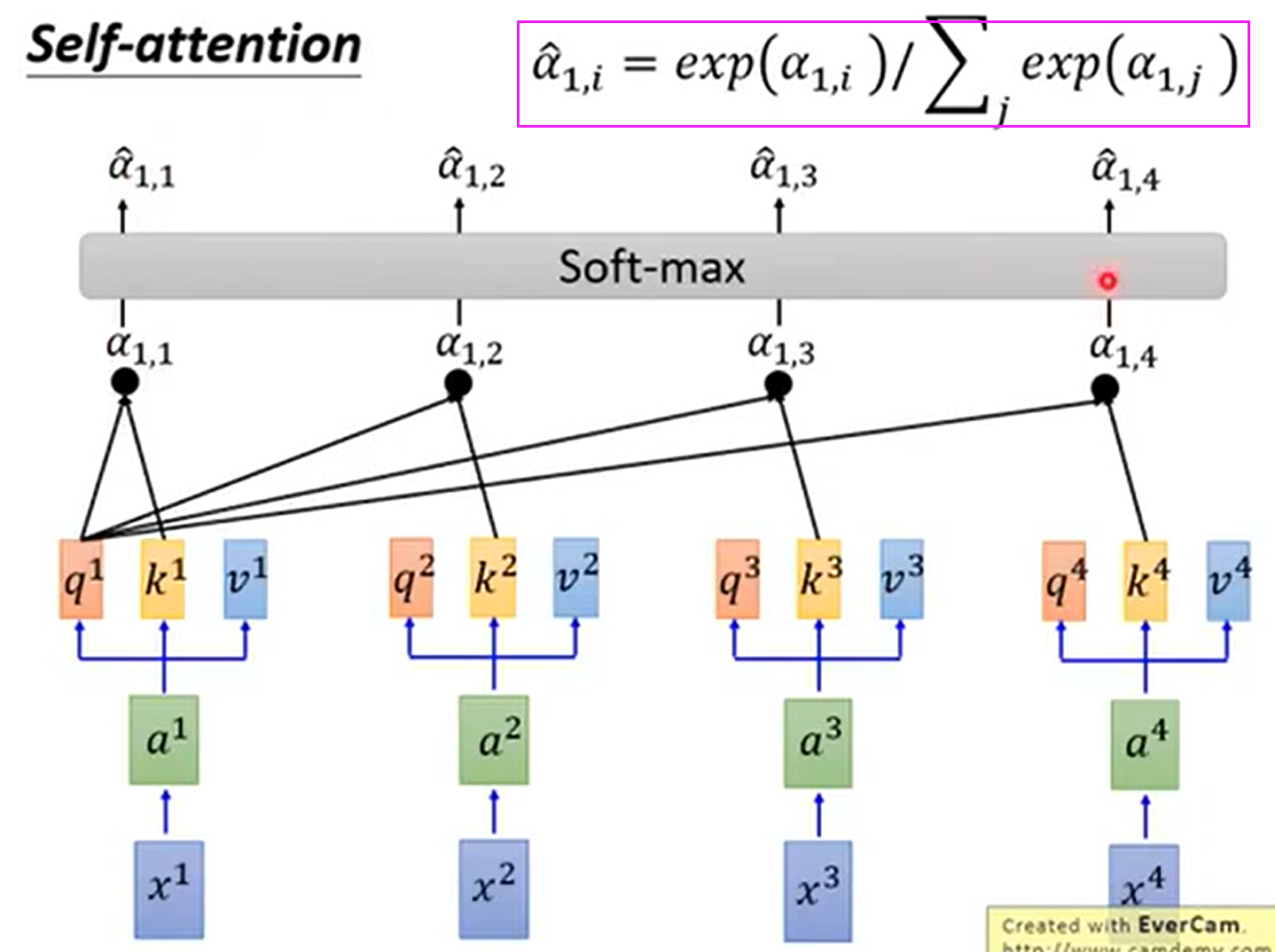
q:query(to match others)—— qi = Wq * ai
k:key(to be matched)—— ki = Wk * ai
v:value(information to be extracted)—— vi = Wv * ai
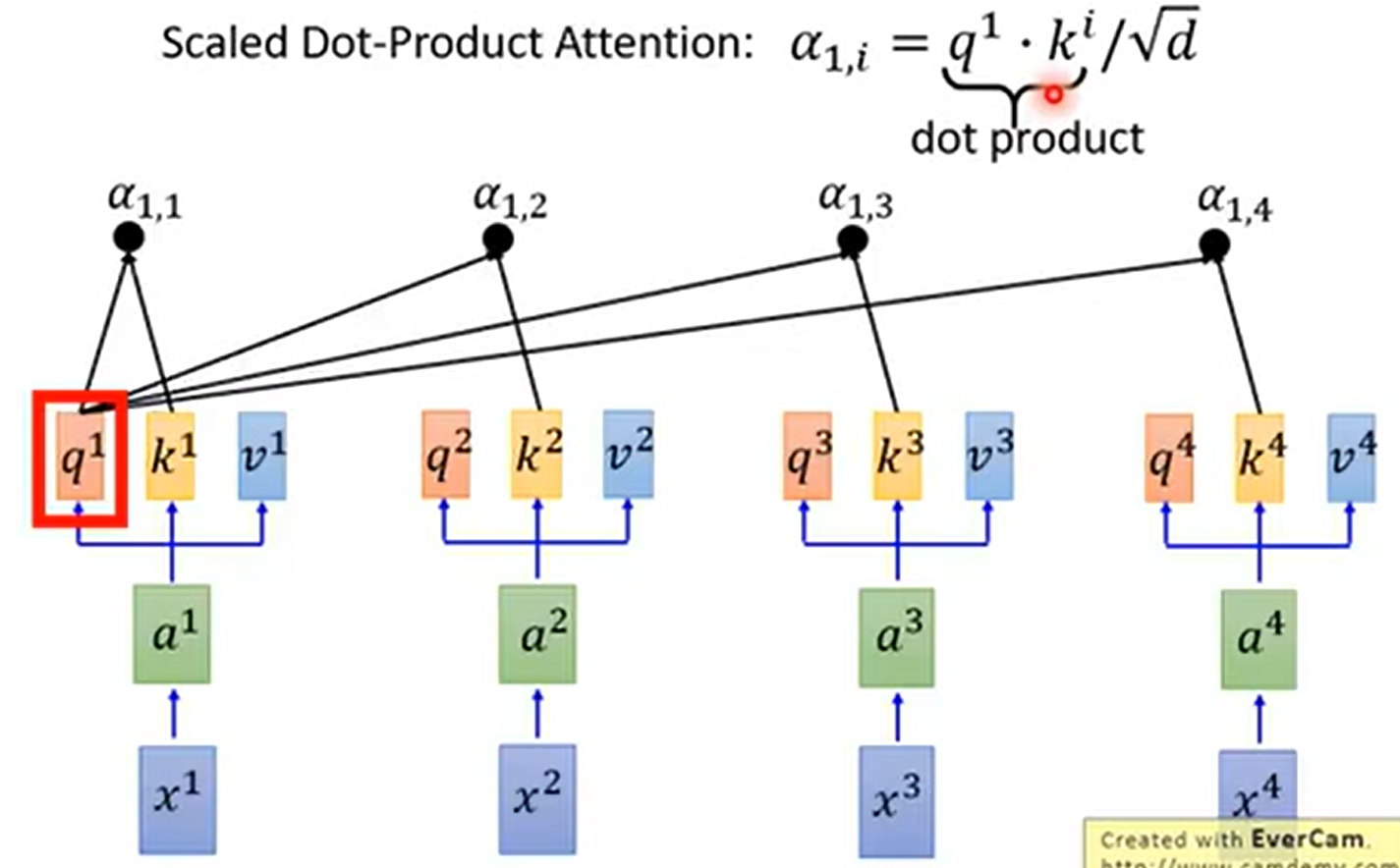
再拿每个 q 去对每个 k 做attention
attention就是输入两个向量,给出这两个向量的匹配程度。也就是拿句子中每个词对当前这个词打分。这些分数(a)决定了在编码当前词的过程中有多重视句子的其他部分。
attention有各式算法,self attention中用的scaled dot-product attention的式子如下所示,其中 d 是 q 和 k 的dimention(因为q 和 k 要做innter product,所以它们的dimension是一样的)。因为如果q 和 k 的dim 越大,那么innter product时,相乘后相加的数值更多,所以除以一个根号 d 来平衡。
再然后将a1,1 到 a1,4 通过一个softmax层,得到a1,1_hat 到 a1,4_hat
softmax分数决定了每个单词对编码当下位置的贡献。
a1,1_hat 到 a1,4_hat 再与之对应的 v 相乘后 求和,得到 b1,即输出sequence的第一个vector
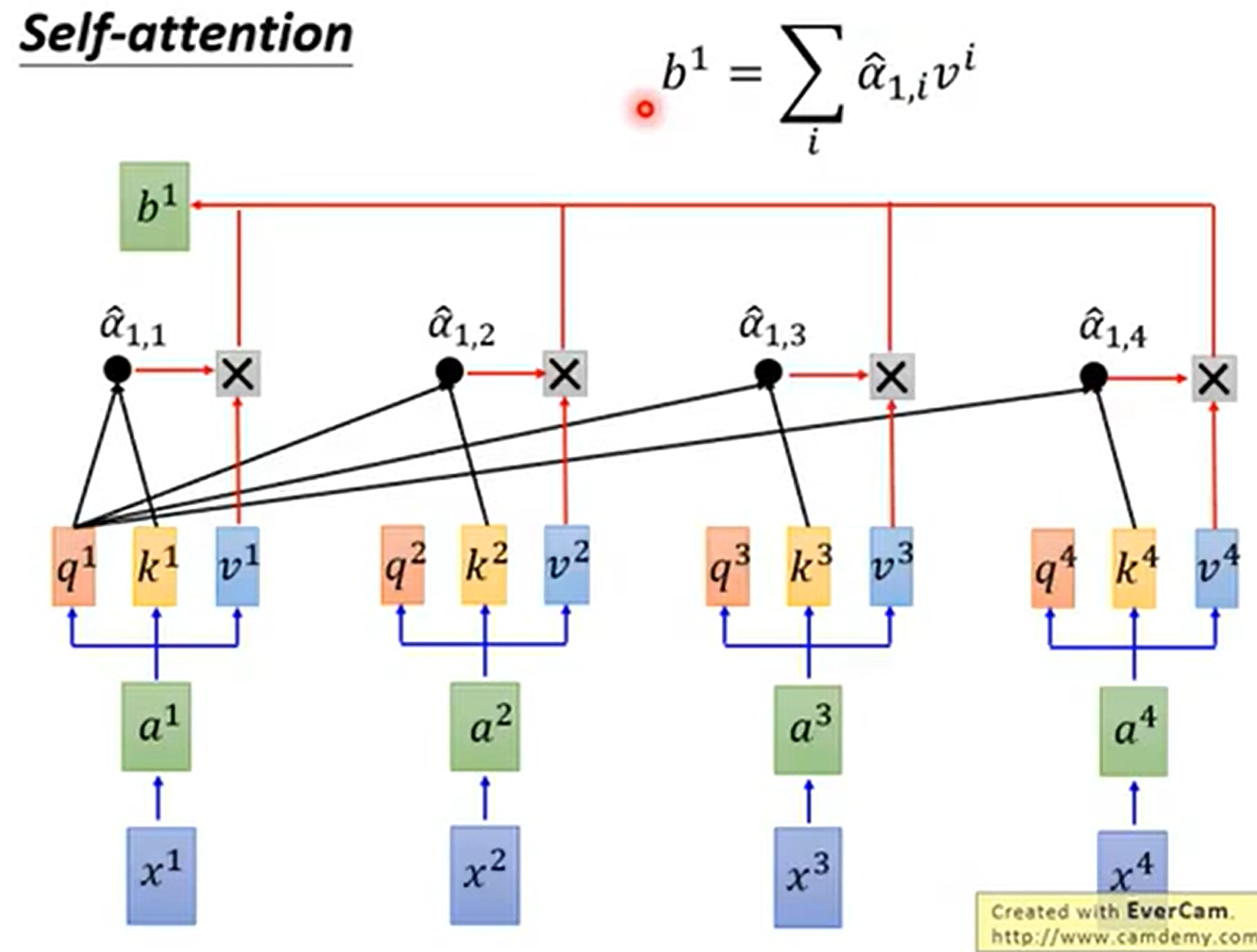
可以发现,产生b1时,我们已经用了整个sequence的信息(a1 到 a4)。如果不想考虑整个句子的信息(global),只想考虑部分(local),可以通过将 a_hat 的值置零来实现。
以此类推,对q2、q3、q4分别做attention,就得到 b2、b3、b4
得到的这些向量再传给前馈神经网络。
以上过程,用矩阵运算的形式表示如下:

用矩阵表示如下右图所示:
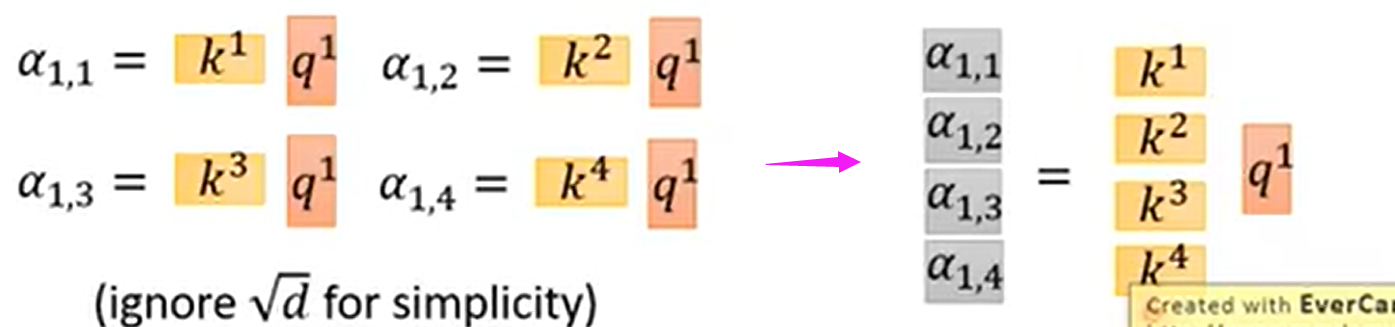
q1到q4的运算,合起来就是:

a_hat的矩阵再乘以V,就得到了output的matrix:b1到b4
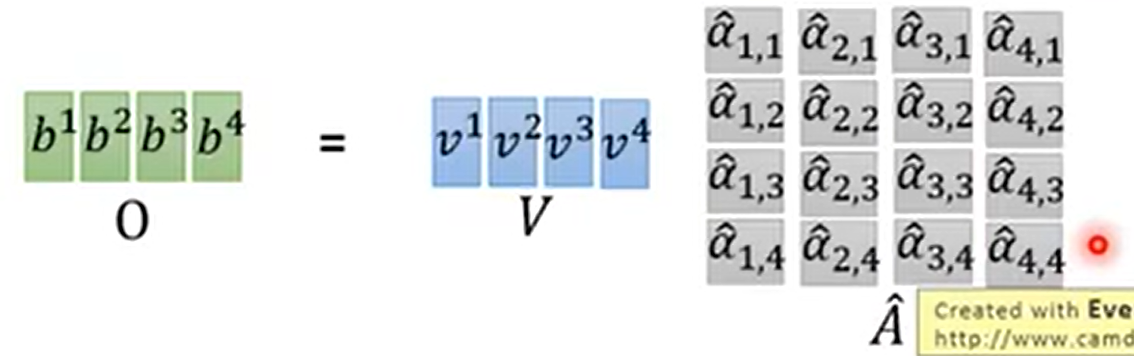
于是整个self-attention的过程合成一个公式,即

以上一系列矩阵运算可以用GPU加速。
补充:
multi-head self-attention
实作时,head的数目是超参,需要自己调整。
每个head保持独立的q、k、v 权重矩阵,也对应产生不同的q、k、v矩阵。每个q只和对应位置的k、v做操作。

如果使用 8 个头,最终会得到 8 个 bi 矩阵。
对于每个单词来说,前馈层不需要 8 个 bi 矩阵,只需要一个 b。 所以我们需要把这 8 个bi 矩阵拼接在一起,然后用一个附加权重矩阵Wo与拼接后的矩阵相乘
使用多头机制,可以从两个方面提高注意力层的性能:
1) 扩展了模型专注于不同位置的能力
2)给出了注意力层的多个“表示子空间”
Positional encoding
因为attention无法捕获序列的顺序,而词序顺序有时候是非常重要的,如翻译任务中单词顺序变动可能产生完全不同的意思。因此引入position encoding:给每个位置一个编号,每个编号对应一个向量。从而每个词向量都会有一个独特的位置向量。
有不同的位置编码算法,不同算法都需解决能够处理未知长度的序列的问题。
所以对每个ai 加上 ei(位置信息),ei是由人工手动设置的。
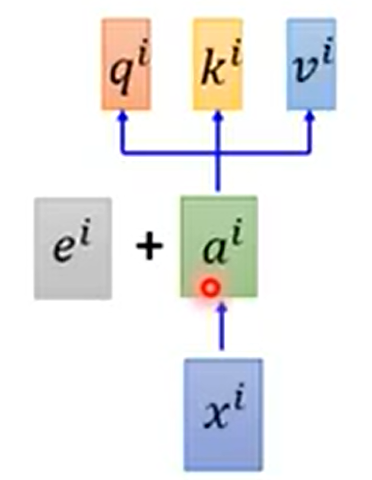
当然也可以在Xi上直接拼接一段位置信息,但经过word embedding 乘以W 后,效果和对ai 加上ei 是一样的。
Transformer整体结构
完整的Transformer结构如下
左边的编码器:
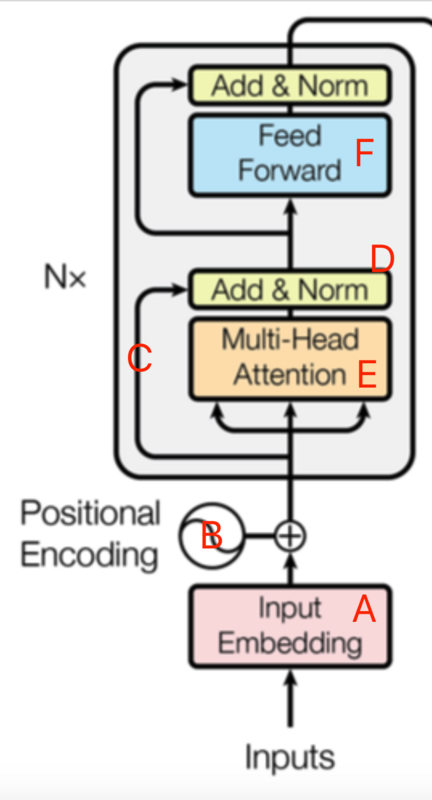
A:通过word2vec等词嵌入方法将语料从onehot转为的embedding维度的词向量
B:加上位置信息
C:残差连接。Encoder中采用了残差网络中的short-cut结构,可减缓深度学习中的退化问题,即网络越深反而训练精度开始下降。
D:Layer-normalization。
F:全连接网络。两个线性函数,一个ReLu激活函数,公式如下:
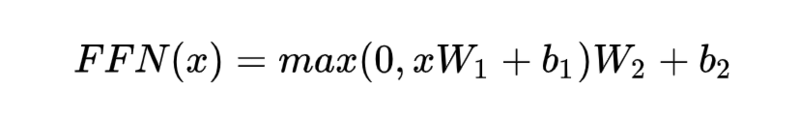
右边的解码器:
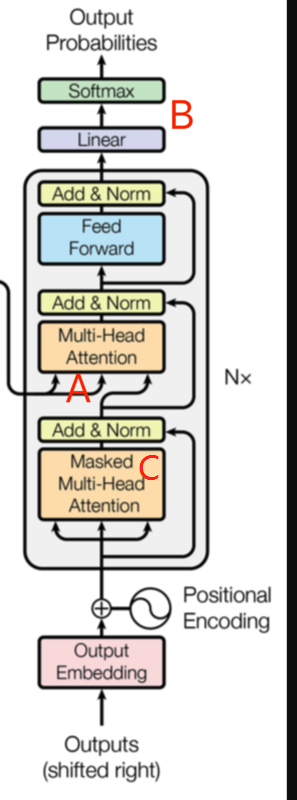
Q 来自于解码器的上一个输出,K 和 V来自于编码器的输出。计算方式与编码器一致。
A:attention计算的内部向量和编码器的输出向量,计算原句和目标句之间的关系
B:线性全连接层,神经元数量和词表长度相等,然后添加softmax层,将概率最高值作为输出。输出后可通过CTC等损失函数训练模型。
C:Masked attention,由于在机器翻译中,解码过程是一个顺序操作过程。即当解码到第K个特征向量时,只能看到 k-1 及其之前的解码结果。这种情况,就叫做masked attention。
解码阶段每个步骤都会输出一个输出序列的元素,接下来重复这个过程,直到到达一个特殊的终止符号。

https://blog.csdn.net/longxinchen_ml/article/details/86533005
Transformer总结
优点:
1)足够创新,抛弃了NLP中最根本的RNN、CNN并取得了不错的效果
2)任意两个单词的距离是1,对解决NLP中棘手的长期依赖问题非常有效
3)算法并行性非常好
缺点:
1)Transformer失去的位置信息在NLP中很重要,虽然加入了位置向量,但对序列位置要求很高的项目表现不好。
2)Transformer可以一步获得全局信息,但如果项目只需要局部信息呢?虽然也可以得到局部信息,但也会增加许多计算量。
https://blog.csdn.net/pipisorry/article/details/84946653
待补充
学习记录用
参考资料:
台大李宏毅老师《机器学习》教程
https://zhuanlan.zhihu.com/p/48508221?utm_source=wechat_session&utm_medium=social&utm_oi=31122683592704
https://blog.csdn.net/longxinchen_ml/article/details/86533005
https://www.jianshu.com/p/e7d8caa13b21