Dropout
随机失活
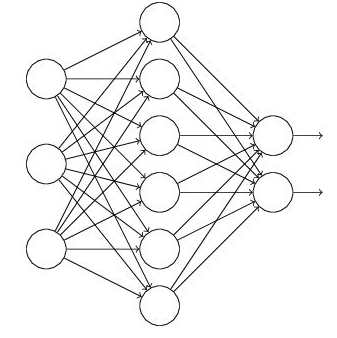
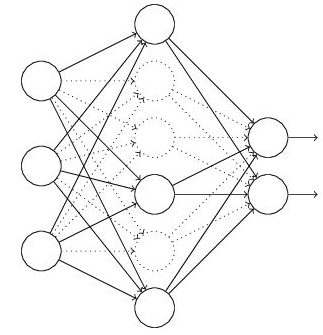
dropout前 dropout后
Training时,加在每次update参数前。貌似一般多用在FC层,CNN层也可以用,不过也不是必须的。因为FC参数多。
网上查的说,一般都是在FC层用dropout。一般不用于卷积层,因为在卷积层中图像相邻像素共享很多相同信息,如某些被删除,它们包含的信息仍可通过其他仍活动的相邻像素传递。简而言之,就是在CNN层加了也没用。
所以卷积层中的dropout只是增加了对噪声输入的鲁棒性,而不是在全连接层中观察到的模型平均效果。
在【实作】food-11中实验了一下,在这个例子下,CNN中用或不用确实没有显著提升。
使用方法如下:


self.cnn = nn.Sequential( nn.Conv2d(3, 64, 3, 1, 1), #[64, 128, 128] nn.BatchNorm2d(64), nn.Dropout(0.1), nn.ReLU(), nn.MaxPool2d(2, 2, 0), #[64, 64, 64] ....., ) self.fc = nn.Sequential( nn.Linear(512*4*4, 1024), nn.Dropout(0.3), nn.ReLU(), nn.Linear(1024, 512), nn.Dropout(0.3), nn.Linear(512, 11) )
- Each neuron都有p%的概率被dropout. 被舍去的神经元的输出全部被设置为0.
- 网络结构会变得更加细长
- 相当于使用新的network来训练。For each mini-batch, training的network是不一样的。
所以加dropout后,
training时的performance会变差,但testing会变好。
如果training本身就很差,那么会更差。
为什么testing会变好?
1)减少神经元之间的共适应关系:阻止了某些特征仅在有其他特定特征下才有效的情况。减少对某些神经元的强依赖,迫使神经网络学习更加鲁棒的特征。
2)Dropout可以看成是一种ensemble。每次sample一部分出来,相当于:
train很多个model,再综合起来。像random forest。
终极emsemble: M neurons -> 2M possible networks ( neurons drop or not drop)
using one mini-batch to train one network, 参数share