又到了一年一度的新生入学季了,清华和北大的计算机系同学都参加了同一场开学考试(因为两校兄弟情谊深厚嘛,来一场联考还是很正常的)。
不幸的是,正当老师要统计大家的成绩时,世界上的所有计算机全部瘫痪了。
“计算机坏了,可计算机系还得办。小 K,你去了解一下大家的成绩,顺便数数今年两校计算机系有多少人吧!”
于是,小 K 来到了人群中,开始调查大家的成绩。
然而,同学们只有七秒钟的记忆,已经忘记了自己的具体成绩(这可真是尴尬啊)。
但是,因为在忘记成绩之前和校友互相调侃过,他们清楚地记得 在自己的学校里,有多少人(不包括自己)拥有和自己相同的成绩。
但是,清北的学生实在是太多了,小 K 询问了 NNN 个人之后,就已经精疲力尽了。
“怎么办呢?唉,小 Y,你来帮我算一下 两校一共 最少有多少学生吧,我就把这个数字报上去。”
“额 (⊙﹏⊙)”
你没猜错,你就是可怜的小 Y。现在请你来解决这个问题吧!
输入格式
第一行两个数字 N,MN,MN,M,其中 NNN 表示小 K 一共询问了 NNN 名学生,MMM 的意义见下文。
第二行有 N100frac{N}{100}100N 个数字,用来生成每名被询问同学的反馈情况(这些数字用作数据生成器的种子,数据的具体生成方法见下文)。
输出格式
输出只有一行,包含一个数字,表示两校一共的最少人数。
数据范围
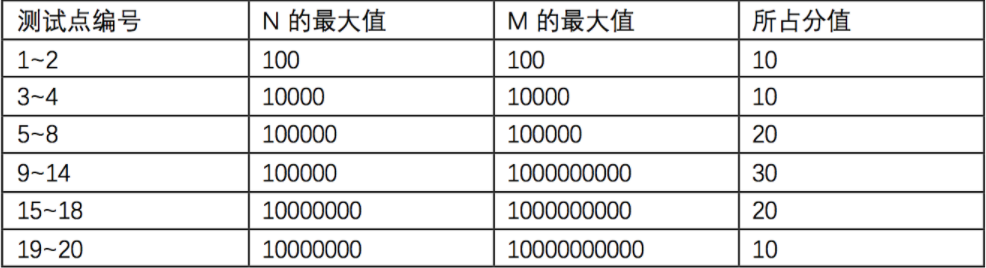
关于数据生成器的说明
因为 NNN 可能比较大,为了避免读入花费过多时间,我们采用数据生成器的方式给出每名被询问学生的反馈结果(即在他的学校中,有多少人和他成绩相同)。
输入中的每个种子 seedseedseed,用来生成 100100100 个数字,设第 iii 个数字为 AiA_iAi,则
A1=seeddisplaystyle A_1=seedA1=seed
Ai=(Ai−1×109+107)modMdisplaystyle A_i=(A_{i-1} imes 109+107)mod MAi=(Ai−1×109+107)modM
生成的这 100100100 个数字就是被询问的 100100100 名学生的反馈结果。
当然,我们保证 NNN 是 100100100 的倍数。
关于细节问题的说明
为了防止选手不能正确理解题意,在此对具体题意以及一些上文中未提到的细节之处做一些说明。
为什么答案不是 NNN 呢?你不是说了有 NNN 名学生了吗?”。事实上,NNN 只是小 KKK 询问到的学生数目,并不是两校真正的学生数目!真正的学生数目是未知的。
那第 iii 名学生到底是清华的还是北大的啊?回答是 “小 K 不知道啊,这是你要合理安排的事情啊!”。让答案最小就是你的目标,为此你要考虑是把他安排在清华好,还是安排在北大好。
MMM 是否是质数?既然题目没说,那就不一定是质数,请选手考虑周全。
seedseedseed 是否小于 MMM?我们保证每个测试点的 seedseedseed 都是小于该测试点的 MMM 的。
关于测试数据。我们的数据是基本随机的,请放心选择随机化算法,并分析其时间复杂度及空间复杂度。
最后,为什么没有 样例数据 呢?(计蒜客老师加了一组样例)。 真不是出题人不想给你们,最小的数据也要有 100100100 名学生,这根本没法写样例解释嘛! 所以,我们在下面给出一组解密后的样例,并做出解析。请注意 该样例不符合格式。
小 K 一共采访到了 555 名同学,他们的反馈结果分别是 1,1,2,2,31,1,2,2,31,1,2,2,3。 那么,最优解应当为 999,我们在下面给出一个表格,表示最优解的详细情况。
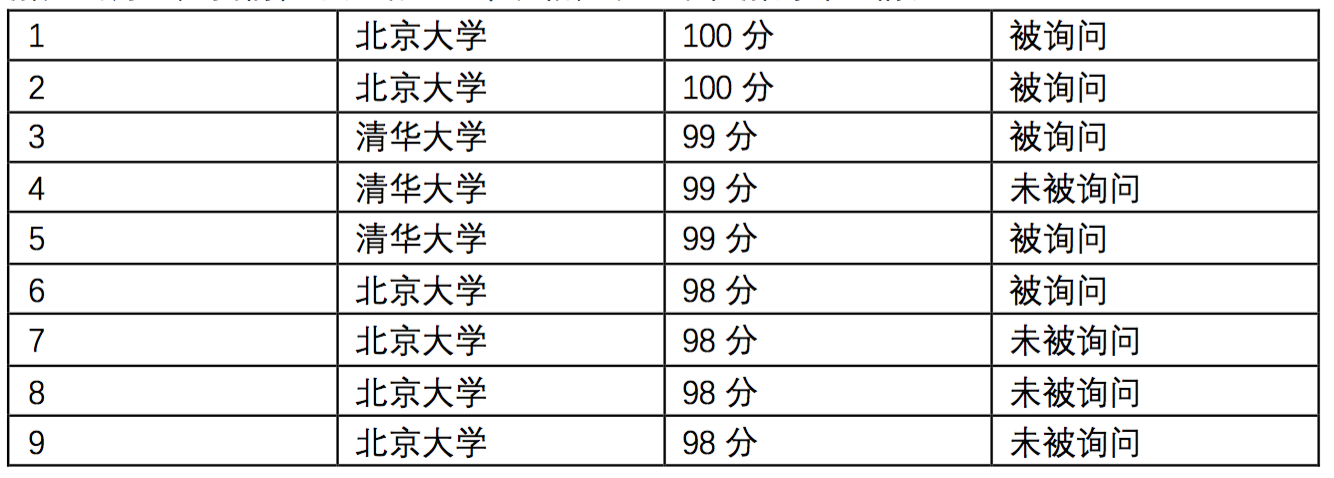
祝大家顺利通过此题,在比赛中取得好成绩,进入理想的学府!
忽略每行输出的末尾多余空格
样例输入
100 100 1
样例输出
179
首先,不难发现把所有学生都安排到一所学校里就可以得到最优答案。
本题的关键其实就是把一些反馈数字相同的人组合在一起。比如两个人的反馈数字都是 1 ,那
么你可以安排这两人的分数相同
严谨一点的叙述就是,如果有 v 个人的反馈数字都是 k ,那么这些人对答案的实际贡献是大
于等于 v 的最小 k+1 的倍数,可以写为
$$ans+={lceil {v over {k+1}} ceil} *(k+1)$$
统计每种数字的出现次数用hash
1 #include<iostream> 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 using namespace std; 6 typedef long long lol; 7 const int N=1e7+5; 8 const int M=1e9+5; 9 lol n,m,seed,a,h[N],v[N],ans; 10 void push_hash(lol x) 11 { 12 lol pos=x%N; 13 while (h[pos]!=x&&h[pos]!=0) 14 { 15 pos++; 16 if (pos>=N) pos=1; 17 } 18 if (h[pos]==0) 19 {v[pos]=1;h[pos]=x;} 20 else {v[pos]++;} 21 } 22 int main() 23 {int i,j; 24 cin>>n>>m; 25 for (i=1;i<=n/100;i++) 26 { 27 scanf("%lld",&seed); 28 a=seed; 29 for (j=1;j<=100;j++) 30 { 31 push_hash(a+1); 32 a=(a*109+107)%m; 33 } 34 } 35 for (i=0;i<N;i++) 36 if (h[i]) 37 { 38 ans+=((v[i]+h[i]-1)/h[i])*h[i]; 39 } 40 cout<<ans; 41 }
又到了一年一度的新生入学季了,清华和北大的计算机系同学都参加了同一场开学考试(因为两校兄弟情谊深厚嘛,来一场联考还是很正常的)。
不幸的是,正当老师要统计大家的成绩时,世界上的所有计算机全部瘫痪了。
“计算机坏了,可计算机系还得办。小 K,你去了解一下大家的成绩,顺便数数今年两校计算机系有多少人吧!”
于是,小 K 来到了人群中,开始调查大家的成绩。
然而,同学们只有七秒钟的记忆,已经忘记了自己的具体成绩(这可真是尴尬啊)。
但是,因为在忘记成绩之前和校友互相调侃过,他们清楚地记得 在自己的学校里,有多少人(不包括自己)拥有和自己相同的成绩。
但是,清北的学生实在是太多了,小 K 询问了 NNN 个人之后,就已经精疲力尽了。
“怎么办呢?唉,小 Y,你来帮我算一下 两校一共 最少有多少学生吧,我就把这个数字报上去。”
“额 (⊙﹏⊙)”
你没猜错,你就是可怜的小 Y。现在请你来解决这个问题吧!
输入格式
第一行两个数字 N,MN,MN,M,其中 NNN 表示小 K 一共询问了 NNN 名学生,MMM 的意义见下文。
第二行有 N100frac{N}{100}100N 个数字,用来生成每名被询问同学的反馈情况(这些数字用作数据生成器的种子,数据的具体生成方法见下文)。
输出格式
输出只有一行,包含一个数字,表示两校一共的最少人数。
数据范围
关于数据生成器的说明
因为 NNN 可能比较大,为了避免读入花费过多时间,我们采用数据生成器的方式给出每名被询问学生的反馈结果(即在他的学校中,有多少人和他成绩相同)。
输入中的每个种子 seedseedseed,用来生成 100100100 个数字,设第 iii 个数字为 AiA_iAi,则
A1=seeddisplaystyle A_1=seedA1=seed
Ai=(Ai−1×109+107)modMdisplaystyle A_i=(A_{i-1} imes 109+107)mod MAi=(Ai−1×109+107)modM
生成的这 100100100 个数字就是被询问的 100100100 名学生的反馈结果。
当然,我们保证 NNN 是 100100100 的倍数。
关于细节问题的说明
为了防止选手不能正确理解题意,在此对具体题意以及一些上文中未提到的细节之处做一些说明。
为什么答案不是 NNN 呢?你不是说了有 NNN 名学生了吗?”。事实上,NNN 只是小 KKK 询问到的学生数目,并不是两校真正的学生数目!真正的学生数目是未知的。
那第 iii 名学生到底是清华的还是北大的啊?回答是 “小 K 不知道啊,这是你要合理安排的事情啊!”。让答案最小就是你的目标,为此你要考虑是把他安排在清华好,还是安排在北大好。
MMM 是否是质数?既然题目没说,那就不一定是质数,请选手考虑周全。
seedseedseed 是否小于 MMM?我们保证每个测试点的 seedseedseed 都是小于该测试点的 MMM 的。
关于测试数据。我们的数据是基本随机的,请放心选择随机化算法,并分析其时间复杂度及空间复杂度。
最后,为什么没有 样例数据 呢?(计蒜客老师加了一组样例)。 真不是出题人不想给你们,最小的数据也要有 100100100 名学生,这根本没法写样例解释嘛! 所以,我们在下面给出一组解密后的样例,并做出解析。请注意 该样例不符合格式。
小 K 一共采访到了 555 名同学,他们的反馈结果分别是 1,1,2,2,31,1,2,2,31,1,2,2,3。 那么,最优解应当为 999,我们在下面给出一个表格,表示最优解的详细情况。
祝大家顺利通过此题,在比赛中取得好成绩,进入理想的学府!
忽略每行输出的末尾多余空格
样例输入
100 100 1
样例输出
179