一、什么是Pandas
Pandas,python+data+analysis的组合缩写,是python中基于numpy和matplotlib的第三方数据分析库,与后两者共同构成了python数据分析的基础工具包,享有数分三剑客之名。
Pandas 的目标是成为 Python 数据分析实践与实战的必备高级工具,其长远目标是成为最强大、最灵活、可以支持任何语言的开源数据分析工具。
- 高性能
- 易使用的数据结构
- 易使用的数据分析工具
python 社区已经广泛接受了一些常用模块的命名惯例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
也就是说,当你看到np.arange时,就应该想到它引用的是NumPy中的arange函数。这样做的原因是:在Python软件开发中,不建议直接引入类似NumPy这种大型库的全部内容(from numpy import *)。
二、Pandas数据读取
1、读取txt、CSV等文本数据
1.1 按照逗号分割的txt文本文件
df = pd.read_csv('C:\\Users\\ywx1106919\\Desktop\\ex1.txt', encoding='utf-8')
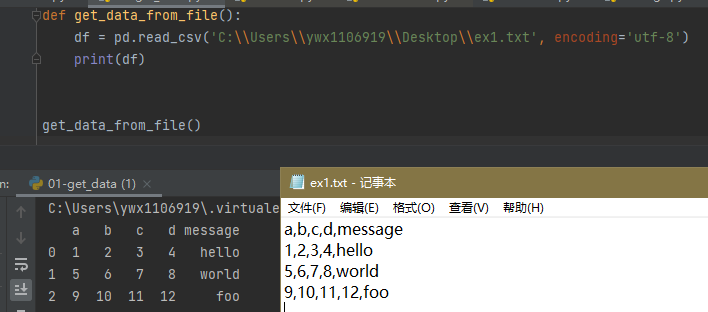
1.2 按照tab分割的csv文件
df = pd.read_table('C:\\Users\\ywx1106919\\Desktop\\ex2.csv', encoding='utf-8')
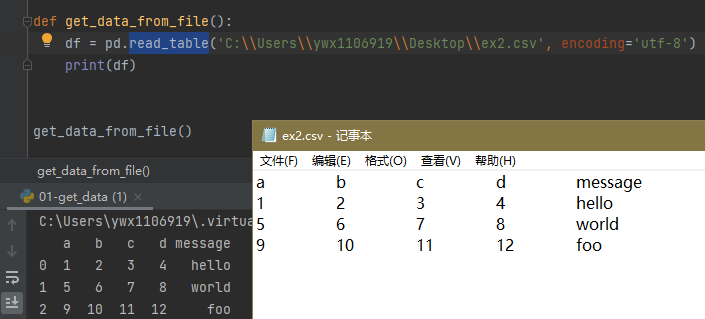
1.3 常用方法总结:
| 函数 | 说明 |
| read_csv | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为逗号。 |
| read_table | 从文件、URL、文件型对象中加载带分隔符的数据。默认分隔符为制表符(“\t”)。 |
| read_fwf | 读取定宽列格式数据(也就是说,没有分隔符) |
| read_clipboard | 读取剪贴板中的数据,可以看做read_table的剪切板版。在将网页转换成表格时很有用。 |
1.4 抛砖引玉,后面有机会详细介绍
- 我们可以通过sep参数修改默认分隔符。
- 我们可以通过header参数申明标题行。
- 我们可以通过names参数自定制列名。
- 我们可以通过index_col参数设置索引列。
2、读取Excel中数据
ps:使用read_excel 需要安装openpyxl包
pip install openpyxl
2.1 读取Excel文件
df = pd.read_excel('C:\\Users\\ywx1106919\\Desktop\\ex3.xlsx')
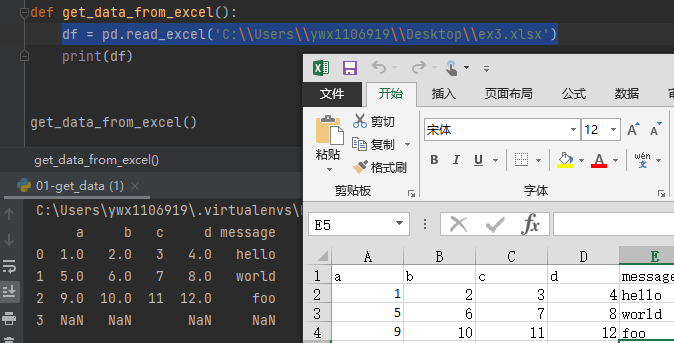
3、读取数据库中数据
3.1 读取MySQL数据库中数据
ps:使用mysql数据库需要安装mysqlclient、pymysql包
pip install pymysql
pip install mysqlclient
conn = pymysql.connect(host=MYSQL_HOST, port=MYSQL_PORT, db=MYSQL_NAME, user=MYSQL_USER, password=MYSQL_PASSWORD, ) mysql_page = pd.read_sql("SELECT id,subject_name FROM tb_course", con=conn)
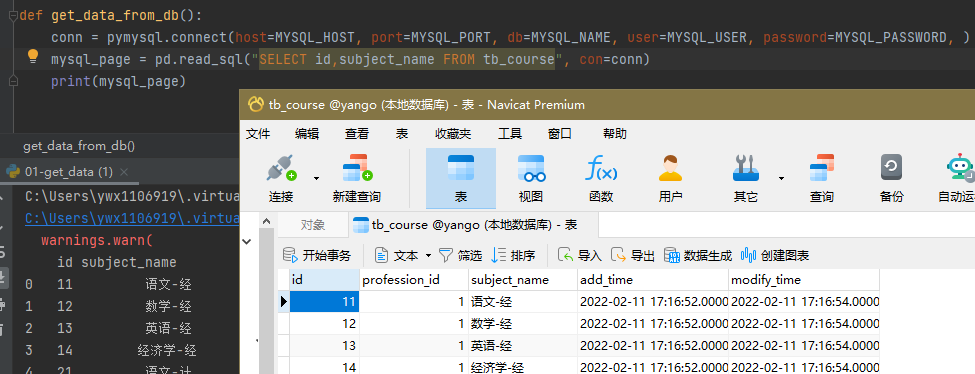
3.2 彩蛋:旧版本获取数据会有警告提示:
UserWarning: pandas only support SQLAlchemy connectable(engine/connection) ordatabase string URI or sqlite3 DBAPI2 connectionother DBAPI2 objects are not tested, please consider using SQLAlchemy warnings.warn(
新版本的pandas库中con参数使用sqlalchemy库创建的create_engine对象 。创建create_engine对象(格式类似于URL地址),
需要安装 sqlalchemy


def get_data_from_db(): """ 新版本的pandas库中con参数使用sqlalchemy库创建的create_engine对象 创建create_engine对象(格式类似于URL地址): """ engine = create_engine('mysql+pymysql://%s:%s@%s:%s/%s?charset=utf8' % (MYSQL_USER, MYSQL_PASSWORD, MYSQL_HOST, MYSQL_PORT, MYSQL_NAME)) mysql_page = pd.read_sql("SELECT * FROM tb_score", engine) print(mysql_page)
三、Pandas数据结构
要使用pandas,首先就得熟悉它的两个主要数据结构:Series和DataFrame。虽然它们并不能解决所有问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
Series
Series是类似于一维数组的对象。它由一组数据(可以是不同数据类型)以及一组与之相关的额数据标签(索引)组成。
1:一组数据即可产生最简单的Series
import pandas as pd def series_01(): pd_s = pd.Series([4, 7, -5, 3]) print(pd_s) print(pd_s[3]) series_01()
0 4
1 7
2 -5
3 3
dtype: int64
3
取值方式:通过索引取值。python中的切片功能同样适用。
展示形式:索引在左,值在右。
我们没有为数据指定索引,于是会自动创建一个0至N-1的整数索引。你可以通过Series的index和values获取其索引对象和数组表示形式
2:一组数据+索引组成的Series
通常,我们希望所创建的Series带有一个可以对各个数据点进行标记的索引。
def series_02(): # 创建一个可以对各个数据进行标记的索引 pd_s = pd.Series([4, 7, -5, 3], index=["d", "b", "a", "c"]) print(pd_s) print("------通过下标取值---------") print(pd_s[1:3]) print("------通过索引取值---------") print(pd_s[["a", "b", "c"]]) print("-------查看索引--------") print(pd_s.index) print("-------查看值--------") print(pd_s.values)
d 4 b 7 a -5 c 3 dtype: int64 ------通过下标取值--------- b 7 a -5 dtype: int64 ------通过索引取值--------- a -5 b 7 c 3 dtype: int64 -------查看索引-------- Index(['d', 'b', 'a', 'c'], dtype='object') -------查看值-------- [ 4 7 -5 3]
你可以通过索引的方式选取Series中的单个或一组值。上面展示了通过 pd_s[["a", "b", "c"]] 取一组值,可通过pd_s["a"]取单个值。
3:数学运算
常见的数学运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引和值之间的链接。
def series_03(): pd_s = pd.Series([4, 7, -5, 3], index=["d", "b", "a", "c"]) print(pd_s) print("------布尔型数组过滤---------") print(pd_s[pd_s > 0]) print("------标量乘法---------") print(pd_s * 2) print("-------应用数学函数--------") # exp():返回e的幂次方,e是一个常数为2.71828。np.exp(1) 为自身,np.exp(2) 为平方 print(np.exp(pd_s))
d 4 b 7 a -5 c 3 dtype: int64 ------布尔型数组过滤--------- d 4 b 7 c 3 dtype: int64 ------标量乘法--------- d 8 b 14 a -10 c 6 dtype: int64 -------应用数学函数-------- d 54.598150 b 1096.633158 a 0.006738 c 20.085537 dtype: float64
4:Series可以看成一个定长的有序字典。
Series它本身是索引值到数据值的一个映射。
def series_04(): dict_data = {"张三": 20, "李四": 22, "王五": 23, "赵六": 20} pd_s = pd.Series(dict_data) # 字典直接转 print(pd_s) print("------布尔判断是否存在---------") print("张三" in dict_data, "张三三" in dict_data) print("------查看索引---------") print(pd_s.index) print("-------给索引通过赋值的方式就地修改--------") pd_s.index = ["zhangsan", "lisi", "wangwu", "zhaoliu"] print(pd_s)
张三 20 李四 22 王五 23 赵六 20 dtype: int64 ------布尔判断是否存在--------- True False ------查看索引--------- Index(['张三', '李四', '王五', '赵六'], dtype='object') -------给索引通过赋值的方式就地修改-------- zhangsan 20 lisi 22 wangwu 23 zhaoliu 20 dtype: int64
DataFrame
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等),可对应数据库中的字段。
DataFrame 既有行索引又有列索引,它可以被看做由Series组成的字典。
1:根据多个字典序列创建dataframe
构建DataFrame的方法有很多最常用的一种是直接传入一个由等长列表或者NumPy数组组成的字典。
def data_frame_01(): data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data) print(frame) data_frame_01()
""" name year pop 0 张三 2020 3 1 李四 2021 2 2 王五 2022 1 3 赵六 2023 4 """
从数据结果可以看出,DataFrame会自动加上索引。同样的,我们可以指定列的顺序和自定义索引。
def data_frame_02(): data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) print(frame)
pop year name age one 3 2020 张三 NaN two 2 2021 李四 NaN three 1 2022 王五 NaN four 4 2023 赵六 NaN
跟Series一样如果传入的列在数据中找不到,就会产生NA值。
2:从dataframe中查出Series
如果只查询一行、一列返回的是series。
-
- 列筛选:通过类似字典标记的方式或属性的方式 frame['pop']
- 行筛选:通过行号获取行 frame.iloc[1]
- 行筛选:通过索引获取行 frame.loc['one']
def data_frame_03(): # 如果只查询一行、一列返回的是series。 # 列筛选:通过类似字典标记的方式或属性的方式 frame['pop'] # 行筛选:通过行号获取行 frame.iloc[1] # 行筛选:通过索引获取行 frame.loc['one'] data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) a_col = frame['pop'] print("-------------获取某列----------") print(a_col) a_row_by_iloc = frame.iloc[1] print("-------------通过行号获取行----------") print(a_row_by_iloc) a_row_by_loc = frame.loc['one'] print("-------------通过索引获取行----------") print(a_row_by_loc)
-------------获取某列---------- one 3 two 2 three 1 four 4 Name: pop, dtype: int64 -------------通过索引获取行---------- pop 2 year 2021 name 李四 age NaN Name: two, dtype: object -------------通过行号获取行---------- pop 3 year 2020 name 张三 age NaN Name: one, dtype: object
如果查询多行,返回的仍是DataFrame。
-
- 列筛选:通过类似字典标记的方式或属性的方式 frame[['pop'], ['year']]
- 行筛选:通过索引获取行 frame.loc[['one', 'three']]
- 行筛选:通过行号获取多行 fram.iloc[0:2]
def data_frame_03_n(): # 如果查询多行,返回的仍是DataFrame。 # 列筛选:通过类似字典标记的方式或属性的方式 frame[['pop'], ['year']] # 行筛选:通过索引获取行 frame.loc[['one', 'three']] # 行筛选:通过行号获取多行 fram.iloc[0:2] data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) m_col = frame[['pop', 'year']] print("-------------获取多列----------") print(m_col) m_row_by_iloc = frame.iloc[0:2] print("-------------通过行号获取多行----------") print(m_row_by_iloc) m_row_by_loc = frame.loc[['one', 'three']] print("-------------通过索引获取行----------") print(m_row_by_loc)
-------------获取多列---------- pop year one 3 2020 two 2 2021 three 1 2022 four 4 2023 -------------通过行号获取多行---------- pop year name age one 3 2020 张三 NaN two 2 2021 李四 NaN -------------通过索引获取行---------- pop year name age one 3 2020 张三 NaN three 1 2022 王五 NaN
3:dataframe修改
一言以蔽之:获取目标,赋值
def data_frame_03_m(): data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) frame['age'] = 18 print("-------------获取某列,然后统一赋一个值----------") print(frame) frame['age'] = np.arange(4, ) print("-------------获取某列,然后赋一个(可递归)值----------") print(frame) val = pd.Series([17, 18], index=['one', 'three', ]) frame['age'] = val print("-------------定义Series【值和索引对应】----------") print(frame)
-------------获取某列,然后统一赋一个值---------- pop year name age one 3 2020 张三 18 two 2 2021 李四 18 three 1 2022 王五 18 four 4 2023 赵六 18 -------------获取某列,然后赋一个(可递归)值---------- pop year name age one 3 2020 张三 0 two 2 2021 李四 1 three 1 2022 王五 2 four 4 2023 赵六 3 -------------定义Series【值和索引对应】---------- pop year name age one 3 2020 张三 17.0 two 2 2021 李四 NaN three 1 2022 王五 18.0 four 4 2023 赵六 NaN
4:dataframe新增一个列
为不存在的列赋值会创建一个新列。
def data_frame_03_a(): data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) val = pd.Series([17, 18], index=['one', 'three', ]) frame['age'] = val print("-------------定义Series【值和索引对应】----------") print(frame) frame["has_age"] = frame.age > 0 print(frame)
-------------定义Series【值和索引对应】---------- pop year name age one 3 2020 张三 17.0 two 2 2021 李四 NaN three 1 2022 王五 18.0 four 4 2023 赵六 NaN pop year name age has_age one 3 2020 张三 17.0 True two 2 2021 李四 NaN False three 1 2022 王五 18.0 True four 4 2023 赵六 NaN False
5:dataframe 删除列
关键字del用于删除列。
def data_frame_03_d(): data = { 'name': ['张三', '李四', '王五', '赵六'], 'year': [2020, 2021, 2022, 2023], 'pop': [3, 2, 1, 4], } frame = pd.DataFrame(data, columns=['pop', 'year', 'name', 'age'], index=['one', 'two', 'three', 'four']) del frame["pop"] print(frame)
year name age one 2020 张三 NaN two 2021 李四 NaN three 2022 王五 NaN four 2023 赵六 NaN
6:loc和iloc
- loc的意思是基于标签(label-based selection),输入为标签。在对数据进行切片操作时,loc与Python中 (:)的含义有差异,左闭右闭
- iloc的意思是基于索引(index-based selection),输入为索引。在对数据进行切片操作时,iloc与Python中 (:)的含义相同,左闭右开
def data_frame_03_di(): # 另外一种常见的数据形式是嵌套字典,外层字典的键作为列,内层键作为行索引 # loc的意思是基于标签(label-based selection),输入为标签。在对数据进行切片操作时,loc与Python中 (:)的含义有差异,左闭右闭 # iloc的意思是基于索引(index-based selection),输入为索引。在对数据进行切片操作时,iloc与Python中 (:)的含义相同,左闭右开 data = { "name": {1: "张三", 3: "李四", 5: "王五", 7: "赵六"}, "year": {1: 2020, 3: 2021, 5: 2022, 7: 2023}, "pop": {1: 3, 3: 2, 5: 1, 40: 4} } frame = pd.DataFrame(data) print(frame) m1_row_by_iloc = frame.iloc[0:3, 1] print("-------------通过行号获取多行----------") print(m1_row_by_iloc) m2_row_by_iloc = frame.loc[0:3, 'year'] print("-------------通过行号获取多行----------") print(m2_row_by_iloc)
name year pop 1 张三 2020.0 3.0 3 李四 2021.0 2.0 5 王五 2022.0 1.0 7 赵六 2023.0 NaN 40 NaN NaN 4.0 -------------通过行号获取多行---------- 1 2020.0 3 2021.0 5 2022.0 Name: year, dtype: float64 -------------通过行号获取多行---------- 1 2020.0 3 2021.0 Name: year, dtype: float64