一、集合类与数组的区别
1.集合的长度可变,数组的长度固定;
2.集合用来存放对象引用,数组用来存放基本类型的数据;
二、集合类的关系
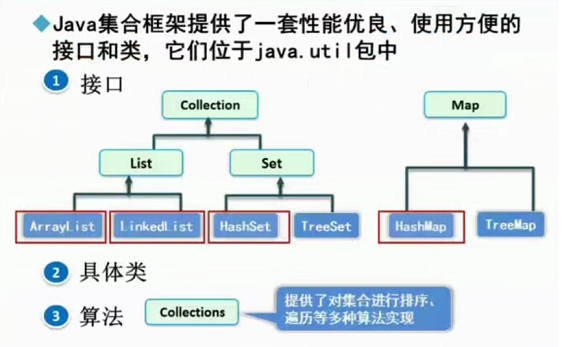
1.Collection接口
存储一组不唯一、无序的对象。
2.List接口
存储一组不唯一、有序(插入顺序)的对象。
2.1 实现类:ArrayList类、LinkedList类
ArrayList类:实现长度可变的数组,在内存中分配连续的空间,遍历元素和随机访问元素的效率较高。
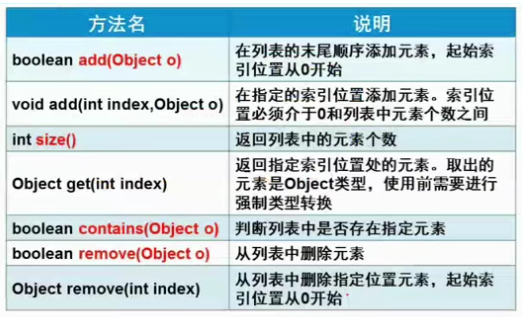
add() addAll() clear() size() iterator() get() set()
LinkedList类:采用链表存储方式,插入、删除元素时效率较高。
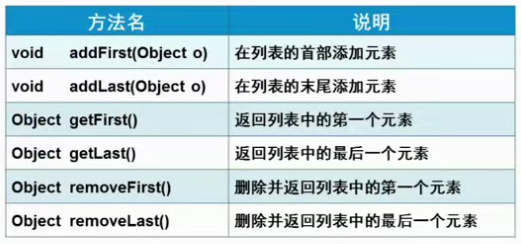
add() addAll() addFirst() addLast() clear() remove() size() iterator() get() set()
3.Set接口
存储一组唯一、无序的对象。
唯一性:在添加对象时,会先采用对象的equals()方法与当前已有的对象的HashCode进行比较(重写了equals()方法的除外),如果没有相同的对象,则添加新的对象。
无序性:没有get()方法,无法通过下标遍历Set集合。
遍历set集合方法:
3.1 通过迭代器Iterator
public static void main(String[] args){ Set<String> set = new HashSet<String>(); set.add("c"); set.add("a"); set.add("c"); set.add("b"); Iterator<String> it = set.iterator(); while (it.hasNext()) { String str = (String) it.next(); System.out.print(str + " "); } }
输出结果:a b c
3.2 增强型for循环
public static void main(String[] args) { Set<String> set = new HashSet<String>(); set.add("c"); set.add("a"); set.add("c"); set.add("b"); for (Object obj : set) { String str = (String) obj; System.out.println(str); } }
输出结果:a b c
4.Map接口
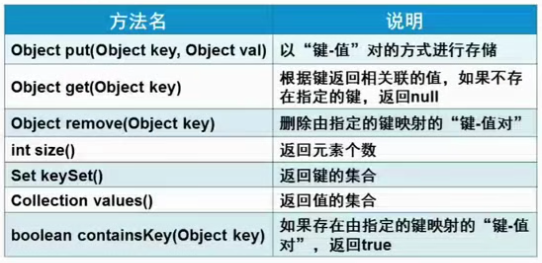
存储一组键值对象,提供key到value的映射。
输出所有的key值:keySet()方法,返回键的Set视图;
输出所有的values值:values()方法,返回值的Collection视图;
获得所有的键值对:entrySet()方法,返回键值对的Set视图。
public static void main(String[] args) { Map<String, String> map = new HashMap<>(); map.put("java", "课堂学习"); map.put("Html", "视频学习"); // 获得所有键值对的集合 Set<Map.Entry<String, String>> entrySet = map.entrySet(); // 集合中对象的类型为Map.Entry
// 方法一:通过增强型for循环 for(Map.Entry<String, String> entry : entrySet) { String key = entry.getKey().toString(); String value = entry.getValue().toString(); System.out.println(key + "---" + value); }
// 方法二:通过迭代器Iterator
Iterator<Map.Entry<String,String>> it1;
it1 = entrySet.iterator();
while(it1.hasNext()){
Map.Entry<String,String> me = it1.next();
String key1 = me.getKey();
String value1 = me.getValues();
System.out.println(key1 + "---" + value1);
}
Iterator<String> it; System.out.println("key值:"); // 获得所有键的集合 Set<String> set = map.keySet(); // 集合中对象的类型为String it = set.iterator(); while (it.hasNext()) { System.out.print(it.next() + " "); } System.out.println(" values值:"); // 获得所有值的集合 Collection<String> coll = map.values(); // 集合中对象的类型为String it = coll.iterator(); while (it.hasNext()) { System.out.print(it.next() + " "); } }
4.1 实现类
HashMap、Hashtable、LinkedHashMap和TreeMap
HashMap
HashMap是最常用的Map,它根据键的HashCode值存储数据,根据键可以直接获取它的值,具有很快的访问速度,遍历时,取得数据的顺序是完全随机的。因为键对象不可以重复,所以HashMap最多只允许一条记录的键为Null,允许多条记录的值为Null,是非同步的。
Hashtable
Hashtable与HashMap类似,是HashMap的线程安全版,它支持线程的同步,即任一时刻只有一个线程能写Hashtable,因此也导致了Hashtale在写入时会比较慢,它继承自Dictionary类,不同的是它不允许记录的键或者值为null,同时效率较低。
ConcurrentHashMap
线程安全,并且锁分离。ConcurrentHashMap内部使用段(Segment)来表示这些不同的部分,每个段其实就是一个小的HashTable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。
LinkedHashMap
LinkedHashMap保存了记录的插入顺序,在用Iteraor遍历LinkedHashMap时,先得到的记录肯定是先插入的,在遍历的时候会比HashMap慢,有HashMap的全部特性。
TreeMap
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按键值的升序排序(自然顺序),也可以指定排序的比较器,当用Iterator遍历TreeMap时,得到的记录是排过序的。不允许key值为空,非同步的。