作业要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3339
本案例主要分析在豆瓣爬取的《三体》短评数据,数据字段包括地址、评论时间、评论内容、评价程度、用户名和投票数6个属性值,将数据上传到hdfs的hive数据仓库中进行简要分析。
一、建立一个运行本案例的目录bigdatacase、dataset:


将文本拷贝到dataset目录下并查看文件:


二、预处理文件,将csv生成txt文件:
1、删除第一行字段:
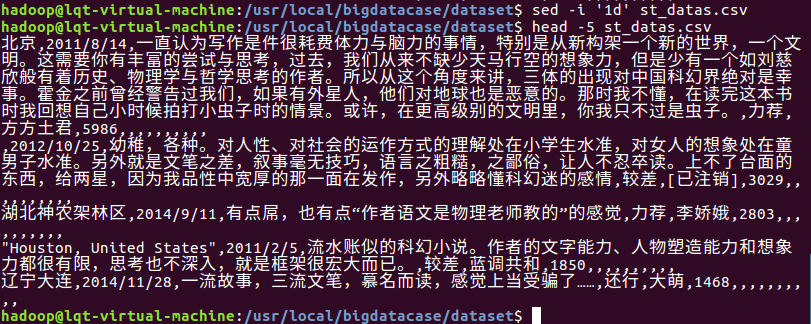
2、预处理字段:
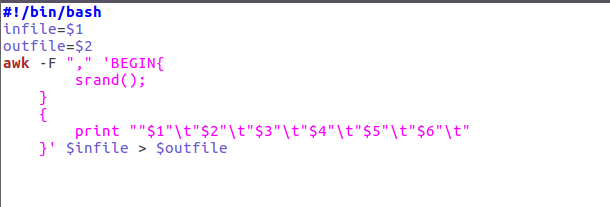
每个字段用 隔开,这里有6个字段。
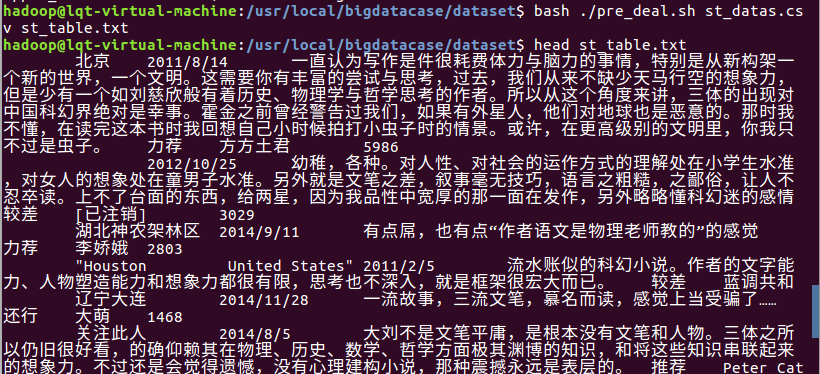
三、将文本文件上传到hive:
1、启动hdfs:

2、在HDFS上建立/bigdatacase/dataset文件夹,将文件上传:




3、启动mysql:
4、在hive中创建数据库dblab:

5、在把hdfs中的“/bigdatabase/dataset”目录下的数据加载到了数据仓库的hive中的:

(在这里遇到了一个问题就是,如果出现以下情况,则修改下字段名称,这里我将date改成riqi就可以了):

6、在hive中查看数据,查找表的前10条记录:

四、Hive数据分析:
(因为上面那张边st_table分析的时候有错误分析不正确,故删除重复上述步骤新建st3.txt文本文件,以下采用st3表,并且该文本文件因为事先已经排序好,故这里不进行排序)
1、查询不重复的用户名:

通过distinct username 查询出不重复的用户名有多少1871个,总数量2000左右,说明大部分还是比较真实的,但也有部分刷评论的。
2、查询投票数前20的评价程度:
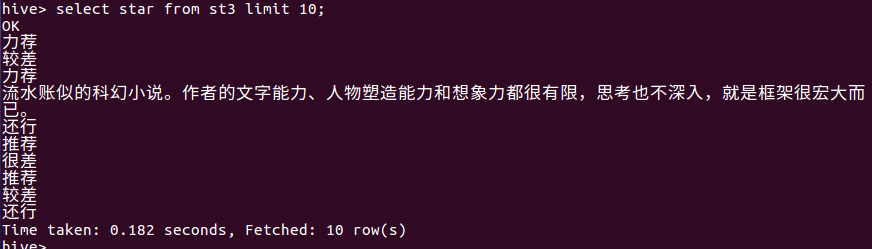
查询结果显示大部分还是呈“推荐”趋势的。
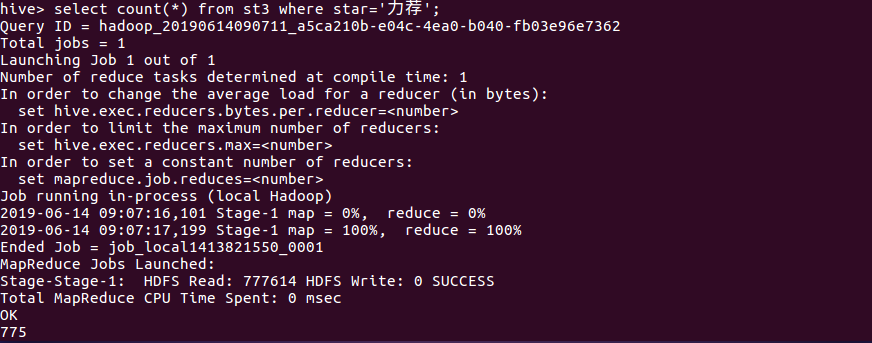
3、查询评价为“力荐”的数量:
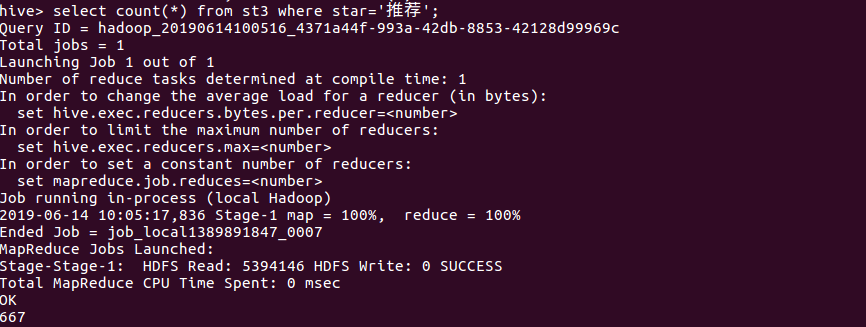
4、查询评价为“推荐”的数量:
5、查询评价为“较差”的数量:

6、查询评价为“很差”的数量:

通过3、4、5、6的查询可以得出推荐和力荐的总数量达1442,占总比的72%,较差和很差的数量占总数的3.1%,说明大部分还是给了好评居多。
7、查询前10的用户所在的城市:


通过分组排序并且去除“关注此人”这个脏数据后,查询用户所在城市,大部分还是集中在一线城市,说明评论的还是有一定的可信度的,毕竟一线城市的用户平均阅读水平较高。
8、查询投票数最高的前20的用户的评论时间:
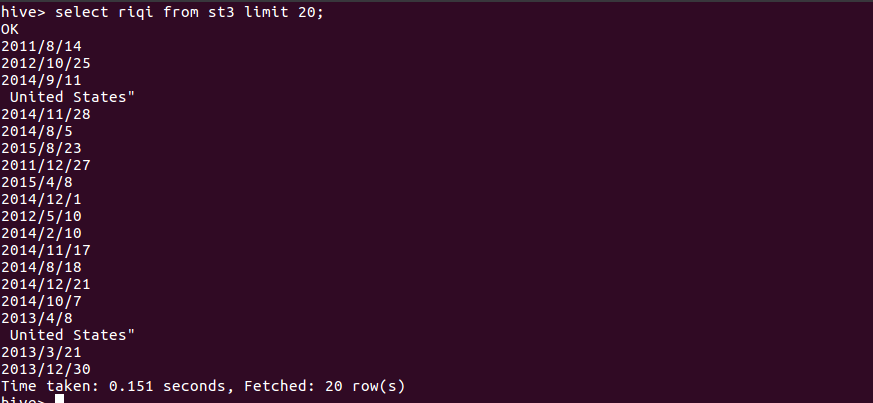
通过查询的到的评价时间可以的高票评价还是集中在2013、2014、2015,而该作品得奖时间是2015,说明评价有一定的参考性。
9、查询北京的用户评价的内容:

10、查询上海、的用户评价的内容:

11、查询广州的用户评价的内容:

通过9、10、11的分析得出一线城市用户的评价可看出高票评价观点鲜明,好评的居多,但是有部分不认同和反对,说明评价还有有一定的客观性的。
四、总结
分析结果:针对在豆瓣爬取的《三体》短评,通过城市、时间、评价星级等各方面进行分析得出:短评大部分还是比较好的,短评有好有坏,但好评居多,说明此作品具有一定的可读性和可观性。
通过本案例,了解了hdfs和hive数据仓库的大数据分析基本的原理和操作,在海量数据处理方面,hadoop在数据容纳和分析方面有着先天的优势,不过本案例的数据还不够多体现不出。hive仓库分析其实也有很多函数可以进行大数据的处理和分析,这里也进行了简单的数据库查询。总体有待完善。